A challenging and highly successful year is drawing to a close. We want to take a moment to pause and thank you for the trust you have placed in us and for everything we have achieved together over the past year. Looking back, 2025 was a year of milestones. Our expertise in E-commerce Search Optimization has grown stronger than ever. Our commitment extends beyond software. Here, we offer you an insight into our greatest successes, our ambitious Vision 2026, and how we live up to our responsibility in the local community.
Gabriel Bauer
2025 Review: Shared Milestones in E-commerce Search Optimization
Your partnership drives our innovations, and your success is our greatest motivation. Thanks to you, we took important steps toward a more human-centric search experience and significantly advanced the field of E-commerce Search Optimization in 2025:
NeuralInfusion Launch: We are excited about the first Beta installations of our groundbreaking NeuralInfusion technology [Link zur NeuralInfusion™ Produktseite]. This lays the foundation for a new age of semantic search intelligence and increased conversion rates, redefining modern E-commerce Search Optimization.
Successful Rollout of Query Suggestions: We saw great success with the rollout of our Query Suggestions feature [Link zur Query-Suggestions/SmartSuggest Produktseite]. This feature delivers more precise suggestions, helping you minimize search abandonment (zero-result pages) and boost revenue.
Community Growth: It was a pleasure connecting with many of you in our newly founded searchHub Community Group on LinkedIn. We appreciate your valuable feedback, which directly informs our product roadmap.
Vision 2026: The Technology that Understands Your Customers’ Needs
Technology should adapt to the human user—not the other way around. This is the foundation of our work and our central objective for the coming year.
For 2026, we are pursuing a clear goal: we want to further improve the connection between user intent and the digital result. Our vision is to evolve our AI to capture the actual needs of people behind search queries even more precisely. We are committed to making sure search doesn’t just find, but truly understands, setting a new standard for E-commerce Search Optimization.
Responsibility in Pforzheim/Enzkreis: More Than Just Software
This holiday season, it is especially important to us to extend the influence of our software company beyond the digital world and strengthen healthy social coexistence right here in our region.
Instead of traditional gifts, this year we are supporting the counseling and prevention work of the non-profit organization amwerden e.V.
We are proud to actively support them in developing a prevention program for primary and secondary schools in the Pforzheim and Enzkreis region. Our common goal is to close the gap between simple media education and individual psychosocial services.
Our Media Competency Curriculum:
Together, we are developing a media competency curriculum that:
Students: Teaches a healthy relationship with digital media.
Teachers and Parents: Offers concrete assistance and guidance—both for school and private life.
Connects Generations: The overarching goal is to foster cooperation between generations and sustainably strengthen the mental and cognitive development of children and adolescents.
Together and Leading the Way in the New Year
We look forward to continuing our partnership with you. In the new year, we remain committed to offering you a leading E-commerce Search Optimization solution while continuing to exert a positive influence on the lives of those around us.
We wish you and your family that we all find time in 2026 to be positive role models in our own spheres of influence—whether at work, in our communities, or at home.
Why Vocabulary Mismatch In Ecommerce Site Search Happens
At a high level, E-commerce Search faces two fundamental challenges. The first is the recall challenge: ensuring that all products potentially engaging to a given search intent are retrieved. The second is the precision challenge: ranking and organizing these products in a way that maximizes user engagement. This blog post will focus exclusively on the first challenge, a core problem in ecommerce site search optimization, which we refer to as the vocabulary mismatch.
When shoppers search for “sneakers” but your catalog only lists “athletic shoes”, or when they type “shirt dress” and instead get “dress shirts”, or when they look for “red valentino dress” but only find “valentino red dresses”, search often fails to meet their expectations.
These are just a few examples of one of the most persistent challenges in information retrieval: the language gap (also called vocabulary mismatch), the difference between how customers describe products and how sellers catalog them. It’s a longstanding problem in search, but in e-commerce its consequences are especially tangible:
Trust erodes when the site search solution “doesn’t understand” the shopper.
Bridging this gap is therefore a critical opportunity to improve both customer experience and business performance in modern e-commerce platforms.
Vocabulary mismatch in e-commerce has many, often overlapping, causes. Some are obvious, others more subtle, but all contribute to the gap between how shoppers express their intent and product descriptions when it comes to exact matching of words or tokens. A more technical explanation follows.
One of the fundamental technical challenges is token mismatch, where morphological, syntactic, and lexical differences across languages prevent direct alignment between query and document terms. This problem is further compounded by inconsistencies in tokenization schemes, variations in transliteration practices, and the scarcity of high-quality parallel corpora particularly for low-resource languages.
Compound Words
Different forms of product-specific compounds: “headphones” vs. “head phones”.
Inflections & Lemmas
Natural language variations: “shoe” vs. “shoes”, “run” vs. “running”. Search systems must handle morphology.
Misspellings & Typos
Common in short queries, they create artificial mismatches that obscure otherwise clear intent.
Syntactic differences:
Conceptual Confusions
Improving query understanding is key, as queries may express concepts rather than single terms, where word order matters: “shirt dress” vs. “dress shirt”, “table grill” vs. “grill table”.
Lexical gaps:
Synonyms & Variants
Classic cases like “sofa” vs. “couch” or “TV” vs. “television”. Without handling, these fragment search results.
Jargon vs. Everyday Language
Sellers use technical or marketing terms (“respirator mask”), while customers use plain words (“face mask”) (playstation 5 vs. PS5). New brand, color, or product-line names appear constantly.
Regional & Multilingual Differences
Geographic variations like “sneakers” (US) vs. “trainers” (UK), or “nappy” vs. “diaper”.
Evolving Language
Trends, slang, and branded phrases shift faster than catalogs: “quiet luxury”, “cottagecore”, “bespoke”.
Current State of Vocabulary Mismatch in Ecommerce
We found a considerable amount of literature addressing vocabulary mismatch in e-commerce. However, most of it concentrates on complementary strategies for mitigating the problem rather than on measuring it. Still, the most common approaches are worth noting: query-side, document-side, and semantic search techniques generally provide more precision. Embedding- and vector-based retrieval methods on the other hand, are typically looser and less exact, favoring broader coverage over strict matching.
Query-side Optimization Techniques
Query Rewriting & Expansion: transform queries into more effective versions. Example: “pregnancy dress” → “maternity dress.”
Conceptual Search / Semantic Search: Our approach to implementing semantic search interprets the underlying user intent to map queries to the product space.
Spell Correction: crucial since typos amplify mismatch.
Document-side Optimization Techniques
Document Expansion: enrich product metadata with predicted synonyms or missing tokens. Walmart’s Doc2Token (2024) helped reduce null search results in production. Attribute Normalization: standardize terms like “XL” vs. “extra large” vs. “plus size.”
Null-search rate (queries with few or zero results) and recall for “low-recall / short” queries + query expansion with BERT-based methods. sigir-ecom.github.io
Null searches were reduced by ~3.7% after applying PSimBERT query expansion. Recall@30 improved by ~11% over baseline for low-recall queries. sigir-ecom.github.io
Addressing Vocabulary Gap (Flipkart / IIT Kharagpur, 2019)
Fraction of queries suffering from vocabulary gap; experiments on rewriting. cse.iitkgp.ac.in
They observe that “a significant fraction of queries” suffer from low overlap between query terms and product catalog specifications. While they don’t always put a precise “% of queries” number for all datasets, they show substantial performance degradation for these queries, and that rewriting helps. cse.iitkgp.ac.in
Doc2Token (Walmart, 2024)
How many “missing” tokens are needed in product metadata; what fraction of queries target tokens not present in descriptions. arXiv
The paper describes “novel tokens” (i.e. tokens in queries that aren’t in the product document metadata). They found that document expansion paying attention to those “novel” terms improves search recall & reduces zero-result searches. The exact fraction of missing tokens varies by category, but it’s large enough that, in production A/B tests, the change was statistically significant. arXiv
Graph-based Multilingual Retrieval (Lu et al., 2021)
Multilingual and cross-locale query vs product description mismatch; measure improvement by injecting neighbor queries into product representations. ACL Anthology
They report: “outperforms state-of-the-art baselines by more than 25%” in certain multilingual retrieval tasks (across heavy-tail / rare queries) when using their graph convolution networks. This indicates that the vocabulary gap (especially across languages or speech/colloquial vs. catalog language) is large enough that richer models give big gains. ACL Anthology
But how big is the vocabulary gap?
While many efforts focus on bridging the vocabulary gap with the latest technologies, we found that actually quantifying vocabulary mismatch is far from simple. Its magnitude varies significantly depending on factors such as the domain, catalog size, language, and metadata quality. In fact, we identified only a few studies (cited above) that report meaningful metrics or proxy KPIs. These can indeed serve as useful signals for diagnosing the severity of the problem and for prioritizing improvements. However, they still fall short of capturing the full scale and subtle nuances of the mismatch.
To make well-founded and impactful product development decisions, we need a deep understanding of the vocabulary mismatch problem, its scale as well as its nuances. This is why we invested significant time and resources into conducting a large-scale study on vocabulary mismatch in e-commerce.
Large-Scale Study of Vocabulary Mismatch in E-commerce
Since vocabulary mismatch arises from many sources, our first step was to isolate and measure the individual impact of these causes. We analyzed more than 70M unique products and more than 500M unique queries, filtered according to our top 10 languages (EN,DE,FR,IT,ES,NL,PT,DA,CS,SV).
We initially planned a cross-language meta-analysis, but the analysis phase showed substantial inter-language differences and effect sizes, making pooling inappropriate. We’re therefore analyzing each language separately. We’ll begin with German, since it’s our largest dataset, and integrate the other languages in a later phase. The German dataset consists of 110 million unique queries and 28 million unique products with associated metadata. After tokenizing by spaces and hyphens (where the split yields valid, known tokens), we obtain 132,031,563 unique query tokens and 10,742,336 unique product tokens to work with.
