In one of our latest blog posts, my colleague Andreas highlighted how session-based segmentation in A/B-tests might lead to wrong conclusions. I highly recommend you read his post before continuing. In this blog post, I’ll show how session-based analysis in A/B-tests will destroy your precious work when optimizing site search.
tl;dr: If your business case involves only single-item baskets and 90% of your orders consist of only one article, you can skip this post.
All others: welcome to another trap in search experimentation!
Measuring the Unmeasurable
Let’s say you and your team put significant effort into optimizing your product rankings for search result pages (SERP). Most of the formerly problematic SERPs now look much better and seem to reflect the requirements of your business more than before. However, if your key performance indicator for success is “increase shop revenue through onsite search”, you’d be short-changing yourself and jeopardizing your business’s bottom-line. Let me explain.
First of all, it’s a good thing that you understand how crucial it is, to test changes in the fundamentals of your onsite search algorithm. I mean, it’s clear that these changes influence lots of search results, which you would never even think about. Let alone be able to judge personally. And proving the quality of your work might also influence your personal bonus. That’s why you do an A/B-test before rolling out such changes to your whole audience. You do that, right? Right???
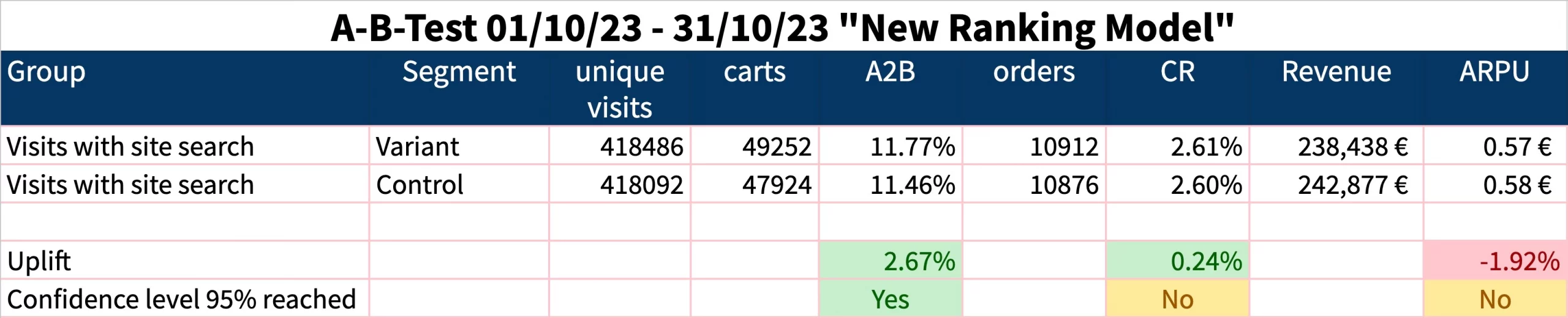
Well, after a while, you check the results in your A/B-test or analytics tool. Following standard best practices not only of Google Analytics but also many (if not all) web analytics tools, the result might look like this:
(report showing ambiguous results: Although AddToBasket-ratio increased significantly, no significant increase in overall conversion rate was measured, while revenue decreased slightly).
What will your management’s decision be based on this result? Will they crack open a bottle of champagne in your honor, as you obviously have found a great option to increase revenue? Will they grant you a long – promised bonus? Most likely not, unfortunately. A glass of water will suffice, and you should be thankful for not being fired. After all, you shrank the revenue.
The problem: You didn’t test what you intended to test.
What you wanted to test: how each search result page performs with your new ranking algorithm compared to previous rankings.
What you actually tested: All carts and orders of all users who happened to perform at least one site search during their visit.
