Many businesses run an Elasticsearch/Kibana stack. Some use a SaaS-Service for Elastic — i.e., the AWS Amazon Elasticsearch Service; the Elastic in Azure Service from Microsoft; or the Elastic Cloud from Elastic itself. More commonly, Elasticsearch is hosted in a proprietary environment. Elastic and the community provide several deployment types and tips for various platforms and frameworks. In this article, I will show how to deploy Elasticsearch and Kibana in a Kubernetes Cluster using the Elastic Kubernetes Operator (cloud-on-k8s) without using Helm (helm / helm-charts). Overview of Elastic Deployment Types and Configuration:
The Motivation for Using the Elasticsearch-Operator:
What might be the motivation for using the Elasticsearch-Operator instead of using any other SaaS-Service?
The first argument is, possibly, the cost. The Elastic Cloud is round about 34% pricier than hosting your own Elasticsearch on the same instance in AWS. Furthermore, the AWS Amazon Elasticsearch Service is even 50% more expensive than the self-hosted version.
Another argument could be that you already have a Kubernernetes-Cluster running with the application which you would like to use Elasticsearch with. For this reason, you want to avoid spreading one application over multiple environments. So, you are looking to use Kubernetes as your go-to standard.
Occasionally, you may also have to build a special solution with many customizations that are not readily deployable with a SaaS provider.
An important argument for us was the hands-on experience hosting Elasticsearch, to give the best support to our customers.
Cluster Target Definition:
For the purposes of this post, I will use a sample cluster running on AWS. Remember to always include the following features:
- 6 node clusters (3 es-master, 3 es-data)
- master and data nodes are spread over 3 availability zones
- a plugin installed to snapshot data on S3
- dedicated nodes where only elastic services are running on
- affinities that not two elastic nodes from the same type are running on the same machine
Due to this article’s focus on how to use the Kubernetes Operator, we will not provide any details regarding necessary instances, the reason for creating different instance groups, or the reasons behind several pod anti affinities.
In our Kubernetes cluster, we have two additional Instance Groups for Elasticsearch: es-master and es-data where the nodes have special taints.
(In our example case, the instance groups are managed by kops. However, you can simply add the labels and taints to each node manually.)
The Following is an example of how a node of the es-master instance group looks like:
apiVersion: v1
kind: Node
metadata:
...
labels:
failure-domain.beta.kubernetes.io/zone: eu-north-1a
kops.k8s.io/instancegroup: es-master
kubernetes.io/hostname: ip-host.region.compute.internal
...
spec:
...
taints:
- effect: NoSchedule
key: es-node
value: master
As you may have noticed, there are three different labels:
- The failure-domain.beta.kubernetes.io/zone contains the information pertaining to the availability zone in which the instance is running.
- The kops.k8s.io/instancegroup contains the information in which instance the group resides. This will be important later to allow both master and data nodes to run on different hardware for performance optimization.
- The kubernetes.io/hostname acts as a constraint to ensure only one master node is running the specified instance.
Following is an example of an es-data instance with the appropriate label keys, and respective values:
apiVersion: v1
kind: Node
metadata:
...
labels:
failure-domain.beta.kubernetes.io/zone: eu-north-1a
kops.k8s.io/instancegroup: es-data
kubernetes.io/hostname: ip-host.region.compute.internal
...
spec:
...
taints:
- effect: NoSchedule
key: es-node
value: data
As you can see, the value of the es-node taint and the kops.k8s.io/instancegroup label differs. We will reference these values later to decide between data and master instances.
Now that we have illustrated our node structure, and you are better able to grasp our understanding of the Kubernetes and Elasticsearch cluster, we can begin installation of the Elasticsearch operator in Kubernetes.
Let’s Get Started:
First: install the Kubernetes Custom Resource Definitions, RBAC rules (if RBAC is activated in the cluster in question), and a StatefulSet for the elastic-operator pod. In our example case, we have RBAC activated and can make use of the all-in-one deployment file from Elastic for installation.