Impact of Misspellings:
Since the primary goal of this analysis is to measure vocabulary mismatch, it is essential to begin by defining what we mean by vocabulary. In this context, vocabulary refers to the set of valid and actually used words or tokens across different languages. Because auto-correction, the accurate handling of misspelled tokens and phrases, is one of the most frequently applied (and most sophisticated) strategies in searchHub, it is important to first assess the extent of misspellings and exclude them. According to our definition, misspelled terms do not belong to the vocabulary and should therefore be filtered out while quantifying the vocabulary mismatch problem.
shared-token-ratio between search queries and product data across with and without misspellings
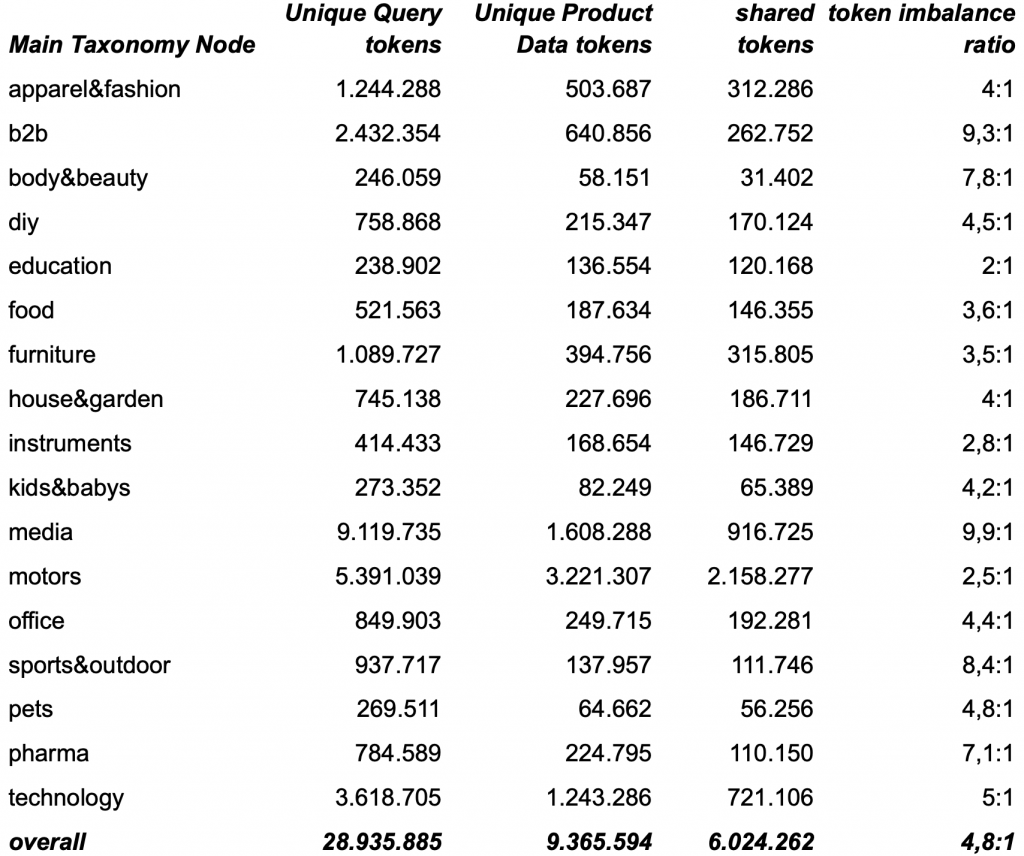
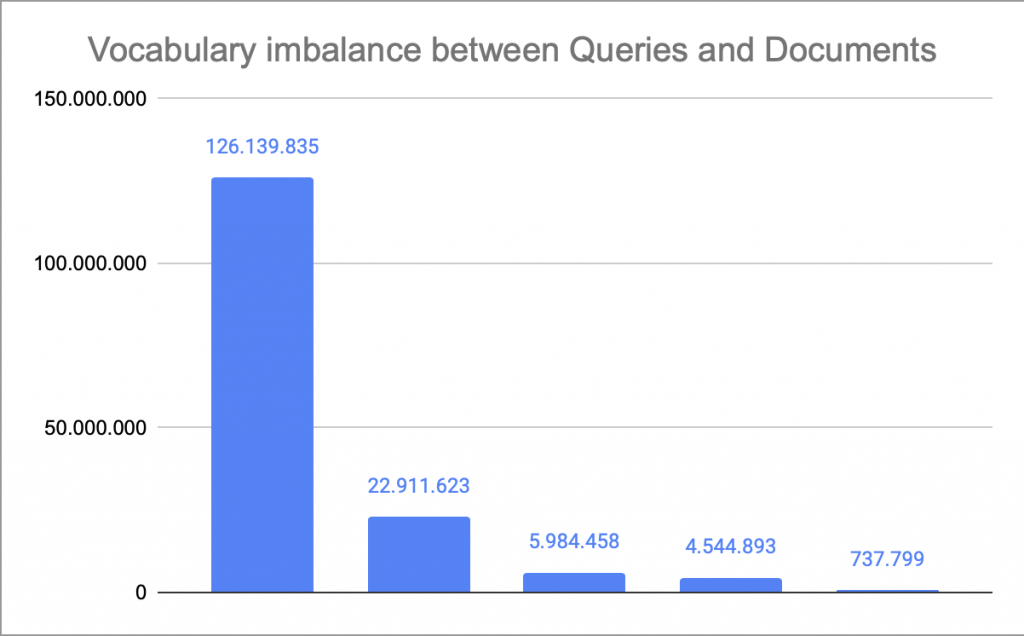
Filtering out misspellings reduces the amount of unique query & product-data tokens significantly (almost 7x). After excluding them, we first started with some simple statistics taking our Taxonomy-Nodes into account that revealed that the user query corpus contains on average 4.8x more unique valid tokens than the product corpus. As an important sidenote we should point out that the token imbalance ratio significantly varies across the taxonomy nodes.
shared-tokens and token imbalance-ratio between search queries and product data across our main taxonomy nodes
It’s important to note that both raw data sets (search queries and product-data) are messy, created mostly through manual input by people with often different domain expertise, and therefore some data cleansing practices like normalization & harmonization have been applied to see if this changes the picture.
Impact of Normalization & Harmonization on morphological differences
At searchHub, our AI-driven site search optimization excels at data normalization and harmonization, which are core strengths alongside spelling-correction. We therefore applied our probabilistic tokenization, word-segmentation, our morphological normalization for inflections and lemmas and our quantities and dimensions normalization for common attributes such as sizes and dimensions, quantities and others. After updating the analysis, the picture already shifted significantly:
Inconsistencies occur on both sides, about ~15% in product data and ~60% in queries. But their nature differs: queries suffer mostly from word segmentation issues, messy numeric normalization, foreign language vocab, and inflections, while product data issues stem mainly from compound words and inconsistent formatting normalization (dimensions, colors, sizes, etc.).
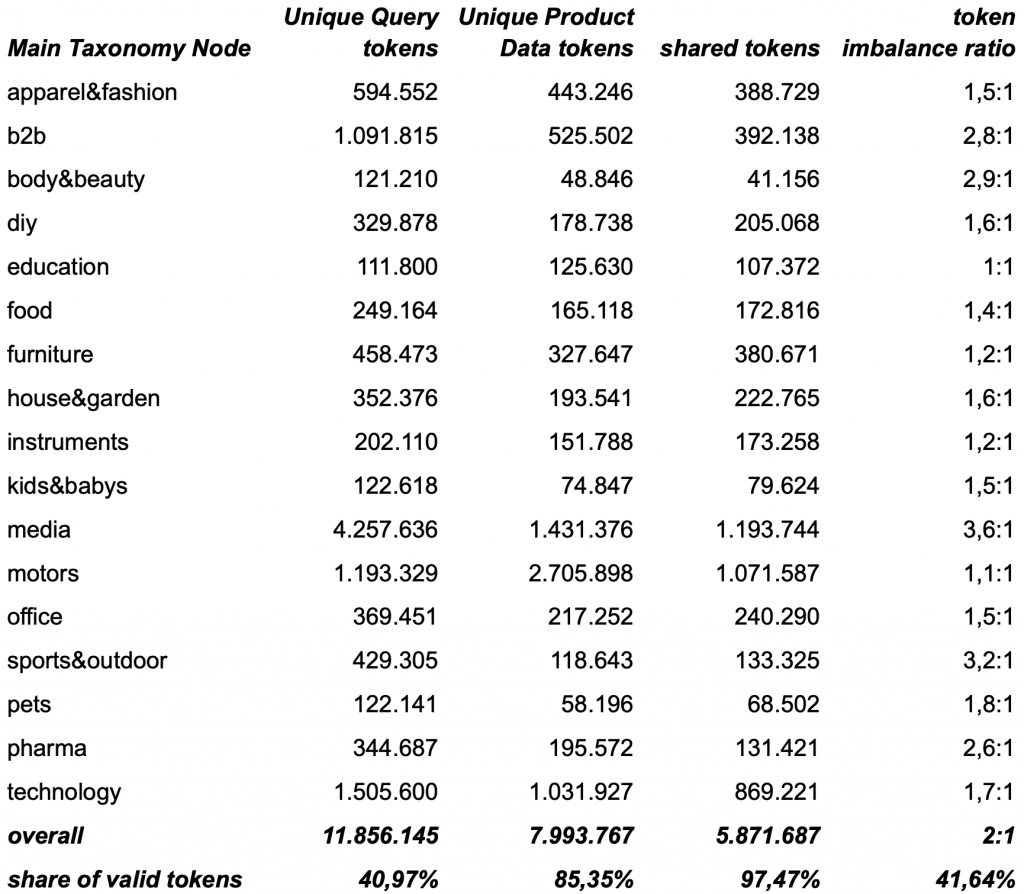
shared-tokens and token imbalance-ratio between search queries and product data across our main taxonomy nodes after normalization and harmonization
After normalization and harmonization the language corpus of queries has been reduced by ~59% while the product data corpus has been reduced by ~15%. It seems that normalization and harmonization reduce the language gap by roughly ~60%, as we have reduced the token imbalance ratio from 4.8:1 to 1.9:1. However looking closely at the table above reveals something interesting. While most taxonomy nodes now have an imbalance ratio of ≤ 2:1, but a subset remains markably skewed. A closer review points to two main drivers:
foreign-language vocabulary concentrated in Apparel & Fashion, Sports & Outdoors, and Pharma
rare identifier-like tokens occurring across B2B and Pharma.