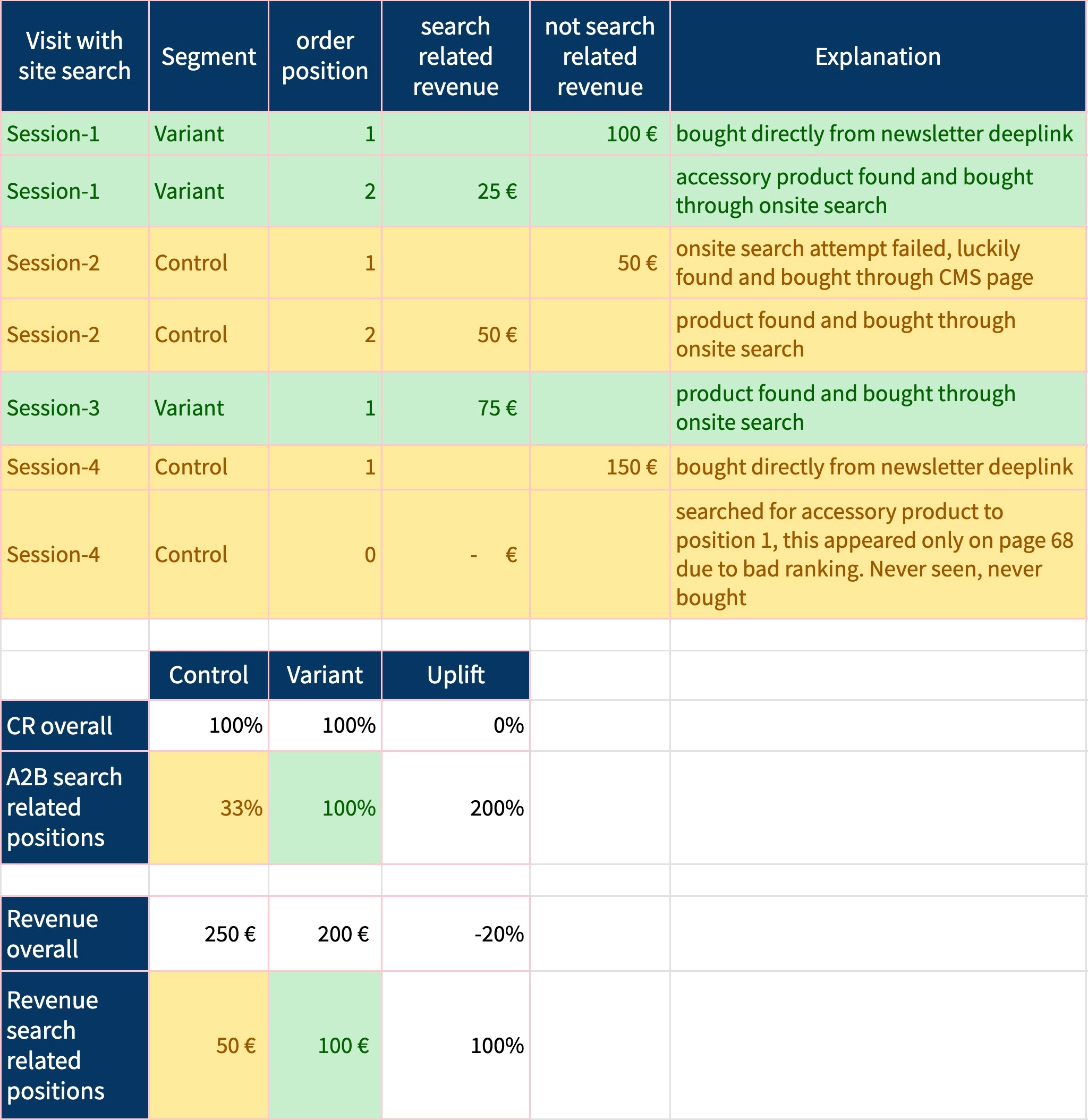
Imagine you were able to show your management a detailed view of all search-related sessions, with specific explanations of each position in the basket that was really driven by search requests. Which products were not bought because they could not be found? Which other products were bought but not search related?
Maybe similar to this example here:
(detailed view of search related sessions showing improved search performance when measured directly)
Chances are high that someone will tap on your shoulder stating: “We see very nice improvements to our customer journeys where search is involved. You did an awesome job optimizing the search.”
So what happened here?
A vast majority of visits will not start with a customer thinking: “Such a nice day. I’d finally like to use the search box in myfavoriteshop.com”. Instead, they will reach your site via organic or paid links or click on a link in your newsletter promoting some interesting stuff – well, you know all the sources where they come from, that’s potatoes for your analytics tool.
In many cases, the first product to be put into the basket is more or less easy going. But now they start to think: “I’ll have to pay €5 for shipping, what else could I order to make it worth it?” Not only does search become interesting at this point, but your business begins creating opportunities. Larger order – higher margin, as your transaction costs sink. A well-running search engine might make the key difference here. But, do not attribute the revenue of the first cart position to the search engine, as it had nothing to do with it!
If your analytics or A/B-testing tool shows some report starting with “visits with site search”, a red alert should go off in your head. This is a clear indication that the report mixes up a lot of stuff unrelated to your changes.
Why is this a problem?
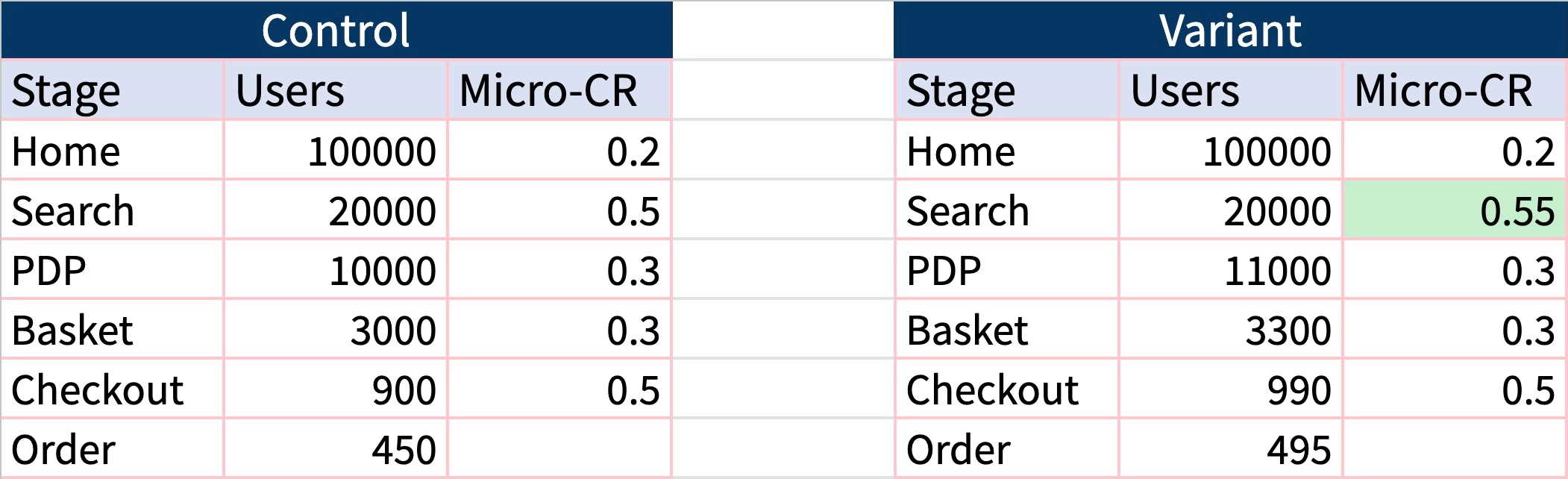
Search is important for your e-commerce site’s success. Because statistics love large numbers. It’s true, search provides large numbers, but order numbers are much smaller. Let me give you a simplified, but nevertheless valid example: Let’s assume your search has improved by 10%. Naturally, this should also be visible as a 10% increase in orders overall:
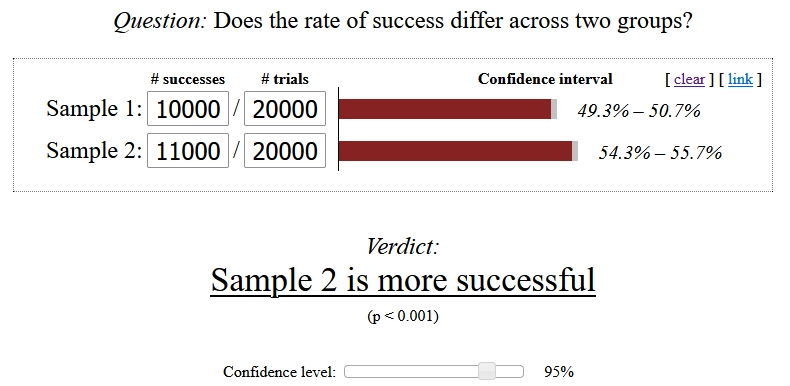
Now we can ask statistic tools if this is significant. (You might want to start with here). The result may come as a surprise.
(While CTR increased significantly, the increase is not strong enough for a significant increase in CR)