(Notice: If RBAC is not activated in your cluster, then remove line 2555 – 2791 and all service-account references in the file):
kubectl apply -f https://download.elastic.co/downloads/eck/1.2.1/all-in-one.yaml
This creates four main parts in our Kubernetes cluster to operate Elasticsearch:
- All necessary Custom Resource Definitions
- All RBAC Permissions which are needed
- A Namespace for the Operator (elastic-system)
- A StatefulSet for the Elastic Operator-Pod
Now perform kubectl logs -f on the operator’s pod and wait until the operator has successfully booted to verify the Installation. Respond to any errors, should an error message appear.
kubectl -n elastic-system logs -f statefulset.apps/elastic-operator
Once confirmed that the operator is up and running we can begin with our Elasticsearch cluster. We begin by creating an Elasticsearch resource with the following main structure (see here for full details):
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: blogpost # name of the elasticsearch cluster
namespace: blog
spec:
version: 7.7.0 # elasticsearch version to deploy
nodeSets: # nodes of the cluster
- name: master-zone-a
count: 1 # count how many nodes should be deployed
config: # specific configuration for this node type
node.master: true
...
- name: master-zone-b
- name: master-zone-c
- name: data-zone-a
- name: data-zone-b
- name: data-zone-c
In the listing above, you see how easily the name of the Elasticsearch cluster, as well as, the Elasticsearch version and different nodes that make up the cluster can be set. Our Elasticsearch structure is clearly specified in the array nodeSets, which we defined earlier. As a next step, we want to take a more in-depth look into a single nodeSet entry and see how this must look to adhere to our requirements:
- name: master-zone-a
count: 1
config:
node.master: true
node.data: false
node.ingest: false
node.attr.zone: eu-north-1a
cluster.routing.allocation.awareness.attributes: zone
podTemplate:
metadata:
labels:
component: elasticsearch
role: es-master
spec:
volumes:
- name: elasticsearch-data
emptyDir: {}
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions: # Kniff mit Liste
- key: kops.k8s.io/instancegroup
operator: In
values:
- es-master
- key: failure-domain.beta.kubernetes.io/zone
operator: In
values:
- eu-north-1a
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: role
operator: In
values:
- es-master
topologyKey: kubernetes.io/hostname
initContainers:
- name: sysctl
securityContext:
privileged: true
command: ['sh', '-c', 'sysctl -w vm.max_map_count=262144']
- name: install-plugins
command:
- sh
- -c
- |
bin/elasticsearch-plugin install -b repository-s3
tolerations:
- key: "es-node"
operator: "Equal"
value: "master"
effect: "NoSchedule"
containers:
- name: elasticsearch
resources:
requests:
memory: 1024Mi
limits:
memory: 1024Mi
The count key specifies, for example, how many pods Elasticsearch nodes should create with this node configuration for the cluster. The config object represents the untyped YAML configuration of Elasticsearch (Elasticsearch settings). The podTemplate contains a normal Kubernetes Pod template definition. Notice that here we are controlling the affinity and tolerations of our es-node to a special instance group and all pod affinities. In the initContainers section, we are handling kernel configurations and also the Elasticsearch repository-s3 plugin installation. One note on the nodeSelectorTerms: if you want to use the logical and condition instead of, or, you must place the conditions in a single matchExpressions array and not as two individual matchExpressions. For me, this was not clearly described in the Kubernetes documentation.
Once we have created our Elasticsearch deployment, we must create a Kibana deployment. This can be done with the Kibana resource. The following is a sample of this definition:
apiVersion: kibana.k8s.elastic.co/v1
kind: Kibana
metadata:
name: blogpost
namespace: blog
spec:
version: 7.7.0
count: 1
elasticsearchRef:
name: blogpost
podTemplate:
metadata:
labels:
component: kibana
Notice that the elasticsearchRef object must refer to our Elasticsearch to be connected with it.
After we have created all necessary deployment files, we can begin deploying them. In our case, I put them in one big file called elasticseach-blog-example.yaml, you can find a complete list of the deployment files at the end of this blogpost.