Impact of foreign vocab on mismatches in ecommerce search
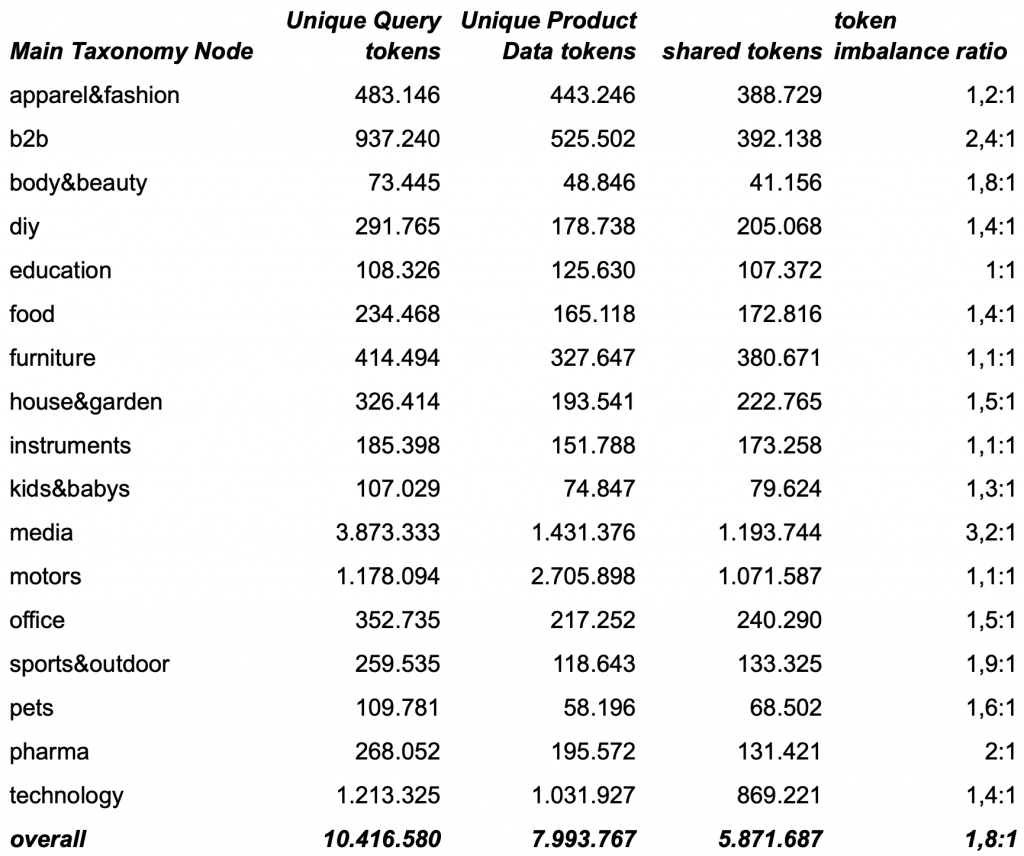
shared-tokens and token imbalance-ratio between search queries and product data across our main taxonomy nodes after removing foreign vocab
Removing the foreign, but known vocabulary reduces the imbalance ratio by roughly another 10%, which is more than we anticipated. But it seems that marketing related vocab like brand names, specific productLine names and product-type jargon play a significant role in some taxonomy nodes (zip-up, base-layer, eau de toilette, ….).
Impact of evolving language and infrequent vocabulary
As a next step we are going to try to quantify the impact of evolving language (vocabulary), focusing on the impact of both newly emerging tokens and very infrequent ones (frequency <2 over one year of data). This step is challenging because it requires distinguishing between genuine new vocabulary and simple misspellings of existing terms which might be the reason why we couldn’t find any generally available numbers about it.
Another strength of our stack is its ability to learn & update vocabularies across languages, customers and segments. That said, like any ML-based approach, it is not flawless. To ensure reliability, we follow a precision-first strategy: for this analysis, we only include cases where the system is ≥99% confident that a token represents valid new vocabulary over a time period of one year, excluding all others.
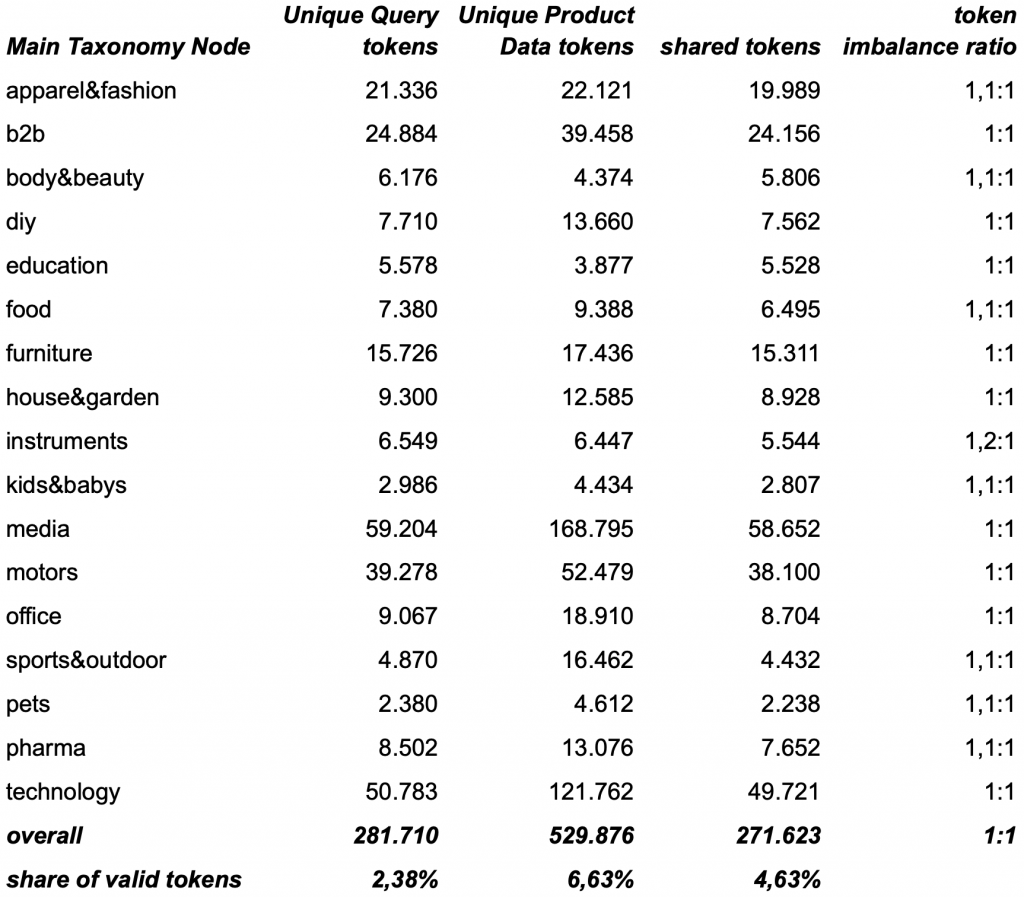
shared-tokens and token imbalance-ratio for new vocabulary between search queries and product data across our main taxonomy nodes
As expected, both sides show a steady influx of new vocabulary. However, the magnitude of change strongly depends on the product type / product segment, represented by the taxonomy node. Some segments exhibit relatively stable vocabularies over time, while others experience frequent shifts and updates. Mentionable types are productLine names, brand names, new trademarks and productModel names, materials, as well as somehow a never ending flow of newly created fashion color names. Interestingly, nearly 50% of the new vocabulary introduced into the product data over time does not appear to be adopted by users.
The impact of this type of vocabulary gap is not immediately obvious but becomes clearer when viewed longer term. Users often start adopting and using new product vocabulary popularized through marketing campaigns before the corresponding product content is indexed in eCommerce search engines, often due to stock or availability constraints. In many cases, this gap closes naturally once the relevant content is indexed.
Having quantified the effect of new tokens, we can now refine the analysis further by examining the share of infrequent tokens within query logs, where “infrequent” is defined as appearing in fewer than two unique searches over the span of one year.
shared-tokens and token imbalance-ratio for search queries with low frequency across our main taxonomy nodes
Surprisingly, a substantial share of valid words or tokens occur very infrequently (frequency ≤ 2) about 43% in queries and 23% in product data. At the same time, it is evident that this further amplifies the vocabulary imbalance between the two sides. Honorable mentions of types in this area are single product company products, product-model names, niche-brands and attribute or use-case specific vocab and tokens containing no useful information.
We specifically wanted to quantify the impact of very infrequent vocab since, to our knowledge, it accounts for most of the problematic or irrelevant search results when applying techniques to close the gap.
Summary:
So far, we have demonstrated scientifically that misspellings and morphological differences down to their major nuances are the most influential factors in closing the language gap. We were able to reduce the token imbalance ratio from 22:1 down to 1.9:1. From there filtering low frequent vocabulary gets us down to 1.1:1.
When search traffic (i.e., the number of searches per query) is taken into account, this influence also seems to stay almost equally strong. Our mapping data shows that, depending on the product vertical, effectively handling morphological nuances and being able to detect new vocab alone resolves between 81-86% of the language gap.
Conclusion
The goal is simple: make sure that when customers ask for what they want in their own words they actually find it. And when they do, conversions and customer satisfaction follow.
As shown, vocabulary mismatch remains one of the most stubborn problems, but one that the right e-commerce search best practices can solve. Customers rarely describe products the same way sellers list them. The solution is multi-pronged: query rewriting, document expansion, embeddings, and feedback loops all play a role.
Now that we understand the key drivers and their quantitative impact, we can focus on efficient, effective fixes. Notably, well-tuned, deterministic NLP steps reduced the language gap from 126,139,835 to 4,601,864 tokens (≈97%).
Next, we’ll assess how the impact of syntactic differences and of synonyms/variants distribute over the last 3%, and try to find the best solutions for them. For example, we’ll test whether the remaining gap can be closed by learning from sparse signals (few occurrences) and by leveraging LLMs’ generalization capabilities.
Motivation: In the Beginning, There Was One Tenant…
When starting a new Apache Solr project, your setup is usually straightforward—one language, one tenant, one tidy schema file.
You get everything running perfectly…
“…and you see that it is good!”
Adding another tenant, say expanding from Germany to Austria, doesn’t create many challenges. You still have similar configurations: same language, same synonyms, same analysis.
“…and you see it’s still good!”
But trouble arises when you grow further—introducing more countries, more languages, and more complex configurations. Synonyms change, text analysis gets complicated with different stemmers, and unique fields pop up everywhere.
Suddenly, your clean configs turn messy and confusing.
“…and you see it’s no good anymore!”
You start leaving marks everywhere in your configs to keep track of what’s specific and what’s shared, feeling more lost by the minute. But relax, there’s an elegant, developer-friendly solution: Jinja2 templating.
The Solution: Enter Jinja2 Templating
If you’re a Solr developer who likes Python, Jinja2 is your friend. With it, you maintain a single, central configuration template, embedding placeholders where tenant-specific differences exist. You never repeat yourself unnecessarily, making everything neat and manageable again.
Here’s how simple it is:
Create one main template for shared config settings.
Use placeholders to mark tenant-specific items.
Define these differences in small, individual tenant-specific files.
Render your configurations automatically, painlessly, with a Python script.
“…and you see that it’s good again!”
How to Use Jinja2 in Your Solr Project (Examples)
You only need to understand three core concepts:
extends: to base tenant configs on a shared template.
set: to define variables unique to each tenant.
block: for inserting full sections unique to certain tenants.
Example: Multilingual schema.xml Config
Step 1: Extend your central template.
{% extends "template.schema.xml" %}
Step 2: Set your tenant-specific placeholders.
In your central template (template.schema.xml), use placeholders clearly:
If you don’t define the block in the tenant-specific file, it remains empty.