What? It affects my orders the same as my search overall (10% or 45 more orders), but it’s not significant? That’s because statistics want to provide a rather failsafe result. The lower the numbers and the smaller the relation between success (an order) and trials (each user), the harder the proof for an increase.
So chances are high that your A/B-test tool will consider the result as “insignificant” when trying to find the signal in the generic data. If you are Amazon or Google, this is not a problem you need to bother with – your numbers are large enough. Everyone else is obliged to dive deeper into the data.
How do we do this at searchHub?
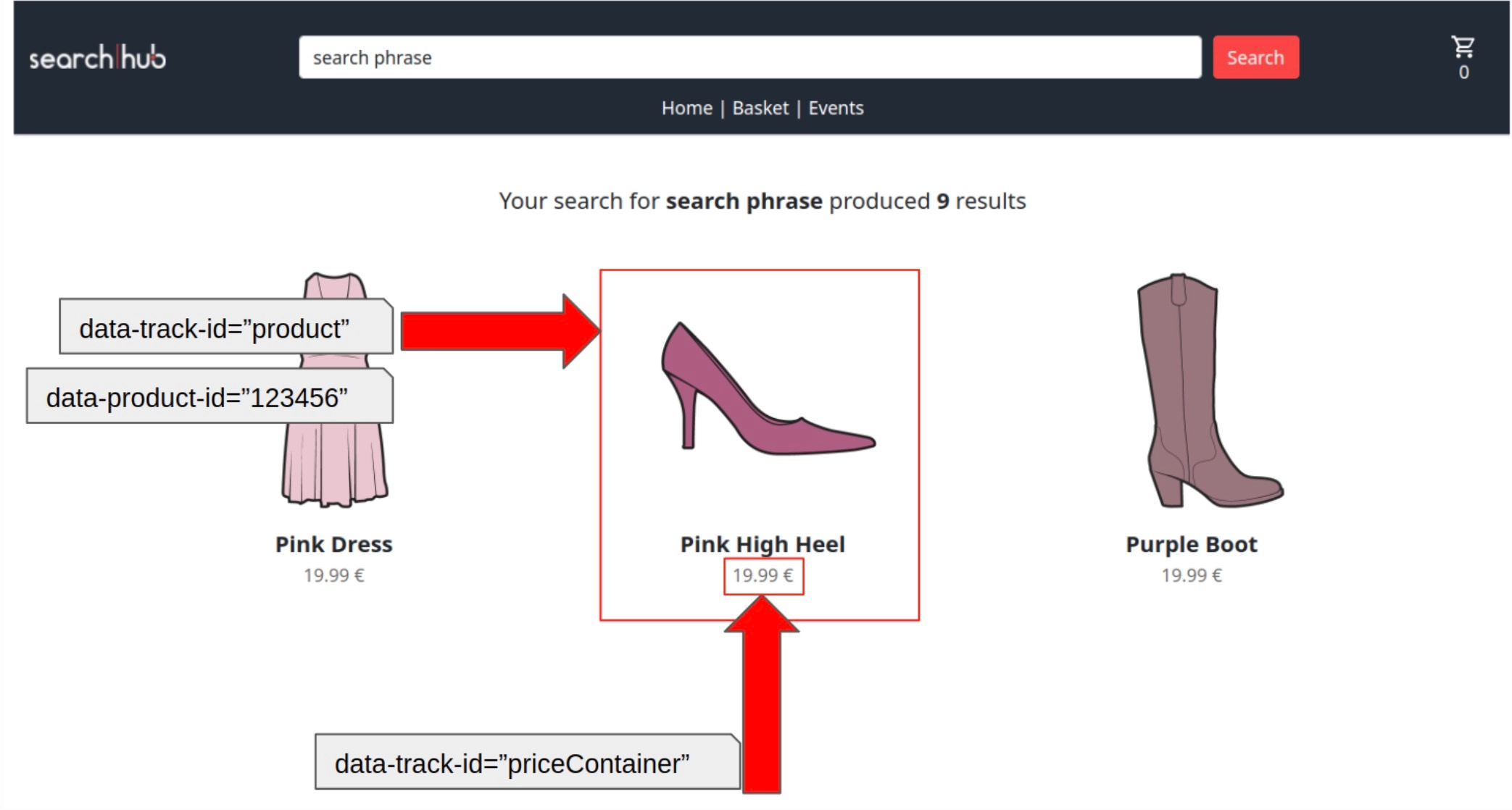
Over the past years, we have built a powerful framework to track search related events. Our searchCollector can be easily integrated into any e-commerce site. Without tracking any personal data, but very high consent ratios, we can collect traffic from most of your customers. We precisely track the customer journey from the search bar to the basket, also identifying when this journey is interrupted and a new, non-search-related micro-journey begins:
This allows us to capture search-related KPIs in the most precise way. Not only can this be used for your daily search management work, but also for fine-grain A/B testing. By eliminating erroneous effects like non-search-related basket positions, we show exactly and with high statistical accuracy, how changes in your search algorithm, search engine or even search configuration perform.
OK, understood – what can I do?
First: Make sure you’re precisely measuring the stuff you want to be measured.
Second: Don’t rely on summarized numbers, when you know that they include customer decisions that you cannot influence.
Third: Remember that in a random setup, 5% of all A/B tests will prove a significant difference. That’s what alpha=0.05 in your testing tool or A/B-test report means.
Experimentation plays a pivotal role in search systems. It has the capability to improve performance, relevance, and user satisfaction. An effective search system is a must in this dynamic digital landscape. It needs to continuously adapt to meet the evolving needs and preferences of users. Experimentation provides a structured approach for testing and refining various components. Some common examples are algorithms, ranking methods, and user interfaces. Methods like controlled trials, A/B testing, and iterative enhancements, make search systems robust. In this way, search parameters are fine-tuned, innovative approaches assessed, and search result presentation optimized. Not only does experimentation enhance the precision and recall of search results. Using