kubectl apply -f elasticsearch-blog-example.yaml
After deploying the deployment file you should have a new namespace with the following pods, services and secrets (Of course with more resources, however this is not relevant for our initial overview):
(⎈ |blog.k8s.local:blog)➜ ~ kubectl get pods,services,secrets
NAME READY STATUS RESTARTS AGE
pod/blogpost-es-data-zone-a-0 1/1 Running 0 2m
pod/blogpost-es-data-zone-b-0 1/1 Running 0 2m
pod/blogpost-es-data-zone-c-0 1/1 Running 0 2m
pod/blogpost-es-master-zone-a-0 1/1 Running 0 2m
pod/blogpost-es-master-zone-b-0 1/1 Running 0 2m
pod/blogpost-es-master-zone-c-0 1/1 Running 0 2m
pod/blogpost-kb-66d5cb8b65-j4vl4 1/1 Running 0 2m
NAME TYPE CLUSTER-IP PORT(S) AGE
service/blogpost-es-data-zone-a ClusterIP None <none> 2m
service/blogpost-es-data-zone-b ClusterIP None <none> 2m
service/blogpost-es-data-zone-c ClusterIP None <none> 2m
service/blogpost-es-http ClusterIP 100.68.76.86 9200/TCP 2m
service/blogpost-es-master-zone-a ClusterIP None <none> 2m
service/blogpost-es-master-zone-b ClusterIP None <none> 2m
service/blogpost-es-master-zone-c ClusterIP None <none> 2m
service/blogpost-es-transport ClusterIP None 9300/TCP 2m
service/blogpost-kb-http ClusterIP 100.67.39.183 5601/TCP 2m
NAME DATA AGE
secret/default-token-thnvr 3 2m
secret/blogpost-es-data-zone-a-es-config 1 2m
secret/blogpost-es-data-zone-b-es-config 1 2m
secret/blogpost-es-elastic-user 1 2m
secret/blogpost-es-http-ca-internal 2 2m
secret/blogpost-es-http-certs-internal 3 2m
secret/blogpost-es-http-certs-public 2 2m
secret/blogpost-es-internal-users 2 2m
secret/blogpost-es-master-zone-a-es-config 1 2m
secret/blogpost-es-master-zone-b-es-config 1 2m
secret/blogpost-es-master-zone-c-es-config 1 2m
secret/blogpost-es-remote-ca 1 2m
secret/blogpost-es-transport-ca-internal 2 2m
secret/blogpost-es-transport-certificates 11 2m
secret/blogpost-es-transport-certs-public 1 2m
secret/blogpost-es-xpack-file-realm 3 2m
secret/blogpost-kb-config 2 2m
secret/blogpost-kb-es-ca 2 2m
secret/blogpost-kb-http-ca-internal 2 2m
secret/blogpost-kb-http-certs-internal 3 2m
secret/blogpost-kb-http-certs-public 2 2m
secret/blogpost-kibana-user 1 2mm
As you may have noticed, I removed the column EXTERNAL from the services and the column TYPE from the secrets. I did this due to the formatting in the code block.
Once Elasticsearch and Kibana have been deployed we must test the setup by making an HTTP get request with the Kibana-Dev-Tools. First, we have to get the elastic user and password which the elasticsearch-operator generated for us. It’s saved in the Kubernetes Secret -es-elastic-user in our case blogpost-es-elastic-user.