A small Python script neatly handles generating your configurations automatically:
A small Python script automates rendering your final Solr config files:
from jinja2 import Environment, FileSystemLoader
def write_template(pathToTemplate, templateFileName, targetFileName, targetEnv, tenant):
environment = Environment(loader=FileSystemLoader(pathToTemplate))
template = environment.get_template(templateFileName)
content = template.render()
filename = f"{targetEnv}/{tenant}/{targetFileName}"
with open(filename, "w", encoding="utf-8") as message:
message.write(content)
print(f"... wrote {filename}")
pathToTemplate : defines in which directory your template files are located; one folder per file type (schema, solrconfig, etc.) helps to easily find what you are looking for.
templateFileName : the file name of the (language or tenant) specific template, e.g. template.schema.de.xml
targetFileName : the file name of the final config file (schema.xml or solrconfig.xml)
targetEnv : in this example we also have several different environments, such as “dev,” “qa,” or “prod.” So each of those stages has its own set of config files. This enables you to test new config changes before you deploy and destroy your production environment. 😉
tenant : For the schema.xml, templates have been set up per language but used for multiple tenants. That’s why it’s not only the tenant. This might be different in your setup, of course, so feel free to adapt how the files are organized.
Now you are ready to call your function to actually render some config files. We do it here for both dev and qa in one step, and for a list of defined tenants. The language code is taken from the tenant name:
for env in ["dev", "qa"]:
for tenant in ["DE-de", "AT-de", "NL-nl"]:
language = tenant.split("-")[1]
pathToTemplate = "templates/schema/"
templateFileName = f"template.schema.{language}.xml"
targetFileName = "schema.xml"
write_template(pathToTemplate, templateFileName, targetFileName, env, tenant)
Note: Ensure directories exist before running this script.
Now you can set up the same for the solrconfig.xml and render both file types in your code. This will give you a complete config for each environment and each tenant that you can now upload to your Solr installation.
Final Thoughts: Quick Tips for Agile Config Management
Templates are powerful, but during rapid testing, editing configs directly can sometimes speed things up. Once you’re happy, move changes back into templates to effortlessly roll them out.
“…and once again, you’ll see that it’s good!”
Jinja2 templating makes Apache Solr configurations manageable, structured, maintainable, and scalable, letting you efficiently handle complexity without losing your sanity.
Monday, March 31st – incident report
On Monday, March 31st, searchHub’s infrastructure had its first measurable downtime for years. Between 11:30 UTC and 12:38 UTC, numerous systems, including our UI used to analyze and manage search, were practically unavailable. In this post, I want to explain what happened and how it is connected to our current global situation.
To begin …
searchHub was built by design to run independent of customer systems. That’s why more than 90% of our customers didn’t even realize that there was a problem, as their system ran totally normal. All customers who follow our recommended integration method use a small but mighty client system that holds all necessary data to optimize search in real-time without the need to do synchronous calls to the outside world. That’s how we not only achieve extremely low latency, but (as we have seen on Monday) also a very comforting level of independence. No single point of failure. No submarine that can destroy an underwater cable connection, as there is no cable in between.
Unfortunately, some of our customers cannot use any of our provided client systems, or just prefer to use a full SaaS. These clients were partially affected – that means that we were unable to optimize their onsite search and their search ran with a lower quality of service during that time. This hurts, and I sincerely apologize for the inconvenience.
Now, what happened?
All our systems run on standardized cloud infrastructure. Kubernetes with auto-scaling, shared-nothing, load-balanced and distributed between data centers. Certain services require mighty machines to do our machine-learning stuff. Some machines are needed 24/7, others are scheduled on demand as needed or configured. Some services serve billions of cheap requests that don’t require lots of server power. They can be reached through an API layer, commonly named Ingress. This is especially true for our tracking systems. Practically, they have little to do but send tiny pieces of data to an asynchronous messaging system. These services are heavily load balanced and distributed between machines. As they don’t produce a significant load, they are allowed to run everywhere. We carefully monitor these services to ensure that enough ingress pods are available to process these requests.
Kubernetes allows an affinity between services and machine types to be defined, ensuring software runs with suitable resources, especially CPU and memory. Conversely, anti-affinity makes sure that certain services don’t run on machines too small for the task (bad performance) or disproportionately large machines (high costs). These affinity settings allow the most efficient use of the underlying hardware. A goal that we consider crucial, as data centers worldwide are responsible for a significant portion of global emissions. But these settings can grow complex, as in “this Pod should (or, in the case of anti-affinity, should not) run in an X if that X is already running one or more Pods that meet rule Y” (https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/#affinity-and-anti-affinity).
In our case, it happened that due to some missing constraint, a huge number of the ingress pods were scheduled on only a very small number of nodes. From a Kubernetes perspective, this fit perfectly well with memory and CPU limits and thus was not detected by any monitoring system. But the sheer number of simultaneous network connections at 11:30 UTC overwhelmed the network interfaces, as they can only handle 2^16 connections in parallel.
All of this is not a real problem even if the network interface is running at 99.9% of its maximum capacity. However, a tiny bit more, and the tipping point is crossed, everything breaks down, and you need quite some time and effort to get everything up and running again. Of course, we have fixed not only our configuration, but also extended our monitoring systems to alert us early if heavily autoscaled, cheap services such as ingress are not distributed widely enough across the cloud infrastructure.
See any similarities? Tipping points are an issue. Your environment can look totally green, although being close to its limit. It is challenging to tell when the tipping points are reached. If we have signals which indicate that such a tipping point could be reached, we need to take action early enough. Once a tipping point is crossed, there might be no way back. Cloud infrastructure can easily be recovered by experienced personnel. But we most likely cannot recover our planet.
Building on the insights and challenges discussed in PART-1 regarding effective and efficient vector retrieval for eCommerce, we developed an entirely new solution that introduces a groundbreaking new capability called NeuralInfusion™. Since the core principles and architectural choices behind this solution are applicable to any search system, we decided to share more details here in PART 2. In short NeuralInfusion™ is centered around three key concepts that set it apart from anything we’ve seen before in how it addresses the identified areas of improvement:
In this second part, we will shed some light on areas 1 and 2, while area 3 will be addressed in the third post of the blog series.
1. Identifying queries with optimization potential
We already learned in PART-1 that recall in modern search stacks is primarily driven by two methods: keyword-search and vector-search. Each method has its strengths and weaknesses when retrieving documents: keyword-search excels at keyword matching between query and document, while vector-search shines at more broadly inferring the query context.
Recognizing that hybrid-search-approaches primarily boost recall and precision in specific contexts, we focused on identifying these opportunities.
Recall: To enhance recall, we looked for both clear and subtle indicators of optimization potential. Clear signs include zero-result queries, queries with few results, low engagement, or very low findability. Additionally, we identified a less obvious area: queries where product data errors or inconsistencies hinder keyword-based retrieval systems from returning all relevant items. We further leveraged the concept of query entropy to jointly optimize the recall-set-generation across the different retrieval methods.
Precision: For improving precision, we analyze user data and relevance judgments to find queries with low engagement, poor findability, extensive search bounds, and high exit rates. Moreover, the diversity and appeal of search results are crucial, particularly for branded and generic but also very specific queries. Specific markers or indicators can be used to test and refine these aspects.
Fortunately, our searchHub searchInsights feature already identifies promising queries for improvement, while the Query Experimentation (Query Testing) tool allows us to test various retrieval strategies to optimize their combined performance. This ongoing experimentation helps us determine the most effective approach for each query type over time.
Once we identified queries where we expect some significant uplift potential by increasing recall and/or precision, we had to come up with a strategy to tune / balance it. As a first step towards a more optimal retrieval strategy, we decided to build a model that would allow us to adaptively tune the recall set size from each retrieval mechanism based on the request context. We refer to this as the “Adaptive Precision Reduction Model” or APRM. Its primary goal is to determine when to increase recall and when to hold back. If increasing recall would significantly compromise precision, the model either adjusts or avoids the recall boost altogether. This is especially helpful in zero-result scenarios where a recall expansion might lead to completely irrelevant results.
We are still convinced that avoiding zero-results in all cases is not the best strategy as it hides critical information about the observed gaps in product assortment, user needs vs. the product assortment on offer. Therefore, precise adjustment and tuning of precision vs. recall is essential but very difficult to achieve with a standard vector search that is based on approximate nearest neighbors algorithms. Search managers, gain total control over precision vs. recall with the Adaptive Precision Reduction Model approach. To retain search platform independence, we decided to decouple the new advanced retrieval stack from the underlying search platform.
2. Decoupling advanced retrieval from the search platform
Search platform independence is central to searchHub’s philosophy. Our customers use a wide variety of search solutions, including vendors like Algolia, FactFinder, Bloomreach, Constructor.io, SolR, Elasticsearch, and OpenSearch. Some rely on search platforms integrated into their commerce platforms, while others build and fine-tune their homegrown search engines using open-source software or custom implementations.
We design our enhancements to be platform-agnostic because we believe our customers should retain control over their core business logic. This encompasses critical components such as stock control, pricing, merchandising strategies — like retailMedia Ads, and personalization. Retaining control over these elements allows retailers to maintain flexibility and innovation, adapting swiftly to market changes, customer preferences, and evolving business goals. And it enables retailers to create unique experiences aligned with their brand and operational strategies, without being limited by the constraints of a particular platform. Recognizing that many of our customers have invested considerable time and resources in customizing their search platforms, we aimed to offer NeuralInfusion™ in a platform-agnostic manner—without requiring them to re-platform. The challenge was finding an efficient way to achieve this.
I’ll admit, we were well into the development of many parts of the system before we had a clear solution for decoupling. It’s necessary to point out how deeply grateful I am, to my development team and our customers. Over the better part of a year, they remained patient as we worked through this challenge. In the end, we developed a solution that is IMHO both simple and elegant. Though, admittedly, it now seems straightforward in hindsight.
The breakthrough came when we realized that direct integration of different technologies was unnecessary. Instead, we focused on integrating the results—
whether documents or products. Essentially, every search result listing page (SERP) is just a set of products or documents retrieved from a system in response to a given query, which can then be refined through filters, rankings, and additional layers of personalization.
This led us to find a way to add missing or more relevant documents to the search process and, by extension, to the search results. In this way, we would maintain platform independence while ensuring our customers benefit from cutting-edge neural retrieval capabilities, without the disruption of replatforming.
The high-level blueprint architecture:
Instead of requiring our customers to implement and manage additional systems like a vector retrieval system, we optimized and simplified the retrieval process by dividing it into distinct phases and decoupling them. Rather than applying multiple retrieval methods to every query in real-time, we perform hybrid retrieval asynchronously only for specific cases, such as clustered intents or predefined queries. This is especially true for queries that revealed clear opportunities for improvement, as mentioned above.
By separating the embedding model inference from query execution, we can precompute results and retrieve them through very efficient key-value lookups. At query time, we use the query intent as the key, and link it to a set of documents or product IDs as values, which are then incorporated into the search engine query.
