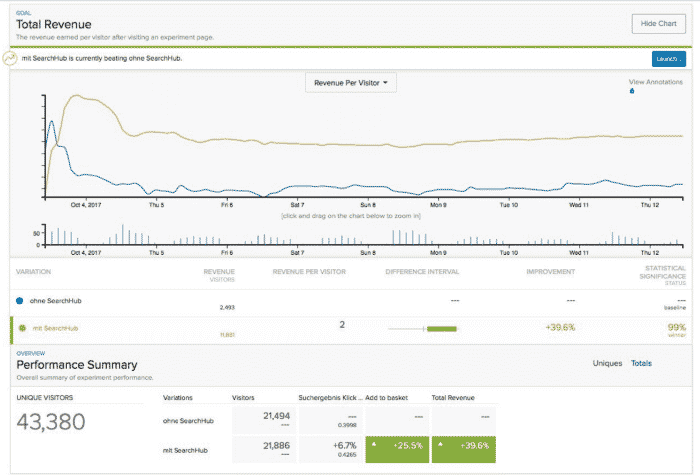
From Search Analytics to Search Insights – Part 1
Over the last 15 years, I have been in touch with tons of Search Analytics vendors and services regarding Information Retrieval. They all have one thing in common: to measure either the value or the problems of search systems. In fact, in recent years, almost every Search Vendor has jumped on board, adding some kind of Search Analytics functionality in the name of offering a more complete solution.
How to Make Search Analytics Insights Actionable
However, this doesn’t change the truth of the matter. To this day, almost all customers with whom I’ve worked over the years massively struggle to transform the data exposed by Search Analytics Systems into actionable insights that actively improve the search experiences they offer to their users. No matter how great the marketing slides or how lofty the false promises are, new tech can’t change that fact.
The reasons for this behavior are anything but obvious for most people. To this end, the following will shed some light on these problems and offer recommendations on how best to fix them.
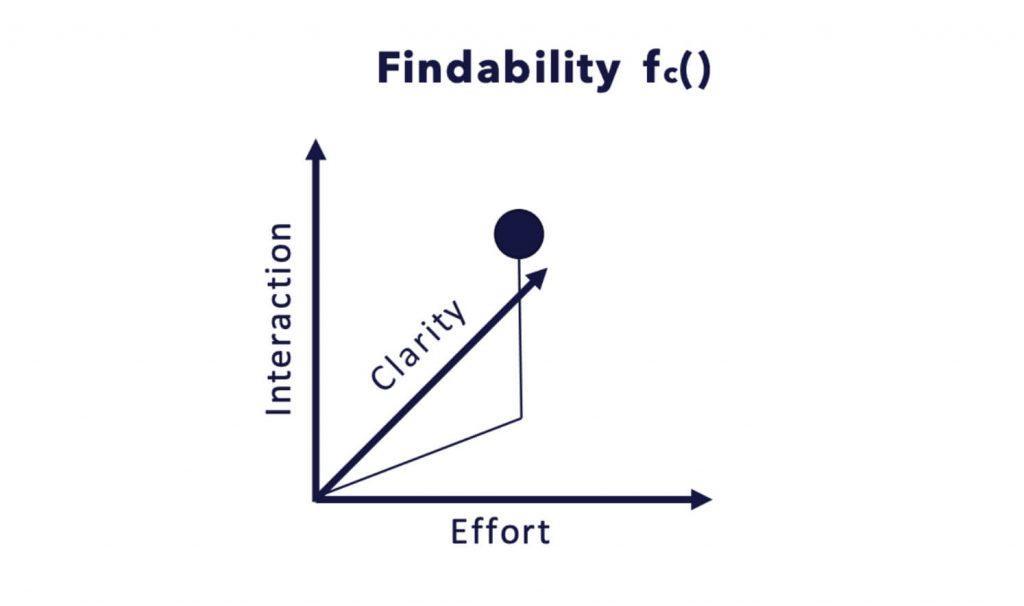
Query Classifier

First of all, regardless of the system you are using, the data that gets collected needs to be contextual, clean, and serve a well-defined purpose. I can’t overstate the significance of the maintenance and assurance of data accuracy and consistency over its entire lifecycle. It follows that if you or your system collect, aggregate, and analyze wrong data, the insights you might extract from it are very likely fundamentally wrong.