the correct experimentation method enables adaptation to emerging trends and user behaviors. As a result, embracing experimentation as a fundamental practice empowers search systems to deliver accurate, timely, and contextually relevant results. This enhances the general user experience. It’s no wonder that A/B tests are the gold standard for determining the true effect of a change. Even so, many statistical traps & biases can spring up when tests are not set up correctly. Not to mention that the approach to A/B testing for search is not one-size-fits-all. It’s rather a science that requires careful consideration. In the following text, I will highlight some of the most common A/B test pitfalls we’ve encountered in the past decade in connection with onsite search.
Your Test Is Too Broad, Pitfall.
Small changes to your search configuration won’t impact the majority of your search traffic. Validation of these changes turns into a challenge. Especially when taking all traffic into account. To address this issue, segment your search traffic based on the affected queries. Then evaluate them selectively. Failing to do so may dilute the effects of the changes when averaged across all queries. As an example, there’s a growing trend to confirm the positive impact of vector search on key performance indicators (KPIs). If we focus solely on Variant A (without vector search) and Variant B (with vector search), nearly 90% of the tests showed no significant differences. However, when we segmented the tests based on specific criteria, such as queries containing more than five words, the differences were statistically significant. This underscores the importance of analyzing subsets of your search traffic. In this way, you capture meaningful insights when assessing the impact of configuration changes. So to gain more useful insights, you need to report results across all segments. It’s important to remember that we’re talking about averages. Positive in sum doesn’t mean positive for everyone, and vice versa. Always slice your data across key segments and look at the results.
Focusing exclusively on late-stage Purchase Funnel KPIs – introducing a Carry-Over Effect, Pitfall
In challenging economic climates, businesses prioritize revenue and profitability to ensure sustainability. This is also our observation. A growing number of clients focus on experimentation. They rely on Average Revenue Per User (ARPU) as their primary success metric. As a result, recognizing some fundamental challenges with ARPU attribution bear mention. For example, ARPU has a direct impact on causality, affecting result accuracy.