NeuralInfusion architectural diagram.
Fortunately, 9 out of 10 search platforms support combining language queries with structured document or record ID lookups via their query APIs. This enables several interesting specialized optimization use cases like adding results, pinning results and removing results from the initial search results.
Here is a simple integration example for the elasticsearch search platform:
This approach effectively tackles multiple challenges at once:
Latency and Efficiency: By decoupling the complex retrieval phases, we enhance speed and responsiveness. This shift transforms expensive real-time look-ups into cost-efficient batch lookups that primarily utilize CPU resources without significantly increasing response times.
Business Feature Support: We maintain essential business functionalities that retailers depend on, such as filtering or hiding products, implementing searchandising campaigns, applying KPI-based ranking strategies, and integrating third-party personalization capabilities.
Testable Outcomes: The system’s performance can be continuously measured and optimized on both a global scale and at the query/intent level.
Transparency and Control: Customers retain full visibility and control over the process and returned results, ensuring they can oversee and manage outcomes effectively.
Future-Proof Architecture: This decoupling strategy allows us to maximize potential retrieval strategies. We can integrate or combine any current or future models or architectures into our execution pipelines without requiring our customers to adjust their APIs or hurting their response times.
For new or previously unseen queries, the system requires one initial attempt before reaching its full effectiveness. However, this limitation affects only a small portion of queries, as our system already successfully maps over 85% of queries to known search intents. We expect to capture more than 90% of the potential value immediately. We will evaluate the economic impact of this minor limitation in future analyses.
Summary
In this post, we outlined the careful design behind the Infusion component of our NeuralInfusion™ capability. By reframing what was once seen as a capability issue into a straightforward integration process, we’ve created a solution that requires minimal additional investment while preserving high agility for future needs. With this architecture, setup, and integration, our customers can realize 90-95% of the identified optimization potential—all with complete transparency, no added latency, and no increase in system complexity.
In the 3rd and final part of this series, we’ll focus on the “Neural” part of our NeuralInfusion™ capability and how we found unique ways to overcome most challenges related to tokenization and domain adaptation.
In the past 2–3 years, vector search has gained significant attention in ecommerce, primarily because it claims to offer a solution to a major challenge in keyword-based search known as the language gap or, in more technical terms, proximity search. The language gap refers to the disconnect between the words that a user types in to formulate the search query and the terms used in product titles and descriptions, which often leads to no or poor search results. At the same time, vector retrieval can infer semantic similarities between queries and documents, making it an effective tool for use as a re-ranking layer in the later stages of search to enhance the relevance of the results.
After stripping away the inflated marketing claims from vector search vendors and so-called domain experts, which our customers and users often echo, we identified a mere two areas of genuine optimization:
Improving recall and
Enhancing precision, primarily through re-ranking
While this may seem obvious, defining these two areas broadly allows us to challenge current solutions with alternative approaches or technologies later on. We anticipate this will incite further discussion within the community, which we welcome. Even still, these are the only two aspects to be both technically and economically verifiable. In terms of our customers’ business language, these core areas translate to:
Finding more (still relevant) results for a given set of queries (improving recall)
Ranking more relevant items higher in the results list (enhancing precision)
However, the feedback we received from our customers, who tried to productize vector retrieval, essentially boils down to one striking problem: vector retrieval always returns the k closest vectors to an encoded query vector. This is the case, even if those vectors are completely irrelevant.
So the open task is clear: Identify or, better yet, mitigate these situations to significantly increase trust in vector retrieval and enable more effective use of the strengths of both vector and keyword retrieval methods.
Hybrid search: the silver bullet?
Hybrid search — combining Vector and Keyword Search
It is crucial to acknowledge a recent consensus within the search community: vector search is not a one-size-fits-all solution. While it performs exceptionally well in some query types and retrieval scenarios, it can also fail dramatically in others. This has led to the emergence of hybrid search approaches that combine the strengths of both vector and keyword-based retrieval methods. Although this approach is appealing, our real-world observations highlight a key issue:
Many hybrid methods merely average the results of both techniques, undermining the goal of leveraging the best of both. Consequently, the overall value often falls short of the combined potential of the two strategies.
But that’s not at all, the least, questionable issue in current hybrid approaches.
Low maturity level of hybrid search approaches
For an Ecommerce shop, there are essentially two possible paths to choose from:
Switch to a new “sophisticated” vector search vendor that has bolt on rudimentary keyword search support
Stick with an established keyword-based vendor or solution that has recently bolted on vector search capabilities.
In either case, there’s a noticeable gap in quality and maturity between the two retrieval methods and solutions, especially when applied to the retail and ecommerce domain.
1. Lack of essential business features
While working closely with our customers, we’ve noticed that many hybrid search approaches often lack critical day-to-day business features. Essential functionalities like exclude-lists, results curation, and multi-objective optimization are frequently missing, despite being vital for retailers who prioritize not just relevance or engagement, but also margins and customer lifetime value (CLTV).
For example, our customers regularly receive trademark enforcement inquiries, sometimes multiple times a week. Brand or manufacturer lawyers may prohibit retailers from displaying results for queries containing trademarked terms. A case in point is the trademarked phrase “Tour de France”; during the event, many users searched for cycling-related products, but most retailers were forbidden from showing results for these queries. Additionally, established brands typically restrict the display of competing products close to their own, and non-compliance can lead to legal repercussions.
Retailers also need the ability to manage or curate search results. For broad queries, there’s often a need to guide customers through the results to avoid overwhelming them with too many options. In branded searches, retailers can generate additional revenue through promotional placements and Retail Media Ads.
Search result pages are key revenue and margin drivers for retailers. Effectively managing this multi-objective optimization challenge—which includes stock clearance, promoting bestsellers, highlighting high-margin items, and featuring mannequin products—is crucial for their success and is commonly known as Searchandising. Unfortunately, these essential business features are frequently missing in new hybrid search solutions or are added as an afterthought, leading to less than optimal outcomes.
2. Added dependencies and complexity
Hybrid search scenarios introduce many additional dependencies to the retrieval system. In addition to indexing and searching tokens or words, there’s also a need to embed and retrieve vectors, which can significantly slow down the indexing process—often extending it from minutes to hours. This added complexity creates challenges, particularly in near real-time (NRT) search scenarios common in ecommerce and retail, where factors such as new product listings, stock levels, and fluctuating business metrics (like demand) are crucial.
Moreover, fine-tuning and optimizing the models that embed data into vector space is more challenging than it initially appears, especially over time. These systems regularly experience a notable decline in performance as time goes on, adversely affecting business KPIs. This issue is amplified when decisions to implement these systems are made based on a single initial experiment or test 🤦. One contributing factor, in system performance decline, is the use of information-rich multimodal embeddings, which can lead to a phenomenon known as the Modality Gap or Contrastive Gap. In such cases, embeddings do not form a consistent and coherent space but instead form distinct subspaces, despite being trained and fine-tuned to avoid this outcome.
3. Significant increase in cost per query
Due to the added complexity and the substantial increase in computational demands of hybrid systems, many ecommerce shops experience costs 10 to 100 times higher per query. Our aggregated data indicates that keyword-based searches usually cost equal to or less than 0.05 cents per query. However, in hybrid search scenarios, we’ve observed costs ranging from 0.25 to 2 cents per query, depending on the vendor or system used. Although these amounts may seem small individually, they quickly accumulate when processing millions of queries each month, significantly squeezing already tight profit margins. This cost escalation comes at a time when economic challenges make efficiency one of the most crucial factors for market sustainability.
4. BM25, Tokenization and vocabulary size
In many hybrid systems, keyword retrieval often relies solely on BM25, which is not ideal for ecommerce contexts. Critical aspects like model numbers, price ranges, sizes, dimensions, negations, lemmatization, field weights, and bi- or trigram matching are frequently neglected.
Additionally, unlike everyday language, ecommerce data is characterized by highly specific, low-frequency vocabulary. Examples of terms, you’d be hard-pressed to find in everyday language but appear disproportionately often within ecommerce:
brand names
model names
marketing colors
sizes
etc.
The issue is that most embedding models used for vector retrieval struggle to capture this kind of terminology. Why is it such a challenge for vector search to include this type of mundane information? Vector search has a smaller vocabulary due to constrained memory and efficiency limitations. It’s no fault of vector search, but rather a question of using the right tool for the job. More on that later.
While we currently manage vocabulary sizes ranging from 1.5 million to 18 million unique entries, most embedding models (vector search solutions) that are performant enough for ecommerce scenarios top out at around 100,000 to 250,000 unique entries. Words or tokens not included in these vocabularies are approximated by their character fragments (ngrams) and their corresponding probabilities. As with any form of approximation, this can compromise result precision.
Vector search can be useful in handling misspellings due to its ability to leverage contextual subword information. However, it can perform poorly if the embedded tokens are not well-represented in the training set.
Vector search, or dense retrieval, can significantly outperform traditional methods, but there’s a catch: it requires embedding models that have been fine-tuned for the target domain. When these models are used for “out-of-domain” tasks, their performance can decline dramatically.
If we have a large dataset specific to a domain, like “fashion items,” it’s possible to fine-tune an embedding model for that domain, resulting in dense vectors that offer strong or decent vector search performance. However, the challenge arises when there isn’t enough domain-specific data. In such cases, it’s possible that a pretrained embedding model may outperform traditional keyword search, but it is highly unlikely.
This is the situation we most often encounter in production environments. B2B ecommerce shops usually have a wealth of data about their products and services but lack comprehensive domain data that could help them better understand customer queries.
6. Multilingual understanding
While many search vendors assert a significant increase in natural language understanding query volume, our production data does not support this claim. We observed a slight upward shift, but not substantially or statistically significant. However, what has notably increased are multilingual queries. Cross-border commerce is becoming more prominent. Multilingual queries originating from foreign languages across Europe now account for about 2-7% of ecommerce search volume. Along the same lines, we see an increasingly diverse mix of queries in English, French, Spanish, Italian, Chinese, Turkish, Arabic, and Russian in our customer logs.
Later in our evaluation, we’ll show how most current embedding solutions, including advanced multilingual cross-encoders, struggle with handling and understanding low-frequency vocabulary (infrequent search terms) across several of these languages.
As it stands, there is no universally proven “best” approach for effectively combining the results of keyword and vector-based retrieval strategies in hybrid search. Existing methods like Fusion and Re-ranking are evolving, but still fall short of realizing the full potential of hybrid search. This owes largely to each strategy’s distinct strengths and weaknesses, making it challenging to achieve an optimal combination.
Fusion combines results from different search methods based on their scores and/or their order. It often involves normalizing these scores and using a formula to calculate a final score, which is then used to reorder the documents.