As always, some examples to help frame these thoughts in terms of your daily business context. The first one refers to zero-result searches and the second deals with Event-Attribution.
Zero-Results
It’s common knowledge among Search-Professionals that improving your zero-result-queries is the first thing to consider when optimizing search. But what they tend to forget to mention is that understanding the context of zero-result queries is equally essential.
There are quite a few different reasons for zero-result queries. However, not all of them are equally insightful when maintaining and optimizing your search system. So let’s dig a bit deeper into the following zero-result cases.
| Symptom | Reason | Insightfulness |
|---|---|---|
|
Continuous zero-result |
Search system generally lacks suitable content. Language gap between users and content or information |
Search system generally lacks suitable content. Language gap between users and content or information |
|
Temporary zero-result
|
The search system temporarily lacks suitable content. |
a) partially helpful – show related content. c) not very helpful |
Context is King
As you can see, the context (time, type, emitter) is quite essential to distinguish between different zero-result buckets. Context allows you to see the data in a way conducive to furthering search system optimization. We can use this information to unfold the zero-result searches and discover which offer real value acting as the baseline for continued improvements.
Human Rate
Almost a year ago, we started considering context in our Query Insights Module. One of our first steps was to introduce the so-called “human rate” of zero results. As a result, our customers can now distinguish between zero results from bots and those originating from real users. This level of differentiation lends more focus to their zero results optimization efforts.
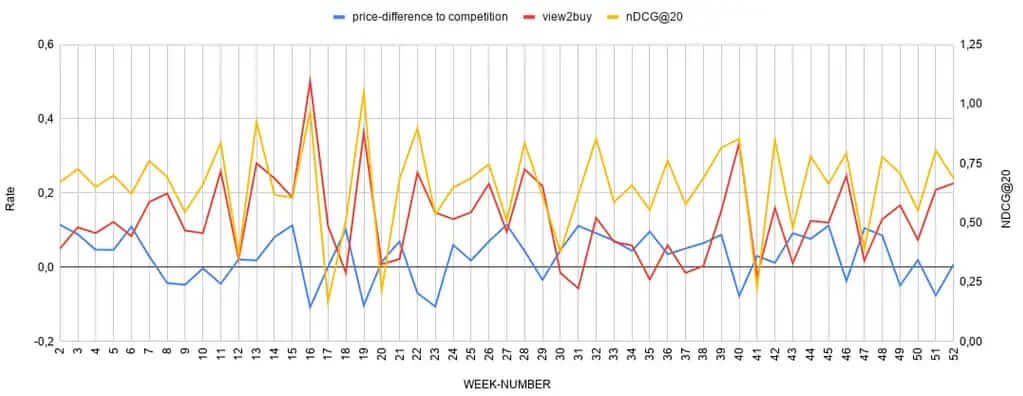
Let’s use a Sankey-diagram, with actual customer data (700.000 unique searches) to illustrate this better:
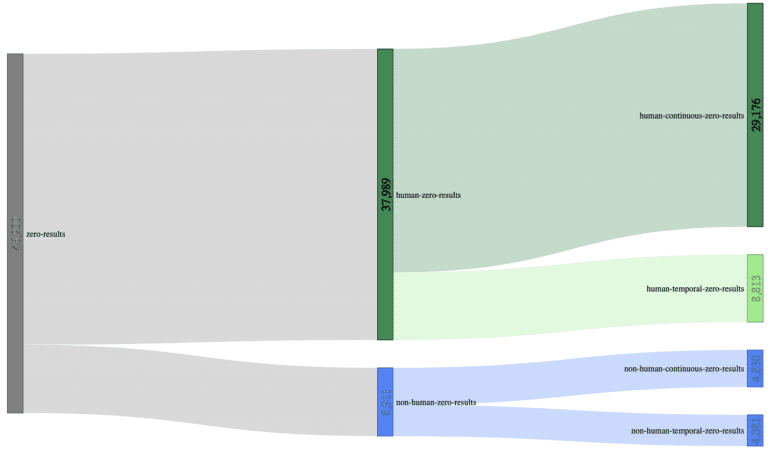
Using a sample size of 700.000 unique searches, we can decrease the initial 46.900 zero-results (6.7% zero-result-rate) to 29.176 zero-results made by humans (4.17% zero-result-rate); a reduction of almost 40% compared to the original sample size, just by adding context.