Some Background on A/B Testing and Randomization:
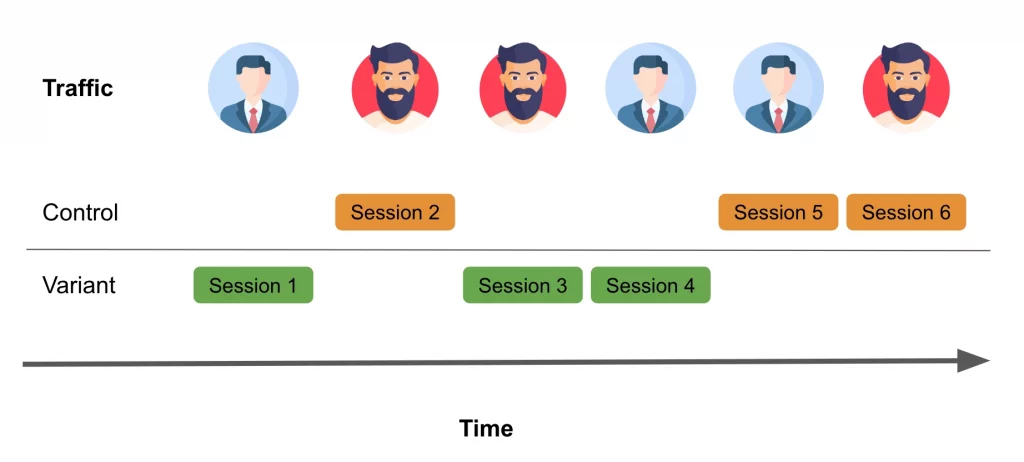
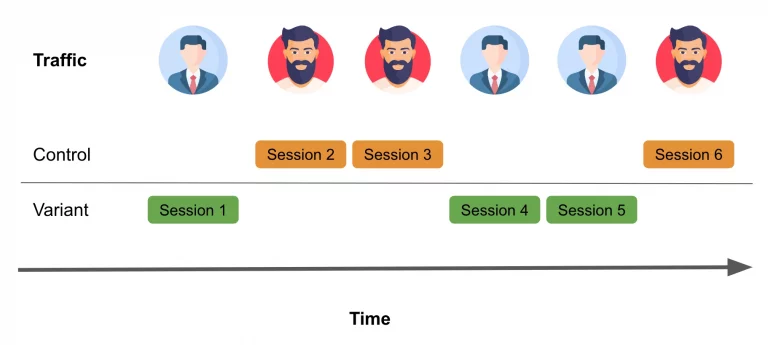
A/B tests, or experiments, test several variants to determine the best performer. One audience group receives the original variant. This is the “control”. At the same time, another group receives a new variant that differs in some way from the control. This group is the “treatment”. An essential aspect of conducting an A/B test is determining how to define these two groups. Picture comparing two website versions to determine which benefits your business more. You would, first, split your target audience into two equal parts at random. Then, give each group a different experience by selecting the appropriate randomization method. The three most common methods are:
Page Views: select either version A or version B at random for each displayed page.
Sessions: are a series of page views grouped by user over a specific time-frame. Session-level randomization shows either version A or B during a session.
Users: Users represent individuals or close approximations. Logging in provides clear identification with a userID. Cookies work for sites without logins, but you lose them if cleared, devices switch, or the browser is changed. That’s why they remain an approximation. In user-level randomization, users view either version A or B consistently.
Defining variant groups requires careful consideration of the independence of your randomization units. When selecting decision criteria or KPIs like ARPU, there’s a hidden risk of carry-over effects. Let’s delve into this, as it plays a pivotal role in choosing between session and user-level randomization.
Independence Assumption of randomization units
Session-level randomization is an approach frequently employed, especially in the context of e-commerce websites. It can be combined with easily accessible metrics such as session conversion rate, which measures the percentage of sessions that result in a purchase. When implementing session-level randomization for your experiment on an e-commerce site, the process might resemble the following:
Consider the following scenario: Aaron visits a website and initiates a session randomly assigned to the control group, experiencing version A throughout that session. Meanwhile, Bill visits the same site but is exposed to version B during his session.
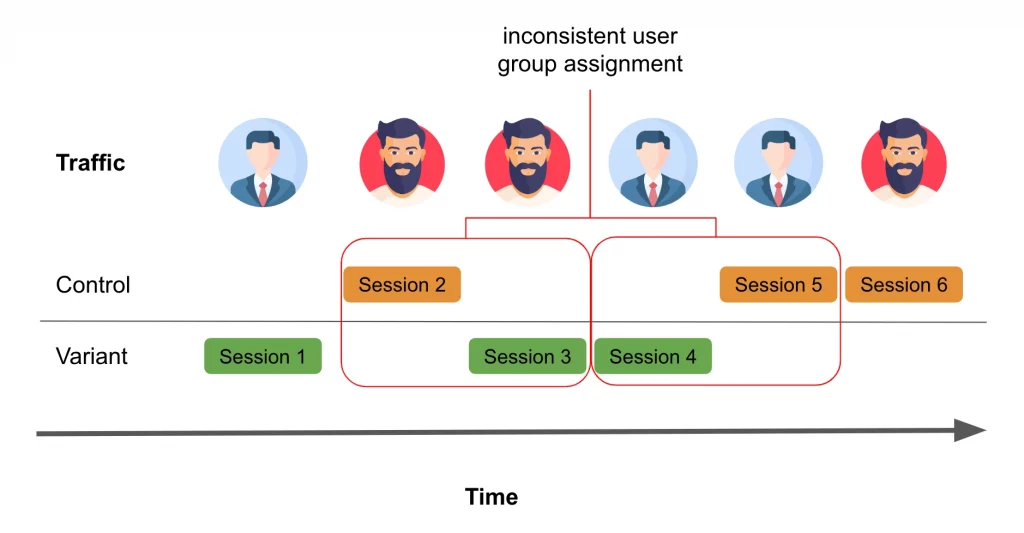
Later, Bill returns to the site on a different day, starting a new session that, by chance, is assigned to the version A experience. At first glance, this may appear to be a reasonable approach. However, what if Bill’s decision to return to the website was influenced by the version B experience from their previous session?