Re-ranking involves reordering results from various search methods using additional processing beyond just the scores. This typically includes some more in-depth analysis with models like cross-encoders, which are used only on a subset of candidates due to their inefficiency on large datasets. More efficient models, like ColBERT, can re-rank candidates without needing to access the entire document collection.
However, these methods often struggle to dynamically adapt to different query types, resulting in inconsistent performance across various scenarios, which we will show later.
Analyzing current approaches
This seeming divergence between these two methods led us, along with our customers, to question whether there are more efficient approaches that fully leverage the strengths of both retrieval strategies. Preferably, we are looking to create a scenario where 1+1 is equal to or ideally greater than 2. We began by analyzing specific customer use cases. Our goal was to deeply understand the specific problems our customers sought to address when they adopted or transitioned to hybrid search.
We studied how these two improvements affect hybrid search in real-world production. Since searchHub is built on an experimentation-centric approach, we can evaluate performance at global-shop, search-shop, and query-specific levels for our customers. Unlike many vendors who claim hybrid search is the best retrieval method without providing concrete data, we aim to share our findings with our customers’ permission. A big thank you to them for that. Please note that the numbers presented are based solely on hybrid search systems that are not under our direct control, whether developed in-house or sourced from external vendors.
Setting up the analytical foundation
As previously mentioned, we began by identifying and analyzing the specific problems and use cases our customers initially set out to address. We distilled these into the following types of queries they aimed to improve:
Query Type Definitions
To offer some quantitative insight, here is the distribution of query demand and search frequency across these types, based on data from the customer base that participated in this analysis. In total, we identified 3,000 unique queries, representing 83% of the overall search demand from these customers. The distribution of these 3,000 queries across the different query types is shown below.
Query Type Dispersion
For each participating customer, we selected the top 100 queries and additionally sampled (random weighted sampling) 100 more from the mid- and long-tail for each query type and customer to evaluate competitive retrieval strategies.
For evaluation, we opted for a straightforward approach using precision@k. Each selected query was compared against the results from different retrieval strategies by counting the number of “relevant,” “strongly related,” and “irrelevant” items in the top 12 positions. For each “relevant” item in the top 12 results, we assign a score of 2, for each “strongly related” item a score of 0.5, and for each “irrelevant” item a score of 0. We then use simple addition to aggregate these scores, which we refer to as “relevance points.” The more relevance points accumulated per query type, the better the performance of the specific retrieval strategy for that type.
We acknowledge that this evaluation method may not align with industry or research standards, but we prioritized feedback, clarity, and ease of debugging for our customers over adherence to strict, unhelpful standards. More importantly, we were able to prove that optimizing according to precision@k had a significant positive impact on the relevant business KPIs CTR, A2B, CR, AOV and ARPU while other standard evaluation methods like NDCG failed to do so.
Recall@12 vs. Precision@12
Recall@12 Analysis
Precision@12 Analysis
For BM25 we used standard Elasticsearch, ES OCSS and CLIP retrieval was done via marqo.ai
The possibility to distinguish different query-types gave us a lot more insight into the pros and cons of hybrid search, as it clearly demonstrated the true potential compared to a global view.
The first table shows that the vector retrieval component of hybrid search excels at enhancing recall when using a multimodal model like CLIP (which can leverage text and image information). This is especially true for query types where recall is typically a challenge (such as type-1, type-2, type-7, and type-8), resulting in significant recall improvements. The table also shows that, even in the ecommerce domain, traditional keyword retrieval can achieve substantial gains in recall compared to the standard BM25 algorithm — from 70.5% to 81.57% with ES OCSS.
The Precision@12 analysis indicates that hybrid systems are not fully achieving their potential. While they improve precision@12 significantly for queries where recall is the main issue (about 15% of queries), they also cause substantial drops in precision@12 (in 12-28% of cases) for many scenarios where keyword-based search alone performs exceptionally well. Hybrid systems may achieve considerable improvements for certain query types, but they often rely on local rather than global optimization. In the end, even the newest technology needs to balance recall and accuracy. There is no one-size-fits-all solution.
Even approaches that combine high-recall vector retrieval with fine-tuned re-ranking often struggle to select or emphasize the most relevant parts when the initial set of retrieved results becomes more ambiguous.
Summary
We learned that a hybrid retrieval system alone cannot determine where or whether a specific query’s performance is improved. With this new information, it is clear that choosing the best retrieval strategy (keyword-only, vector-only, or blended hybrid) for each query should lead to big improvements in overall performance.
Despite the expected improvements in recall, we have also shown that improving precision or even maintaining it is much more challenging. Unfortunately, most marketing and sales efforts tend to focus on recall only when trying to sell you their vector search solution, while our data clearly indicates that precision correlates much more with sales and conversion than pure recall.
Taking all these insights and the other identified areas of improvement into account, we developed a radically different new approach called NeuralInfusion™ to address these gaps. This new approach will hopefully fully harness the potential of hybrid search, while being significantly more efficient. Stay tuned for part 2, where we will explain this new idea in more detail and compare it to other ideas we looked at before.
Enhancing efficiency, accuracy, and customer satisfaction are foundational optimization factors both when managing vast product inventories offline or optimizing onsite-search with redirects. Just as a well-organized inventory ensures quick and precise product retrieval, search redirects streamline the user’s journey by guiding them directly to relevant content. This digital parallel highlights the importance of strategic organization and management in both physical and digital spaces to improve overall user experience and business outcomes.
Are librarians the real pioneers of ecommerce site-search?
Do you remember librarians?
The word, librarian, always reminds me of that one Michael Jackson song, “Liberian Girl”. As a kid, I thought he was saying: “librarian girl” 🤦 😁.
I digress …
At the library, Librarians had an almost mythical status. Acting as a shortcut right through the heart of the Dewey Decimal Classification. Of course, if you had the time, there were other options for finding a book. There was the card-catalog, and if you just wanted to meander, there were signs guiding you to different areas of interest. But areas of interest overlap. And the card-catalog required you to know at least a book title or author to get any further. A book about climbing, for example, could just as easily be in either the sports or health categories. Before too long, you could easily find yourself running all over the library on a wild-goose-chase looking for that perfect book.
For the most part, when I went to the library, however, I had a good idea of what I was looking for. I knew the subject, or maybe the author, so I would frequently head straight to the card-catalog. On more than one occasion, though, I would stand in line at the librarian’s desk to tap into the secret power that was The Library Gods. Of course, you’d have to have a bit of luck. There was never a guarantee that the librarian would be at her desk. And, what’s more, she’d have to be willing to help you, and not just direct you to the catalog-cards. So, you’d flash your charming eyes and ask if she could help you find your book. If all went well, she’d look at you over her glasses, stand up, and walk across this tremendous room with vaulted ceilings, to the exact location of your book, pull it out, hand it to you, and then begin providing suggestions for further reading on the topic but in a different part of the library. It was pure, sorcery.
Now, that we’ve evolved away from library use, I’m wondering … where’d the magic go? Remember the last time you navigated to your favorite ecommerce website, using the latest in cutting-edge site search technology, typed in your search term and, like witnessing the all powerful sorcery of a well-versed librarian, you immediately got the result you were looking for
Nah … didn’t happen.
Or at least not consistently.
To top it off, there’s no way to quickly speak with a search engine. It’s like a librarian, who’s not interested in what you’re looking for at all. Imagine getting a response like: “this is your book, babe. Take it or leave it!”.
But, like masochists, we take it on the daily, from site-search engines the world over. Sometimes, you don’t even find anything related that would help guide you in your search process. Instead, you get a list of results that make you question, whether you may have clicked into the wrong shop altogether.
One might be tempted to begrudge ecommerce site-search vendors, or the ecommerce industry as a whole. Especially, when considering the history (from 7th century B.C.) of product catalogization. But alas, product data retrieval has not evolved linearly. Its haphazard, almost accidental improvement over the last 30+ years, has not infrequently been the bane of many an ecommerce manager’s existence.
Only recently, with the advent of Large Language Models, increased computational power, and sinking hardware costs, has product search began to nudge its way back into the sphere of magical sorcery. Even so, for the vast majority of ecommerce shops, it remains a black art to this day. No matter their level of product search mastery.
It behooves us, in light of the above, to briefly pause and pay homage to the dark art of librarian sorcery, and its nexus … the human brain. I mean, Christ, it’s been holding the keys to product discovery, like it ain’t no one’s business, going on 6,000+ years.
And for all ecommerce search’s shortcomings, we must consider the grandness of our task these last decades: to reproduce a neural cataloging structure that mimics the very powers of our favorite librarian. Breaking this code, and laying it free for all humanity to benefit from, is something comparable to supplanting said librarian, and expecting her to perform feats of magic irrespective of the library, the language, or the subject she’s confronted with.
It will simply fail.
So where do we begin?
Mimicking human classification methods
Building on the idea of the library, how do we go about searching specifically enough, to lead customers to their intended product as efficiently as possible, while simultaneously making them aware of related or similar products, with different names, in different categories, but directly related in scope or kind?
This type of product display (or information delivery) is necessary because it mimics the way the human brain catalogs information.
So how do I do it, how do I mimic the ingenuity of human information retrieval?
Before we get ahead of ourselves, let’s take a moment to acknowledge the technologies and strategies that have gotten us to where we are.
Search filters
Curated landing pages
Product finders
These tools are helpful and necessary. However, they all assume the customer knows precisely how to find their product. Product finders, are often hidden within category landing pages, or appear after a related search (all spelling mistakes aside). Curated landing pages, again, are triggered only if a certain keyword is entered. Search filters are only then relevant if the customer has managed to land in the general location of their product of interest.
This leads to unnecessary frustration, for the uninitiated first-time-visitor to your shop. And what’s more, the strategies, aren’t increasing search conversions like you think they are. Even for the visitors using them. They simply provide another point of entry for those visitors who already have a good idea of what they want.
This is not a trivial problem, and one for which AI was predestined.
So what’s the alternative to current site-search-journey optimization?
Consider a smarter alternative to the above. Imagine consolidating all keyword variations that verifiably lead to the purchase of the same article. Then, in a feat of sheer brilliance, funnel all traffic generated by this keyword-cluster, to a dynamically populated landing page.
It’s at this point that we return to the above-mentioned search optimization strategies. Because, now, you’ve ensured that a broader audience of highly targeted consumers reach the right page. As a result, your product finder reaches the appropriate people with a relevant product suggestions for an audience in market. What’s more, context-driven search filters are considered helpful by your audience because they match expectations. Expectations that were gathered at the point the keyword was entered into the search box, allowing you to create a CONTEXT, not simply from a single keyword, but a whole cloud of keywords related to the customer’s topic of interest.
So, now, not only do you return spot-on search results, but simultaneously whet the appetite of your customers for more, based on a highly relevant result context.