Session Exits
Another helpful dimension to add is session exits. Once you’ve distinguished between zero-results that lead to Session-Exits, from those ending successfully, what remains is a strong indicator for high-potential zero-result queries in desperate need of some optimization.
And don’t forget:
“it’s only honest to come to terms with the fact that not every zero-result is a dead-end for your users, and sometimes it is the best you can do.”
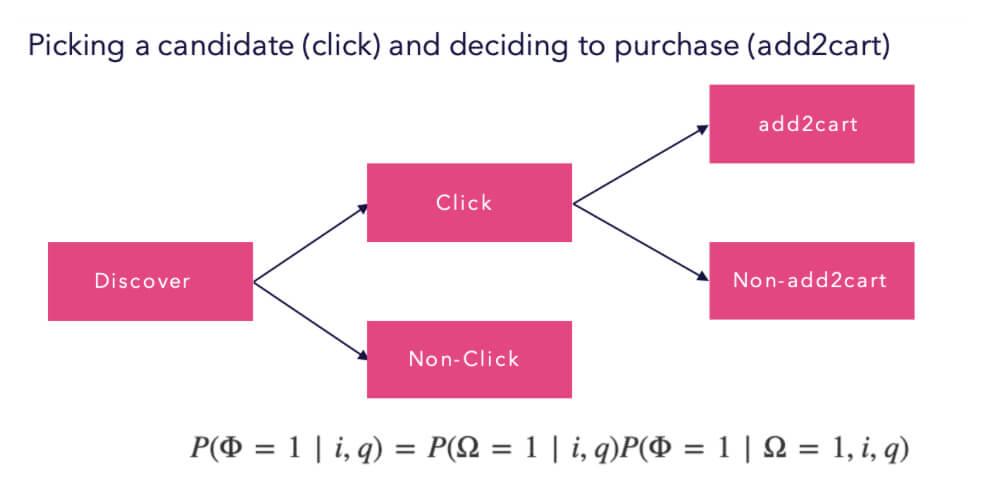
Event Attribution Model
Attribution modeling gets into some complex territory. Breaking down its fundamentals is easy enough, but understanding how they relate can make your head spin.
Let’s begin by first trying to understand what attribution modeling is.
Attribution modeling seeks to assign value to how a customer engaged with your site.
Site interactions are captured as events that, over time, describe how a customer got to where they are at present. In light of this explanation, attribution modeling aims to assign value to the touch-points or event-types on your site that influence a customer’s purchase.
For example: every route they take to engage with your site is a touch-point. Together, these touch-points are called a conversion path. It follows that the goal of understanding your conversion paths is to locate which elements or touch-points of your site strongly encourage purchases. Additionally, you may also gain insights into which components are weak, extraneous, or need re-working.
You can probably think of dozens of possible routes a customer might take in an e-commerce purchase scenario. Some customers click through content to the product and purchase quickly. Others comparison shop, read reviews, and make dozens of return visits before making a final decision.
Unfortunately, the same attribution models are often applied to Site Search Analytics as well. It is no wonder then that hundreds of customers have told me their Site-Search-Analytics is covered by Google, Adobe, Webtrekk, or other analytics tools. However, whereas this might be suitable for some high-level web analytics tasks, it turns problematic when researching the intersection of search and items related to site navigation and how these play a role in the overall integrity of your data.
Increase Understanding of User Journey Event Attribution
To increase the level of understanding around this topic, I usually do a couple of things to illustrate what I’m talking about.
Step 1: Make it Visual
To do this, I make a video of me browsing around their site just like a real user would using different functionalities like Site-Search, selecting Filters, clicking through the Navigation, triggering Redirects, clicking on Recommendations. At the same time, I ensure we can see how the Analytics System records the session and the underlying data that gets emitted.