In the realm of online shopping, it’s not unusual for users to visit a website multiple times before making a purchase decision. Here lies the challenge with session-level randomization: it assumes that each session is entirely independent. This assumption can be problematic because the driving force behind these sessions is people, and people have memories.
To illustrate this issue further, let’s consider an example where we conduct an A/B test on a new product recommendation algorithm. If the treatment group experiences the new algorithm and receives a recommendation they really like, it’s probable that their likelihood of making a purchase will increase. However, in subsequent sessions when the user returns to make that purchase, there is no guarantee that they will fall into the treatment group again. This discrepancy can lead to a misattribution of the positive effect of the new algorithm.
Randomization at the session level, where each session is treated independently.
Let’s construct a simple simulation to explore scenarios like these. We’ll work with a hypothetical scenario involving 10,000 users, each of whom averages about two sessions. Initially, we’ll assume a baseline session conversion rate of approximately 10%. For sessions falling into the treatment group (version B experience), we’ll assume an uplift of around 2%, resulting in an average conversion rate of approximately 12%. For simplicity, we’ll make the initial assumption that the number of sessions per user and the session conversion rate are independent. In other words, a user with five sessions has the same baseline session conversion rate as someone with just one.
To begin, let’s assume that sessions are entirely independent. If a user like Bill experiences version B (treatment) in one session, their probability of converting during that session will be around 12%. However, if they return for another session that is assigned to the original version A experience (control), the session conversion rate reverts to the baseline 10%. In this scenario, the experience from the first session has no impact on the outcome of the next session.
Please refer to the appendix for the code used to simulate the experiment and the corresponding Bayesian implementation of the A/B test. After conducting this experiment multiple times, we observed the following results:
The A/B test correctly identifies a positive effect 100.0% of the time (with a 95% “confidence” level).
The A/B test detects an average effect size of 203 basis points (approximately 2%).
When sessions are genuinely independent, everything aligns with our expectations.
Randomization at the session level, considering non-independent sessions.
However, as previously mentioned, it’s highly improbable that sessions are entirely independent. Consider the product recommendation experiment example mentioned earlier. Suppose that once a user experiences a session in the treatment group, their session conversion rate permanently increases. In other words, the first session assigned to the treatment group and all subsequent sessions, regardless of assignment, now convert at 12%. Please review the implementation details in the appendix. In this modified scenario, we made the following observations:
The A/B test correctly identifies a positive effect 90.0% of the time (with a 95% “confidence” level).
The A/B test detects an average effect size of 137 basis points (approximately 1.4%).
With this “carryover effect” now in place, we find that we underestimate the true effect and detect a positive impact less frequently. This might not seem too concerning, as we still correctly identify positive effects. However, when handling smaller effect sizes, situations arise where this carryover effect leads to a permanent change in the user’s conversion. This causes us to completely miss detecting any effect. It’s essential to emphasize that this analysis explores the most extreme scenario: 100% of the effect (the 2% increase) carries over indefinitely.
Randomization at the user level
Opting for user-level randomization instead of session-level randomization can address the challenges posed by non-independent sessions. To circumvent the issues encountered with session-level randomization, we must make the assumption that the users themselves are independent and do not influence each other’s decision to convert. Let’s consider our loyal shoppers, Aaron and Bill, as an example of how user-level randomization would function:
In user-level randomization, each user consistently receives the same experience across all their sessions. After rerunning our simulation with user-level randomization and maintaining the same “carryover effects” as before, we observe the anticipated results:
The A/B test correctly identifies a positive effect 100.0% of the time (with a 95% “confidence” level).
The A/B test detects an average effect size of 199 basis points (approximately 2%).
With user-level randomization, we regain the expected outcomes, ensuring that users’ experiences remain consistent and independent across their sessions.
Recommendations…
If you suspect that your sessions may lack independence and could exhibit some carryover effects, it’s advisable to consider randomizing at the user level. Failing to do so may lead to an inaccurate estimation of the genuine impact of a particular change, or worse, result in the inability to detect any effect at all.
The magnitude of this issue will largely hinge on the specific domain you’re operating in. You’ll need to critically assess how substantial the carryover effects could be. Furthermore, the impact level will be influenced by the distribution of sessions within your user base. If the majority of your users visit your platform infrequently, on average, then this concern is less pronounced.
It’s important to note that user-level randomization typically involves the use of cookies to identify users. However, it’s worth acknowledging that this approach does not guarantee unit independence. Cookies serve as an imperfect representation of individuals because a single person may be associated with multiple “user cookies” if they switch browsers, devices, or clear their cookies. This should not deter you from implementing user-level randomization, as it remains the best method for mitigating non-independence and ensuring a consistent user experience.
Tip: Apply Guardrail Metrics Given that these challenges described are prevalent in the majority of experiments and are challenging to eliminate, we have discovered an effective ensemble approach to minimize erroneous decisions. Rather than concentrate solely on late-stage purchase funnel Key Performance Indicators (KPIs), it is advisable to augment them with earlier stage guard-rail KPIs. For instance, in addition to Average Revenue Per User (ARPU), it is recommended to incorporate Average Added Basket Value Per User (AABVPU). When conducting an experiment, if you observe a substantial disparity between these two KPIs, it may indicate an issue with assignment persistence. In such cases, making decisions solely based on the ARPU metric should be avoided without further investigation.