All of this can’t be cumbersome or overly engineered, requiring scientific rule-sets. And … it has to be possible without changing search vendors because that’s a shit-show of epic proportions. Nah, it’s gotta be an intelligent AI perfectly mimicking the magical associative sorcery of a librarian.
searchHub AI Search Redirects
This is where AI-Search-Redirects comes in.
Like a librarian leading visitors to their precise book, customers are led directly to their product. What’s more, AI allows categorical connections between products. This is like the librarian leading you to different sections of the library, making you aware of related content and media. Whether a book, magazine, video, or that 35mm archiving machine that saved everything onto film.
This is a monumental step forward for site search. The last decades have focussed on lexical similarities. Think fuzzy logic, phonetics, synonyms/antonyms, and the like. AI-Search-Redirects considers all these lexical properties, but now as a piece in the puzzle that is the shopper’s context. We consider things such as categorical proximity, and go as far as evaluating visual likeness between products. This translates to maximum efficiency, while maintaining ultimate flexibility.
Maximum Efficiency, ultimate flexibility
Off-loading bulkier search management tasks to AI increases efficiency. Think about the ability of artificial intelligence to identify contextually related lexical, orthographical, and visual signals to deliver an optimized user-experience for each possible query.
This in no way undermines ultimate flexibility when managing search manually. Integrating AI assistance into your search optimization is not an “either, or” decision. Good use of technology, always presents the best possible mix of all existing options. In this way, AI-Search-Redirects is a “yes, and” addition to your current search optimization workflow. Like an autopilot, guiding a plane or automobile to its destination, there is always the flexibility to take control and edit customer search journeys manually.
Like signs that guide us through a library, a card-catalog, or the librarian at the front desk, AI assistance works in the background so that customers always receive the most optimized product listings, ensuring the highest shop revenues.
How Can I Trust the Accuracy of the Results?
You might be weary of optimizing your site-search by machine. With over 25 years of site-search-optimization experience, we were too. That’s why we backed-in continuous A/B-Query-Testing from the start.
searchHub runs continuous a/b query tests against all query edits, even after they’ve been optimized. No matter if AI, or manual human intervention. Continuous A/B Query Testing ensures the most accurate, optimized search result for the consumer experience in question. If at any point a better performing query variation should emerge, it is flagged and awaits human confirmation.
Customer satisfaction
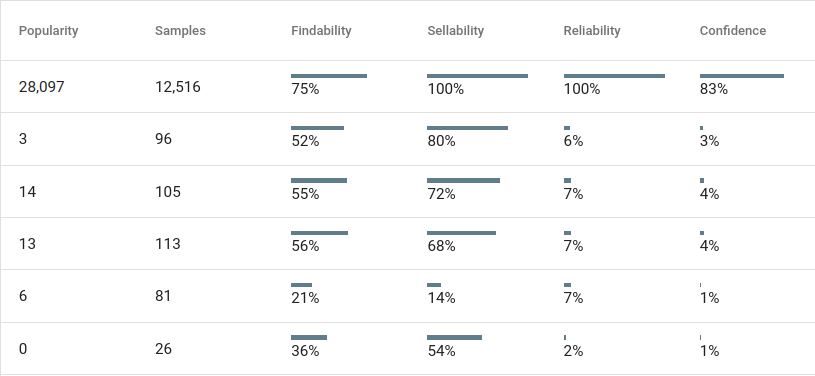
Customer satisfaction is paramount to search optimization. 15% of customers are using search terms, you’ve never encountered before. It goes without saying that customers who are unhappy with the search results, won’t purchase from you. Because of this, we’ve taken great pains to integrate customer sentiment into our AI. We’ve even gone as far as creating two new KPIs, just to be sure, because we weren’t happy with the way site-search journeys are currently measured.
Findability
Sellability
Product findability evaluates how easily products were found after entering a keyword into the search box. Based upon this information, we create either a positive or a negative association between the keyword and the related product result set.
Product Sellability, measures to which degree products are added to the basket for a given keyword cluster. searchHub then records positive (a product was added to the basket), and negative associations (no product was added to the basket) respectively.
As you can imagine, there are myriad ways to combine these two KPIs. Just to give you an idea of the complexity, we evaluate all associated keywords (variations, typos, misspellings, synonyms, etc.), and all products within the result-set viewed by the customer.
In the end, searchHub provides your existing site-search with something no one has ever seen before: clarity. Clarity of customer context. And clarity about what it means to have an optimized customer search journey.
True site-search personalization is a conversation
AI-Search-Redirects, allows you to communicate clearly back to the customer. And why shouldn’t you? The site-search is the only place on your website, where customers condense their intentions into a limited number of keywords, telling you what they want from you. Nowhere else, on your website, do you have the opportunity to be this personalized with your customers.
AI-Search-Redirects leads highly qualified traffic to curated landing pages
The last piece of AI-Search-Redirects, is the redirect. Once the AI has analyzed your shoppers’ purchase behavior, and clustered all variations of keywords leading to purchases of the same product, it’s time to test which keyword within a cluster will be the one to receive all the cluster traffic. Once that’s in place, it’s time to create the store window those customers will see when they land on the result set. It’s no different from what you’ve been doing the last 20 years in ecommerce. Only now, these strategies yield the returns you’ve been looking for:
Product Placement Which products and categories will appear most prominently.
Signage Category Banners, offers, partners
Advertisements Highly qualified search traffic is more easily monetized programmatically.
AI-site-search redirects, are the foundation for highly optimized, high-return, dynamic landing pages for each customer query.
It’s remarkable to think this is all possible without changing your site-search vendor. Maybe we have created the perfect modern librarian: one that functions equally well, no matter the “library” (shop, or search technology). In that case, I take back what I said earlier: I am hopeful about the state of site search. And you should be too! 😀
If you’re not already working with searchHub, reach out to us! We’d love to hear the pains and woes of your journey, designing context-driven customer site-search journeys.
Site Search Transformation through Efficiency, flexibility, and transparency!
Have you ever been overwhelmed by the amount of effort it takes to optimize your ecommerce site search? What if your business could improve its site search with an AI built to optimize it, not replace what you already have? Imagine a tool that can enhance the user experience by providing an efficient and user-friendly search. This is where searchHub.io comes in.
Efficient
With searchHub’s AI-driven approach, businesses can improve their site search regardless of their existing solution. searchHub’s AI-powered algorithms translate user phrases into the best possible search query, leading to higher conversion rates and a better user experience. Additionally, the tool provides an in-depth representation of all search activities, helping businesses efficiently improve their search experience.
Flexible
Flexibility is another critical aspect of searchHub.io. It can be integrated with any site search solution, saving time and resources while allowing businesses to customize their search experience according to their specific needs.
Transparent
Transparency is also a key feature of searchHub. The tool provides businesses with a unique view of their search data, allowing them to identify trends and understand customer behavior. Businesses that understand their customers’ needs and preferences are more likely to succeed in today’s competitive e-commerce market.
Furthermore, searchHub is the only add-on-solution on the market that can be appended to your current site search in a short amount of time, making it an excellent choice for large-scale e-commerce sites. Speed and agility are critical for large-scale e-commerce sites to stay competitive.
“Our site search is built on Elasticsearch. B2B is known for its challenges, for which there are no standard vendor solutions. searchHub delivers the desired added value to our setup using transparently delivered data.”
Michael Kriz
Automated
This type of automation is key for a modern site search strategy, and here’s why: Imagine the volume of search data generated by online shopping, which is increasing rapidly. It can be challenging for site search teams to analyze and interpret all the information efficiently. By implementing automation within their site search environment, businesses can streamline their operations and reduce the workload on human teams. This frees up time for innovation and experimentation, allowing businesses to focus on more strategic tasks.
“searchHub makes it easier for us to guide customers through our assortment. We control our search solution even better because of intelligent long-tail clustering. We now have less effort to maintain our merchandising campaigns, and the search analytics are more transparent. The value per session increased, ad-hoc, by more than 20%.”
Dominik Brackmann
Conclusion
In conclusion, searchHub.io is a unique tool that helps businesses enhance their site search experience independently of their existing solution. Its focus on efficiency, flexibility, and transparency makes it a valuable addition to any e-commerce business looking to increase conversion rates and improve the user experience. Its AI-powered algorithms and data-driven approach provide businesses with unique insights into their search data, helping them to optimize their site search and keep up with customer preferences. By investing in searchHub, e-commerce businesses can stay flexible and innovative, making it a must-have for any modern e-commerce strategy.
The trend towards automation and AI-powered tools in site search is likely to continue, as businesses seek to streamline their operations and focus on more strategic tasks.
wir freuen uns sehr, Dir die Einführung einer revolutionären neuen Methode zur Ermittlung des besten Suchbegriffs ankündigen zu können. In dieser Post möchten wir Dir die neuen Funktionen vorstellen und zeigen, wie sie Dein tägliches Arbeiten noch zielführender machen.
Bisher wurde der repräsentativste Suchbegriff innerhalb eines Varianten-Clusters vor allem anhand der KPIs CTR (Klickrate) und CR (Kaufrate) ermittelt. Mit unserer neuen „Best Query Picking-Technology“, haben unsere Kunden die searchCollector integriert haben zwei neue KPIs, über die sie sich freuen dürfen: Findability und Sellability.
„Findability“ ist ein KPI, der positives und negatives Nutzerfeedback, wie Klicks und Views, aber auch zusätzliche Informationen wie nicht geklickte Produkte, zu viele Filter, und Seitenausstiege berücksichtigt. „Sellability“ hingegen misst alle angeklickten Produkte, die in den Warenkorb gelegt oder gekauft worden sind. Diese einzigartige Kombination von KPIs stellt sicher, dass für jedes Suchbegriffscluster die leistungsfähigste, beste Schreibweise ausgewählt wird. Auf dieser Weise wird transparent, welchen Einfluss die Relevanz eines Suchergebnisses auf das Kaufverhalten der Nutzer hat.
Maximale Transparenz ist uns wichtig. Deswegen haben wir die KPI „Reliability” eingeführt. Diese misst, wie zuverlässig die KPIs der Vergangenheit für eine bestimmte Suchbegriffs-Variante sind. Dies geschieht, indem wir Varianten mit aktuelleren Daten höher gewichten als Varianten, zu denen es ggf. schon seit längerer Zeit keine neuen Daten gibt.
Zwei weitere neue KPIs in der Benutzeroberfläche werden Dir sicher auch noch auffallen: “Popularity” und „Sample Size“. Die Popularity misst, wie oft in den vergangenen 28 Tagen ein Suchbegriff gesucht wurde. Die Sample Size ist die Häufigkeit der ungemappten Suchen, die wir aus verschiedenen Zeiträumen erfasst haben. Alle restlichen KPIs beziehen sich auf diese Häufigkeit.