(⎈ |blog.k8s.local:blog)➜ ~ kubectl get secret/blogpost-es-elastic-user -o yaml
apiVersion: v1
data:
elastic: aW8zQWhuYWUyaWVXOEVpM2FlWmFoc2hp
kind: Secret
metadata:
creationTimestamp: "2020-10-21T08:36:35Z"
labels:
common.k8s.elastic.co/type: elasticsearch
eck.k8s.elastic.co/credentials: "true"
elasticsearch.k8s.elastic.co/cluster-name: blogpost
name: blogpost-es-elastic-user
namespace: blog
ownerReferences:
- apiVersion: elasticsearch.k8s.elastic.co/v1
blockOwnerDeletion: true
controller: true
kind: Elasticsearch
name: blogpost
uid: 7f236c45-a63e-11ea-818d-0e482d3cc584
resourceVersion: "701864"
selfLink: /api/v1/namespaces/blog/secrets/blogpost-es-elastic-user
uid: 802ba8e6-a63e-11ea-818d-0e482d3cc584
type: Opaque
The user of our cluster is the key, located under data. In our case, elastic. The password is the corresponding value of this key. It’s Base64 encoded, so we have to decode it:
(⎈ |blog.k8s.local:blog)➜ ~ echo -n "aW8zQWhuYWUyaWVXOEVpM2FlWmFoc2hp" | base64 -d
io3Ahnae2ieW8Ei3aeZahshi
Once we have the password we can port-forward the blogpost-kb-http service on port 5601 (Standard Kibana Port) to our localhost and access it with our web-browser at https://localhost:5601:
(⎈ |blog.k8s.local:blog)➜ ~ kubectl port-forward service/blogpost-kb-http 5601
Forwarding from 127.0.0.1:5601 -> 5601
Forwarding from [::1]:5601 -> 5601
Elasticsearch Kibana Login Screen
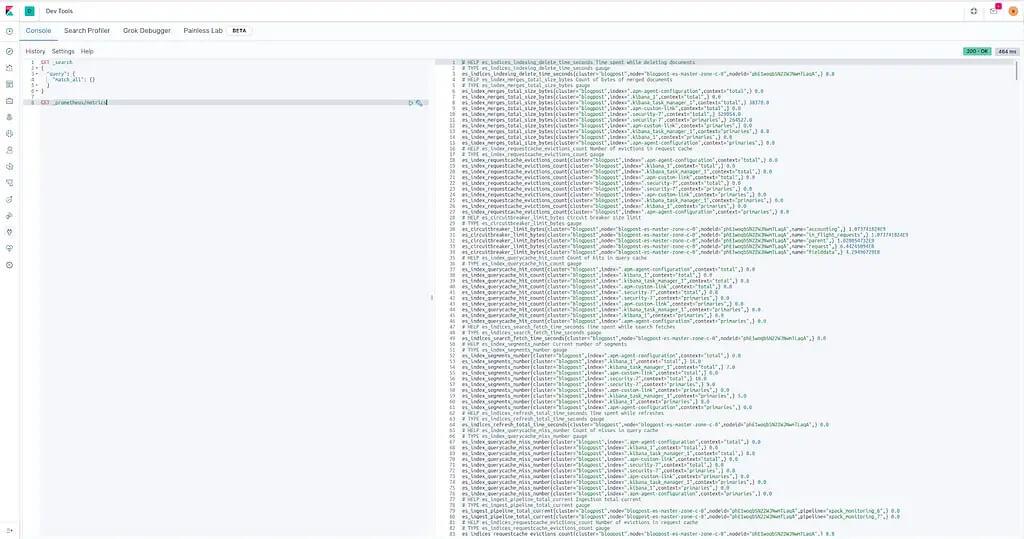
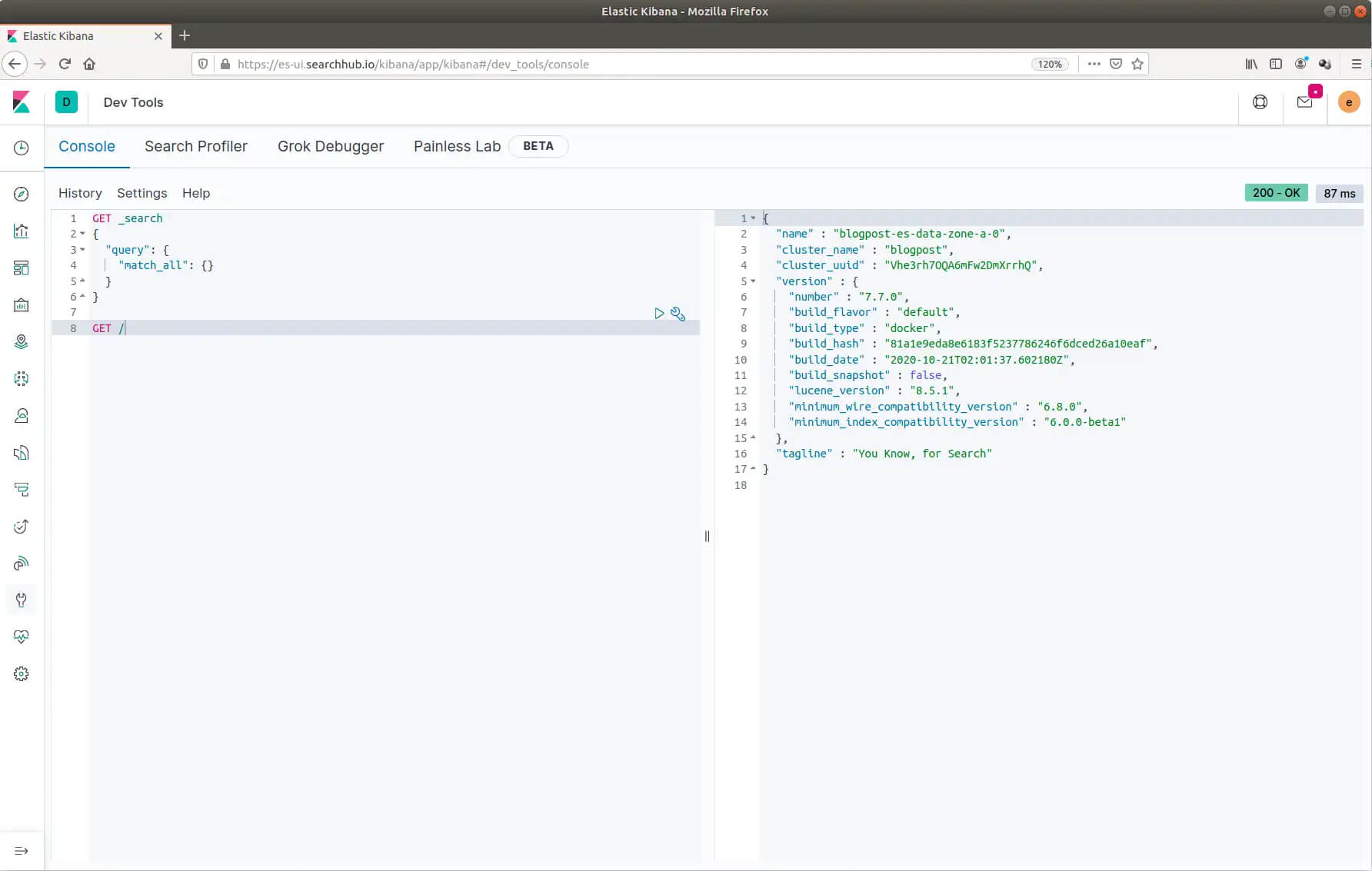
After logging in, navigate on the left side to the Kibana Dev Tools. Now perform a GET / request, like in the picture below:
Getting started with your Elasticsearch Deployment inside the Kibana Dev Tools
Summary
We now have an overview of all officially supported methods of installing/operating Elasticsearch. Additionally, we successfully set up a cluster which met the following requirements:
- 6 node clusters (3 es-master, 3 es-data)
- we spread master and data nodes over 3 availability zones
- installed a plugin to snapshot data on S3
- has dedicated nodes in which only elastic services are running
- upholds the constraints that no two elastic nodes of the same type are running on the same machine
Thanks for reading!
Full List of Deployment Files
apiVersion: v1
kind: Namespace
metadata:
name: blog
---
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: blogpost
namespace: blog
spec:
version: 7.7.0
nodeSets:
- name: master-zone-a
count: 1
config:
node.master: true
node.data: false
node.ingest: false
node.attr.zone: eu-north-1a