In closing, it’s important to emphasize that, in light of the potentially devastating consequences if rash business decisions are made on the back of faulty A/B testing, we concede that this approach doesn’t offer a foolproof solution to our challenges as well. We must navigate within the constraints of our imperfect world.
Apendix
All code needed to reproduce the simulations used can be found in this gist.
In the world of online shopping, customers often start their search with a product’s brand name. For ecommerce retailers, it is essential to lead this “brand search” traffic to a dedicated landing page that highlights the associated products and provides a seamless user experience.
Site search is an essential aspect of ecommerce, especially on mobile devices, where customers may prefer to search for products rather than browsing through multiple pages. But retailers, and their ecommerce directors, are strapped for time and resources. It’s no wonder that Baymard Institute, found 70% of ecommerce sites fail to provide a satisfactory search experience. So if you’re looking for just one thing to change about your site search, how about optimizing brand searches? Imagine the customer experience improvement and increased likelihood of conversions simply by optimizing brand searches within your site search. Baymard goes on to discuss the importance of testing and measuring the effectiveness of site search to continuously improve it. We may all have heard it a thousand times over, after all, site search optimization is not a new topic. And, even still, shops are failing at this elusive task. Thankfully, Baymard continues to beat the drum, driving us all to a more focussed and mature understanding of what brings the greatest gains in online retail optimization.
It’s safe to say that the road to measurable customer journey optimization and employee resource allocation is achieved by clearly understanding both how customers use your webshop, and secondly, how to improve their journey, today.
Site Search – Understand How Customers Interact with Your Shop
How do you efficiently get a better picture of site search resources (tech and employee time spent) to make better decisions regarding which optimizations need to be prioritized and identify any missing functionality
Site Search Performance Measurement
Number one: Can you accurately measure your site search performance? Onsite search is notoriously broken. Retailers continuously optimize site search issues that don’t bring the expected return. This is largely due to the proliferation of Google Analytics. A cheap tracking and analytics solution that comes at the cost of accurate insight. This is no fault of its own. GA does not purport to be the ideal solution for onsite search tracking and analytics. But that doesn’t keep retailers from treating it that way.
Imagine a way to track onsite search customer journeys without sessions being lost or unable to rationalize search revenues as a result of filters being set, customers using the browser “back” button, or an onsite campaign being triggered. This type of solid, no-nonsense site search tracking technology is the backbone behind searchHub’s search optimization success. This search tracking solution is one-of-a-kind and allows us to track customer search journeys throughout sessions and no matter the underlying site search technology being used.
Site Search – Improve the Customer Journey!
Number two: can you pinpoint what needs to be optimized in your customer’s site search journey and improve it now?
Ecommerce retailers are prepared to optimize anything they can measure. This makes it easy to articulate a business case. But cleanly tracking search, throughout the customer journey, has always been an issue. This increases the challenge of creating a seamless and efficient search experience for customers.
So, now imagine you have a system in place that makes it easy to identify which site search optimizations will provide the greatest uplift in customer satisfaction, based upon how they interact with your webshop. A solution that tells you what to optimize next, no matter the underlying site search technology you use, and provides the tools you need to make the necessary changes now!
That’s searchHub.
Thinking Outside the Search Box
So, let’s assume you’re using searchHub. What types of KPIs would you begin optimizing straight out of the gate? You might be surprised: there are a few aspects of the customer journey which are directly influenced by site search, but not often associated with it.
The following is a short list of where to begin creating a better customer journey by leveraging searchHub to optimize your existing site search.
1. Optimize your site search for brand terms
To ensure that your brand search traffic leads to specifically curated landing pages, you first need to ensure that your site search can handle different variations (e.g. adidas, adadis, addidas, addias, adiddas etc.) of brand names, including misspellings, abbreviations, and different word orders. Additionally, consider adding predictive search suggestions and autocomplete functionality to make it easier for customers to find the brands they’re looking for.
2. Create dedicated landing pages for brand searches
This second point builds on the previous one. Your search can handle any misspelling or variation of the brands in your catalog? Now, the hard work of ensuring a seamless user experience, by creating a dedicated landing page for brand searches, ensues. Landing pages showcase a brand’s products and provide customers with an easy-to-use filtering system that allows them to narrow down their search results. Make sure to include relevant information such as product reviews, ratings, and pricing to help customers make informed purchase decisions.
Intersport Adidas Brand Landing Page
3. Optimize Suggest for Brand Searches
The autocomplete functionality your search engine provides, is often the first interaction customers have with the brands in your shop. Making these visible as early as possible in the customer journey increases the overall shop usability. Retailers can use smartSuggest to train the search algorithm to prioritize brand-related search terms and suggest relevant products. This can be achieved by tagging and categorizing products by brand, and using this information to inform the smartSuggest algorithm. Additionally, retailers can monitor the performance of the smartSuggest feature, using searchInsights, and over time and make adjustments to optimize its performance.
Bergfreunde – Brand placement in smartSuggest.
4. Use retail media ads in site search
Retail media is a form of advertising that allows brands to promote their products on the websites of retailers or marketplaces. By using retail media ads in site search, brands can increase their visibility and drive more conversions. Target the right audience, use relevant keywords, and track the performance of retail media ads to optimize them over time.
Criteo – correct Retail Media placement in a webshop.