Diese Änderungen werden sich auf die Cluster-Ansicht auswirken, die genau angibt, welche Cluster und Varianten zusammengehören und warum. Es ist wichtig zu beachten, dass die Cluster-Ansicht keine Analyse ist, sondern vielmehr eine Steuerungszentrale, um die Qualität der Suchergebnisse zu beeinflussen. searchHub gibt Dir hier volle Kontrolle über Suchbegriffsbeziehungen.
Für Kunden, die unsere searchInsights abonnieren, geht eine detaillierte Analyse der Suchmaschinen-Performance leicht von der Hand. Hast Du schon den neuen Date-Picker oder die Vergleichsmöglichkeit entdeckt?
Hast Du noch keine searchInsights und bist auf der Suche nach einer detaillierteren Analyse der Suchmaschinen-Performance, mit granularem, beispiellosem Suchmaschinen-Tracking, solltest Du Dir unser Modul searchInsights anschauen. Dies ist das optimale Vorgehen, um Deine Suchmaschine in ein Business-Tool zu verwandeln.
Wir hoffen, Du bist von diesen Änderungen genauso begeistert wie wir. Diese werden am 15. März im searchHub UI sichtbar sein. Vielen Dank für Dein Vertrauen in searchHub!
Beste Grüße Dein searchHub Team
English Version
The New Standard for Search Optimization
We are thrilled to announce the launch of our revolutionary new way to identify the most representative search term for a given query cluster. Today, we’re sharing these exciting new features and how they benefit your business.
Traditionally, identifying the most representative query within a query cluster was done using the KPIs CTR and CR. Now, we’re doing something different. For our customers using our searchCollector, our Query Picking Technology, introduces two new KPIs: Findability and Sellability.
“Findability” is a KPI that measures positive and negative user feedback, such as clicks and views, but also considers products that aren’t clicked. “Sellability”, on the other hand, measures all clicked products, which are either added to the basket or purchased. This unique combination, ensures the highest performing, best query, is picked for each query cluster.
Additionally, we are introducing a new KPI called “Reliability”, which measures how representative past KPIs are for a given keyword variant, within a cluster. This ensures the best performing query is always chosen over any period. We do this by weighting recent keyword data (interactions) higher than older keyword data. Surely, you won’t miss two additional new KPIs in the UI: “Popularity” and “Sample Size”. Popularity measures how often a query was searched in the last 28 days. The “Sample Size” is the frequency of the unmapped queries, which we gathered across different time periods. All other KPIs build on the search term frequency that comes from “Sample Size”. These changes will affect the query cluster view, and more precisely communicate which clusters and variants belong together and why. It’s important to note that the Query Cluster view is not an analysis, but rather a command center to influence the search result quality. searchHub allows you the complete control.
For our customers, already subscribing to our searchInsights module: you already have the most detailed analysis possible of search engine performance. Have you discovered the Date-Picker and comparison functions yet?
If you’re not yet using searchInsights, but you’re looking for a more detailed analysis of your search engine performance, with granular, unparalleled search engine tracking, please consider adding our searchInsights to your current searchHub subscription. This is the way to go if you’re looking for a way to turn your search engine into a business tool.
We hope you’re as excited about these changes as we are. They’ll be live in the searchHub UI on March 15th. Thank you for your trust in searchHub. Best regards,
In 2017 we officially launched searchhub.io. Now 5 years later, it’s time for a recap and some updates regarding our goals, strategy, and product.
Has the Search Game Changed?
Maybe in scale, but certainly not in terms of goals and purpose. Search Engines still act as filters for the wealth of information available on the Internet. They allow users to quickly and easily find information that is of genuine interest or value to them, without the need to wade through numerous irrelevant web pages. However, they are built based on concepts that store words or vectors and not their meaning. Screen real estate is going to zero, and the way people can interact with digital systems has evolved from keyboard only to keyboard, voice, images, and gestures. All of these input types are error-prone and don’t include context. A well done site search, however, should cater to these errors and automatically add available context to come up with relevant answers.
Therefore, our motivation hasn’t changed. In fact, we are now even more convinced that there is an almost endless need and opportunity for Fast & Relevant search.
Our motivation “FAST & RELEVANT SEARCH” helps to craft meaningful search experiences for the people around us, this mission inspires us to jump out of bed each day and guides every aspect of what we do.
Was Our Entirely New Approach with searchHub.io a Success?
1. It Works Site Search Platform Independent…
…definitely yes. We still see a growing set of different search engines out there, and all of them have their pros and cons. Often the reason a specific search engine was chosen has nothing to do with the ability to successfully fulfill the basic use case of search. In more complex scenarios, there could even be a set of different search engines in production, each fulfilling a different use case. That’s why we designed searchHub as a platform independent proxy that automatically enhances existing site search engines by autocorrecting, aligning human input and building context around every search query in a way your search engine understands.
2. Enhance, Not Replace
…absolutely yes. Search Engines are becoming an even more integral part of modern system backbones and are in most cases very hard to replace. But “search” as we know it is already changing because modern technology has set today’s customers very high expectations; they know what they want, and they want it now. More and more retailers have started investing in their own, business-case adapted, Search & Discovery Platforms. And they continue to add new in-house features like LTR (Learning-to-Rank), personalization, and searchandising more frequently than ever before.
Therefore, we decided early on that we are not aiming to replace these platforms and instead focus on how we can enable our customers to achieve even better results with what they have now or in the future at scale. That’s precisely why the technology behind searchHub was specifically designed to enhance our customers’ existing site search, not replace it. The primary component is still our Lambda-Architecture that enables us and our customers to separate model training from model serving.
3. The Lambda-Architecture Choice
This architecture gives our customers the freedom to deploy our smartQuery Serving-Layer wherever they want, reducing latencies to the bare minimum (<1ms 99.5 conf interval) as there is no additional internet-latency. While it gives us the freedom to entirely focus on efficiently building & training the best available ML-Models consumed by the Serving-layers asynchronously. This freedom to deploy and operate such a thin client is one of the most appreciated features of searchHub and one key reason for our short integration times.
This architecture also enables our users to modify these models and deploy them to production without any IT-involvement on their end. Giving Relevance-Engineers, Data-Scientists and Search-Managers almost instant influence and optimization capabilities for their search & discovery platform.
4. AI-Powered Search Query Rewriting Is The Best Starting Point…
Again yes. Of course, at first glance we could have focused on more “fancy” areas of search, but the initial focus on thoroughly understanding the user-query was one of the best decisions we made. Why? Because you can’t control your users’ queries – they express their intent in their terms – and there is nothing you can do about it. Matching users’ intent to your document inventory is the key part of every search process. Therefore, it just felt natural to start here, even though it’s the most challenging part.
Once we had a solution to this problem in place, we were shocked at the additional benefits and opportunities that surfaced. The sparsity in behavioral data is automatically reduced, it removes 1000s of hours of manual curation and optimization whilst enabling more stable and consistent results. That’s why we are still investing significant effort into furthering this part of the platform, as every minor improvement here compounds up to the different down-stream tasks.
This year we will have processed over 25 billion searches resulting in almost 750 Million unique search phrases across 13 languages, empowering our customers to generate well over 5 billion € in GMV (Gross Merchandise Volume). All of that with a purposefully, minimal, highly skilled Dev and Dev-ops Team.
Time To Update You On Our Journey So Far
1. From Ok Data To Great Data
Since we work mainly with behavioral data, we depend heavily on the quality of their sources. Whilst almost everybody out there thinks that systems like Google Analytics, Adobe Analytics and others should be perfect sources, we learned the hard way that this is absolutely not the case. Therefore, we had no other choice as to build our own Analytics Stack (a combination of our searchCollector and searchInsights). At the beginning it was tough to convince our customers or potential customers that they needed it, but as soon as we were able to show them the difference, they directly fell in love. Being able to accurately track your search & discovery features, and getting direct feedback for potential improvements in consolidated views, not only gave our customers a 3-fold increase in operational efficiency but also dramatically improved the results delivered by searchHub.
2. Reducing The Noise From Search-Suggestions
Another area where we had to act were search-suggestions. We again assumed that state-of-the-art systems should have already solved the search-suggestions use case, but it turned out they did not. To correctly understand user intent, you first have to intercept it. However, a lot of search-suggestion systems negatively influenced user search behavior and there was nothing we could do about it. That’s why we built smartSuggest, and again it turned out to be a massive success. Not only does it handle the usual use case in a more efficient, consistent and less error-prone way, it also enables our searchHub users to instantly influence suggest behavior in terms of results and ranking again without any internal IT involvement.
3. The Bumpy Road To Transparency And Simplicity
Although our intent-clustering is very, very precise, it was always a black-box for customers and searchHub-users. For one, they wanted to, at least, get an idea about what’s going on under the hood. And secondly, they wanted to directly incorporate their expertise into the system. Everybody involved in ML (Machine Learning) is aware of how complex it is to explain why the systems do what they do. But we found a way by creating what we call “meta-patterns”. Things like this change was done because the engine has certain knowledge about the case, vs. this change was implicitly learned by observing this particular behavior. We now tag every change in the clustering pipeline with one or multiple of these patterns, giving our customers maximum transparency.
Additionally, we found a very efficient way for our customers to add their domain knowledge to the system without them having to take care of the little ugly details and pitfalls. We officially call this feature AI-Training, while our customers call it “Search-Tinder”. Because it follows the same basic UX principle of is there a match or not.
4. Encode It If You Can
Another colossal pile of work which was mostly done under the radar is represented by our newly introduced smartSearchData-Service, which is still in beta-status. If you frequently follow us, you might already be aware that searchHub was always limited by the quality of the underlying search platform. This means that for a given Intent-cluster we were only able to automatically pick the best available query, but we were unable to further improve the result for this query. Of course, we could have gone all-in on query-parsing (automatically building more complex search-platform dependent queries) but this would only have been possible with massive downsides for our customers and us. Chiefly among them: the implementation-effort would have exploded. But not only that, we would have limited the freedom of our users to improve their Search & Discovery platforms on their own.
That’s why we again decided for a radically different approach. While query processing is different for almost any site search platform, their underlying structure of indexable objects is not so different. So, what if we could somehow encode the needed additional information (to get better results for a given query) directly into the indexable objects without the need to dramatically change the query processing? That’s precisely what we do right now. It might not be a complete feature yet, and we may still face some real challenging problems in these areas, but the results so far are very encouraging.
Closing Comments
We as a team are really proud of what we have achieved, and we know it’s just the beginning. All of us are genuinely grateful and thankful for all our fantastic customers, users, partners, and fans out there which made all of this possible. It’s their feedback, and patronage, that keeps the wheel spinning and the lights on. Therefore, we hope that all of you are as eagerly looking forward to the next 5 years as we are.
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.