cluster.routing.allocation.awareness.attributes: zone
podTemplate:
metadata:
labels:
component: elasticsearch
role: es-master
spec:
volumes:
- name: elasticsearch-data
emptyDir: {}
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kops.k8s.io/instancegroup
operator: In
values:
- es-master
- key: failure-domain.beta.kubernetes.io/zone
operator: In
values:
- eu-north-1a
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: role
operator: In
values:
- es-master
topologyKey: kubernetes.io/hostname
initContainers:
- name: sysctl
securityContext:
privileged: true
command: ['sh', '-c', 'sysctl -w vm.max_map_count=262144']
- name: install-plugins
command:
- sh
- -c
- |
bin/elasticsearch-plugin install -b repository-s3
tolerations:
- key: "es-node"
operator: "Equal"
value: "master"
effect: "NoSchedule"
containers:
- name: elasticsearch
- name: master-zone-b
count: 1
config:
node.master: true
node.data: false
node.ingest: false
node.attr.zone: eu-north-1b
cluster.routing.allocation.awareness.attributes: zone
podTemplate:
metadata:
labels:
component: elasticsearch
role: es-master
spec:
volumes:
- name: elasticsearch-data
emptyDir: {}
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kops.k8s.io/instancegroup
operator: In
values:
- es-master
- key: failure-domain.beta.kubernetes.io/zone
operator: In
values:
- eu-north-1b
initContainers:
- name: sysctl
securityContext:
privileged: true
command: ['sh', '-c', 'sysctl -w vm.max_map_count=262144']
- name: install-plugins
command:
- sh
- -c
- |
bin/elasticsearch-plugin install -b repository-s3
tolerations:
- key: "es-node"
operator: "Equal"
value: "master"
effect: "NoSchedule"
containers:
- name: elasticsearch
- name: master-zone-c
count: 1
config:
node.master: true
node.data: false
node.ingest: false
node.attr.zone: eu-north-1c
cluster.routing.allocation.awareness.attributes: zone
podTemplate:
metadata:
labels:
component: elasticsearch
role: es-master
spec:
volumes:
- name: elasticsearch-data
emptyDir: {}
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kops.k8s.io/instancegroup
operator: In
values:
- es-master
- key: failure-domain.beta.kubernetes.io/zone
operator: In
values:
- eu-north-1c
initContainers:
- name: sysctl
securityContext:
privileged: true
command: ['sh', '-c', 'sysctl -w vm.max_map_count=262144']
- name: install-plugins
command:
- sh
- -c
- |
bin/elasticsearch-plugin install -b repository-s3
tolerations:
- key: "es-node"
operator: "Equal"
value: "master"
effect: "NoSchedule"
containers:
- name: elasticsearch
- name: data-zone-a
count: 1
config:
node.master: false
node.data: true
node.ingest: true