Step 2: Make it Collaborative
Then, we collaboratively compare the recording and the aggregated data in the Analytics System.
Walk your team through practical scenarios. Let them have their own “Aha” Experience
What Creates an Event Attribution “Aha” Effect?
More often than not, this type of practical walk-through produces an immediate “Aha” experience for the customer when he discovers the following:
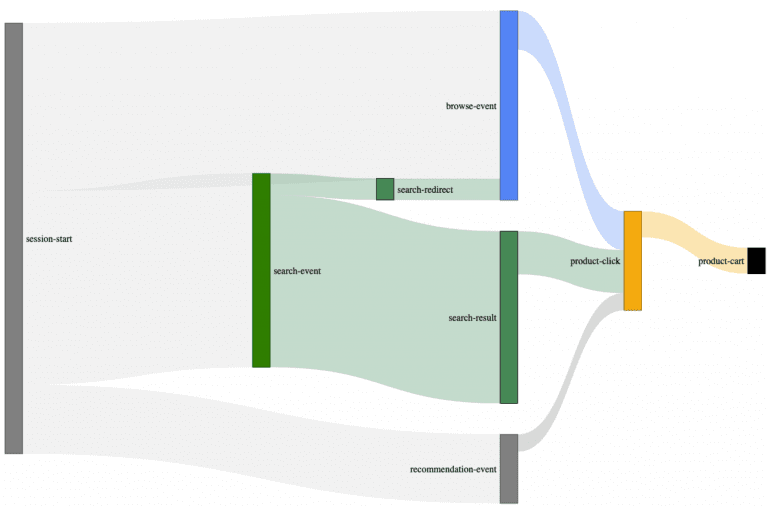
- search-related events like clicks, views, carts, orders might be incorrectly attributed to the initial search if multiple paths are used (i.e., redirects or recommendations)
- Search redirects are not attributed to a search event at all.
- Sometimes buy events and their related revenue are attributed to a search event, even when a correlation between buy and search events is missing.
How to Fix Event Attribution Errors
You can overcome these problems and remove most of the errors discussed but you will need to be lucky enough to have some tools.
Essential Ingredients for Mitigating Event Attribution Data Errors:
- Raw data
- A powerful Data-Analytics-System
- Most importantly: more profound attribution knowledge.
From here, it’s down to executing a couple of complex query statements on the raw data points.
The Most User-Friendly Solution
But fortunately, another more user-friendly solution exists. A more intelligent Frontend Tracking technology will identify and split user-sessions into smaller sub-sessions (trails) that contextualize the captured events.
That’s the main reason why we developed and open-sourced our search-Collector. It uses the so-called trail concept to contextualize the different stages in a user session, radically simplifying accurate feature-based-attribution efforts.
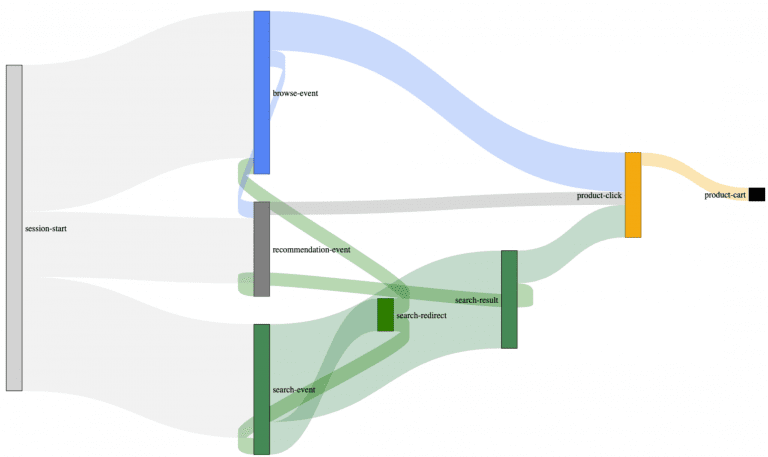
Example of an actual customer journey map built with our search-collector.