node.attr.zone: eu-north-1a
cluster.routing.allocation.awareness.attributes: zone
podTemplate:
metadata:
labels:
component: elasticsearch
role: es-worker
spec:
volumes:
- name: elasticsearch-data
emptyDir: {}
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kops.k8s.io/instancegroup
operator: In
values:
- es-data
- key: failure-domain.beta.kubernetes.io/zone
operator: In
values:
- eu-north-1a
initContainers:
- name: sysctl
securityContext:
privileged: true
command: ['sh', '-c', 'sysctl -w vm.max_map_count=262144']
- name: install-plugins
command:
- sh
- -c
- |
bin/elasticsearch-plugin install -b repository-s3
tolerations:
- key: "es-node"
operator: "Equal"
value: "data"
effect: "NoSchedule"
containers:
- name: elasticsearch
- name: data-zone-b
count: 1
config:
node.master: false
node.data: true
node.ingest: true
node.attr.zone: eu-north-1b
cluster.routing.allocation.awareness.attributes: zone
podTemplate:
metadata:
labels:
component: elasticsearch
role: es-worker
spec:
volumes:
- name: elasticsearch-data
emptyDir: {}
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kops.k8s.io/instancegroup
operator: In
values:
- es-data
- key: failure-domain.beta.kubernetes.io/zone
operator: In
values:
- eu-north-1b
initContainers:
- name: sysctl
securityContext:
privileged: true
command: ['sh', '-c', 'sysctl -w vm.max_map_count=262144']
- name: install-plugins
command:
- sh
- -c
- |
bin/elasticsearch-plugin install -b repository-s3
tolerations:
- key: "es-node"
operator: "Equal"
value: "data"
effect: "NoSchedule"
containers:
- name: elasticsearch
- name: data-zone-c
count: 1
config:
node.master: false
node.data: true
node.ingest: true
node.attr.zone: eu-north-1c
cluster.routing.allocation.awareness.attributes: zone
podTemplate:
metadata:
labels:
component: elasticsearch
role: es-worker
spec:
volumes:
- name: elasticsearch-data
emptyDir: {}
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kops.k8s.io/instancegroup
operator: In
values:
- es-data
- key: failure-domain.beta.kubernetes.io/zone
operator: In
values:
- eu-north-1c
initContainers:
- name: sysctl
securityContext:
privileged: true
command: ['sh', '-c', 'sysctl -w vm.max_map_count=262144']
- name: install-plugins
command:
- sh
- -c
- |
bin/elasticsearch-plugin install -b repository-s3
tolerations:
- key: "es-node"
operator: "Equal"
value: "data"
effect: "NoSchedule"
containers:
- name: elasticsearch
---
apiVersion: kibana.k8s.elastic.co/v1
kind: Kibana
metadata:
name: ui
namespace: ui
spec:
version: 7.7.0
count: 1
elasticsearchRef:
name: ui
podTemplate:
metadata:
labels:
component: kibana