You may have already spotted these trail connections between the different event types. Most user sessions are what we call multi-modal trails. Multi-modal, in this case, describes the trail/path your users take to interact with your site’s features(search, navigation, recommendations) as a complex interwoven data matrix. As you can see from the Sankey diagram, by introducing trails (backward connections), we can successfully reconstruct the user’s paths.
Without these trails, it’s almost impossible to understand to which degree your auxiliary e-commerce systems: like your site-search, contribute to these complex scenarios.
This type of approach safeguards against overly focusing on irrelevant functionalities or missing other areas more in need of optimization.
Most of our customers already use this type of optimization filtering to establish more accurate, contextualized insight regarding site search.









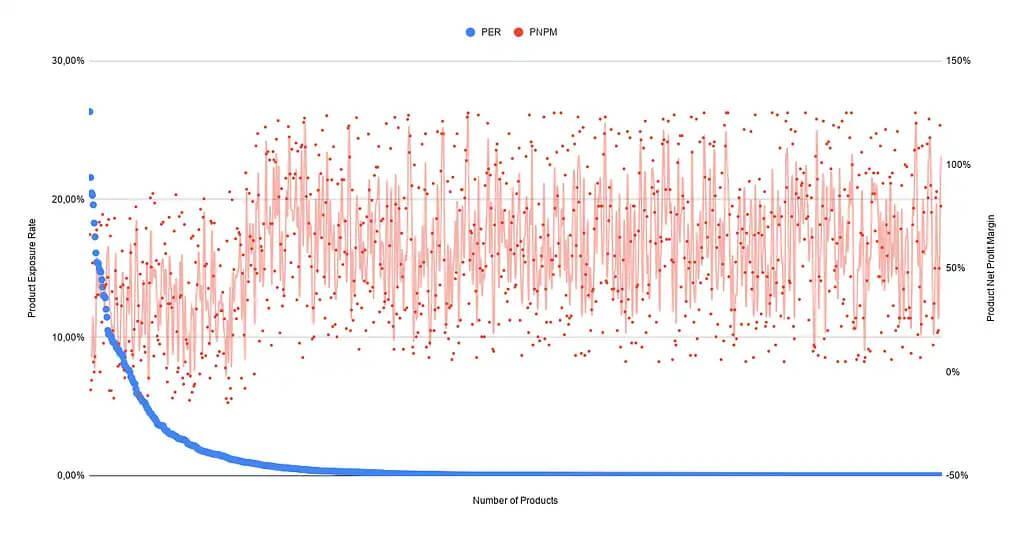


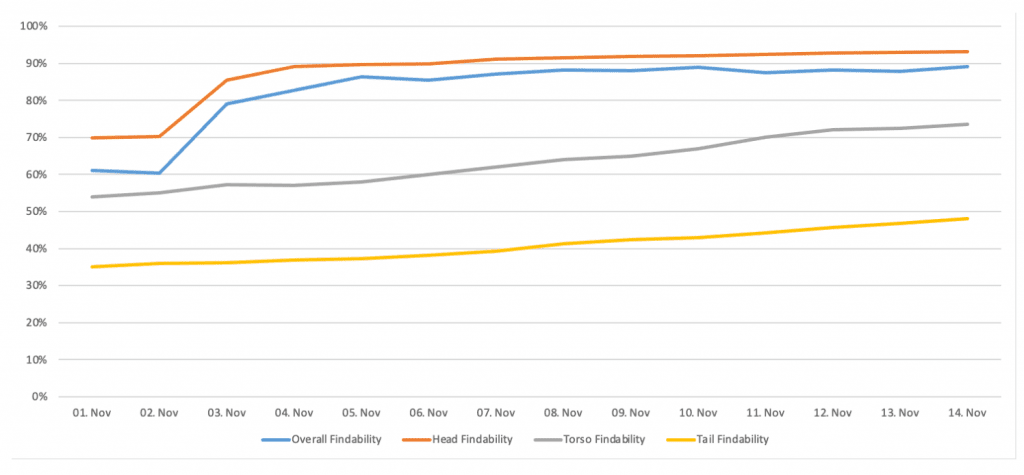

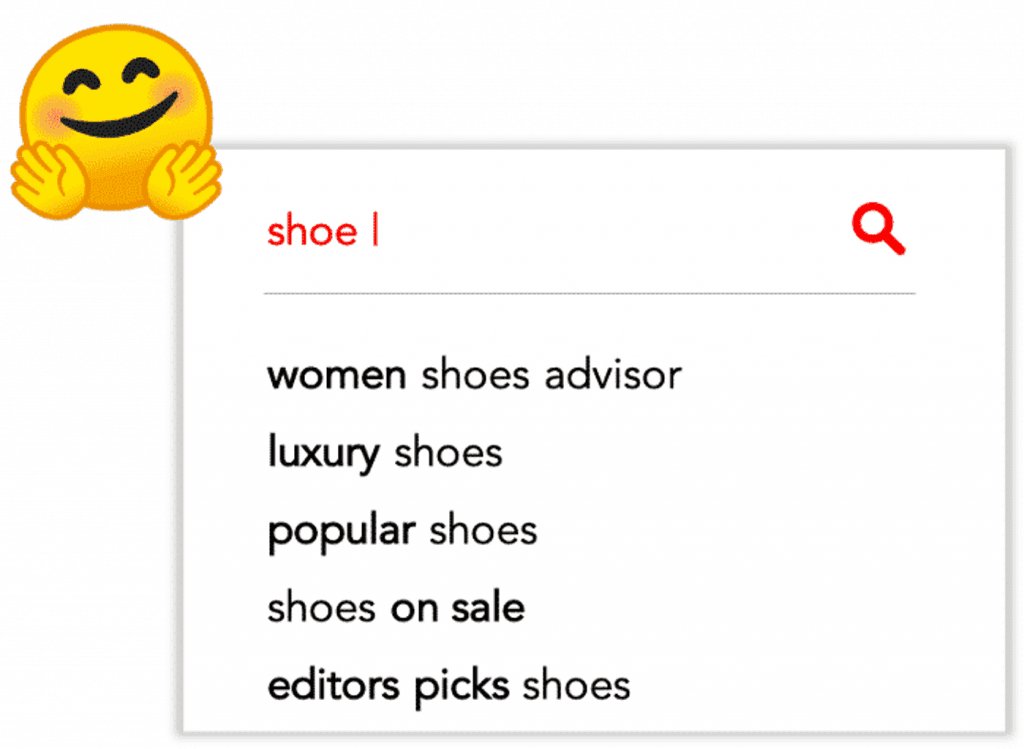
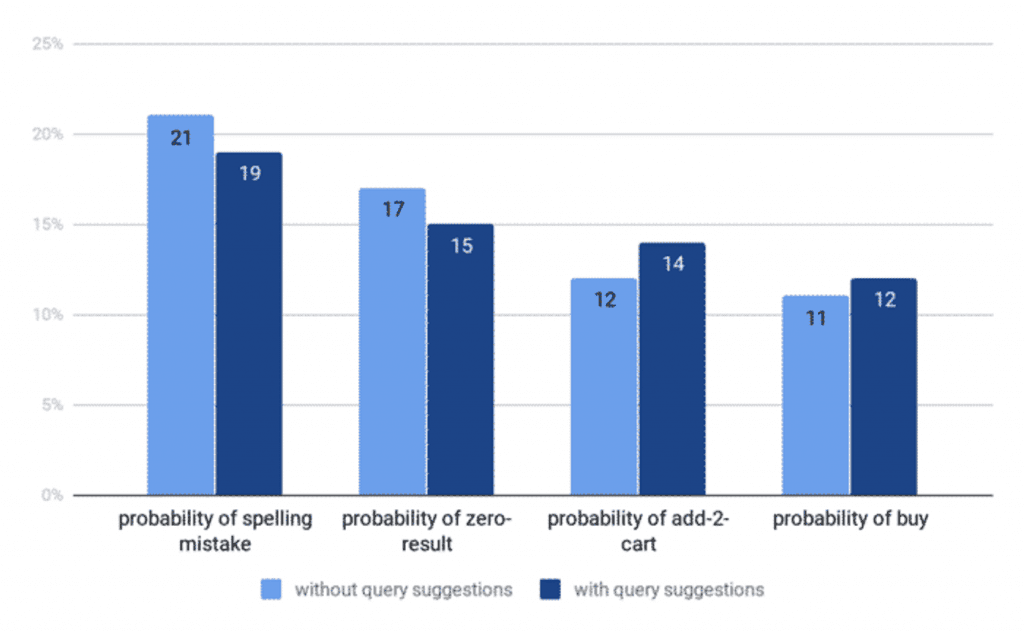

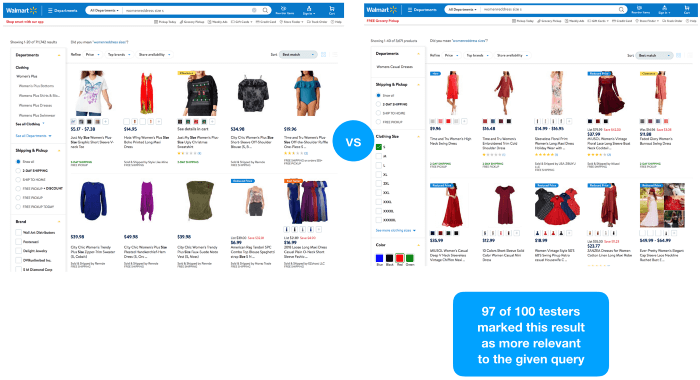
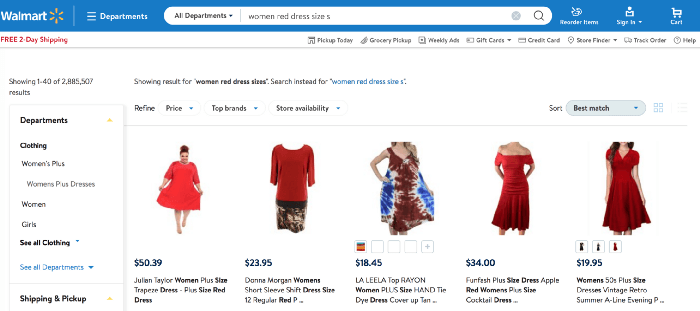
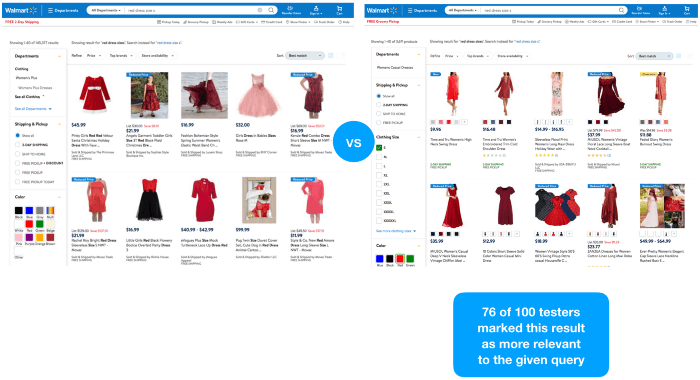
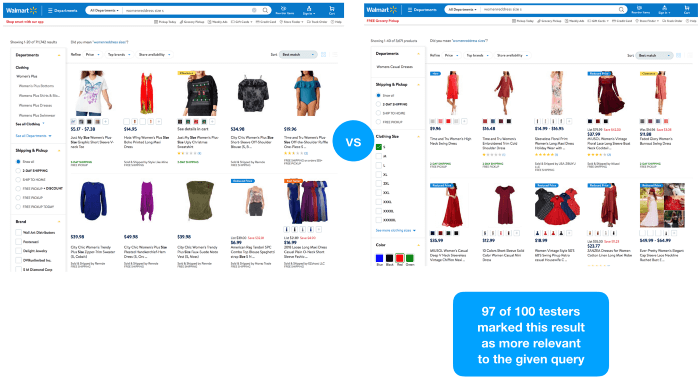
 we don’t have access to qualitative query performance data. But to test our hypothesis, we did a simple experiment with real-life users.
we don’t have access to qualitative query performance data. But to test our hypothesis, we did a simple experiment with real-life users.