5. Use data to personalize the user experience
searchHub’s searchCollector provides a host of search behavior data, giving granular insight into how customers interact with search throughout their journey. What has been placed into, and then removed from, the basket? Which products have been seen but not clicked? Which products bring the most revenue, compared to those with the greatest profit? This anonymous information, tracked no matter the underlying site search technology, provides the ability to personalize search results and suggest relevant products that match customer interests. Not only will this improve the user experience, but also increase the likelihood of conversions.
Conclusion
Unlocking site search potential requires a strategic approach that focuses on customer needs and behavior. Begin by optimizing site search for brand terms, create a dedicated landing page, optimize smartSuggest, use retail media ads in site search, and personalize the user experience using data. By implementing these strategies, ecommerce sites can create a personalized brand experience for their customers, showcase their products effectively, and ultimately drive revenue.
How can language models be used efficiently to scale?
Context and distance determine relevanceLanguage Models (LMs) already have quite some history, however, especially recently, a lot of effort and new approaches have flooded the “dance-floor”. While LMs have successfully been adopted to a variety of different areas and tasks the main purpose of an LM, at least in my understanding remains the same:
“Language Models are simply models that assign probabilities to a sequence of words or tokens”
Even if modern LMs can offer way more than that, let’s use the above definition or description as a foundation for the rest of this blog post.
Language Models – Some background
For quite some time N-Gram Language models dominated the research field (roughly from 1940-1980) before RNNs followed by LSTMs (around 1990) until the first Neural Language Model in 2003 received more and more hype. Then in 2013 Word2Vec, and 2014 Glove introduced “more Context” to the game. In 2015 the Attention Model became popular and finally in 2017, Transformer, which mainly built on the idea of Attention, ultimately became the de facto standard.
Today Transformers in combination with pre-trained Language Models dominate the research field and deliver groundbreaking results from time to time. Especially, when considering multi-modal modeling – (combination of text, images, videos and speech). Transformer models get most of their generalization power from these pre-trained LMs, meaning their expected quality heavily depends on them.
The technical details of these approaches are clearly out of scope for this post. However, I encourage you to take some time to familiarize yourself with the basic concepts found here.
For us as a company the most important question we try to answer when reviewing new approaches or technologies is not just if the new stuff is better, in some sort of metric or maybe completely. We’ll always try to focus on the “why” (why is there a difference) and what part of the new approach or technology is the reason for this significant difference. Ultimately, we want to pick the right tool for the given task.
The Why
When we did this internal review we tried to climb up the ladder starting with the older but most understood, highly efficient N-Gram models and nail-down the main differences (boost factors) of the newer approaches.
Type
Key Differentiator
Explanation
Word2Vec
Context
Context encoded into a vector
Transformer
Self Attention
As the model processes each word (each position in the input sequence) self attention allows it to look at other positions in the input sequence for clues that can help lead to a better encoding for this word.
Concluding the review we were quite surprised to only have spotted two real differentiators, despite the amount of training data they were trained on: Context and Attention.
Efficiency of Language Models
Undeniably, the new kids on the block have some very impressive uplifts in terms of the evaluation metrics. However, the approaches that make use of the Context and Attention concepts, have seen even greater impacts on the computational efficiency of their models, due to the dramatic increase of the amount and complexity of computations.
Granted, business cases conceivably do exist, where the uplift outweighs the computational loss in efficiency, however, none of our customers presented such a case. Even using the most distilled new generation Model we were unable to cut the cost per query to less than 100x times the current cost.
And here are the main reasons why:
Short text. We specialize in search queries. The majority of which are still quite short – 57% of all queries in our dataset are single-word queries, > 72% are two words or less. Therefore, the advantage of contextualized embeddings may be limited.
Low-resource languages. Even shops receiving the majority of their traffic on English domains, typically have smaller shops in low resource languages which also must be handled.
Data sparsity. Search sparsity, coupled with vertical specific jargons and the usual long tail of search queries, makes data-hungry models unlikely to succeed for most shops.
For a Startup like ours, efficiency and customer adoption-rate remain the central aspects when it comes to technical decisions. That’s why we came to the following conclusion:
For all of our high throughput use-cases, like sequence validation, and Information Entropy optimization, we needed significantly more efficient LMs (than the current state-of-the-art models) that still offer some sort of context and attention.
For our low throughput use-cases with high potential impact we might use the Transformer based approaches.
Sequence Validation and Information Entropy Optimization
If you work in Information Retrieval (IR) you are aware of what is called “the vocabulary mismatch problem”. Essentially, this means that the queries your users search for are not necessarily contained within your document index. We have covered this problem several times in our blog as it’s by far the most challenging IR topic of which we are aware. In the context of LMs, however, the main question is how they can help reduce “vocabulary mismatch” in a scalable and efficient way.
We structure our stack in such a way that the intent clustering stage already handles things like tokenization, misspellings, token relaxation, word segmentation and morphological transformations. This is where we try to cluster together as candidates, all user queries that essentially have the same meaning or intent. Thereafter, a lot of downstream tasks are executed like the NER-Service, SmartSuggest, Search Insights, etc.
One of the most important aspects of this part of the stack is what we call sequence validation, and information entropy optimization.
Sequence validation. The main job of our Sequence validation is to assign a likelihood to a given query, phrase or word. Where a sequence with a likelihood of 0 would represent an invalid sequence even if its sub-tokens are valid on their own.Example: While all tokens/words of this query (samsung iphone 21s) might be valid on their own, the whole phrase is definitely not.
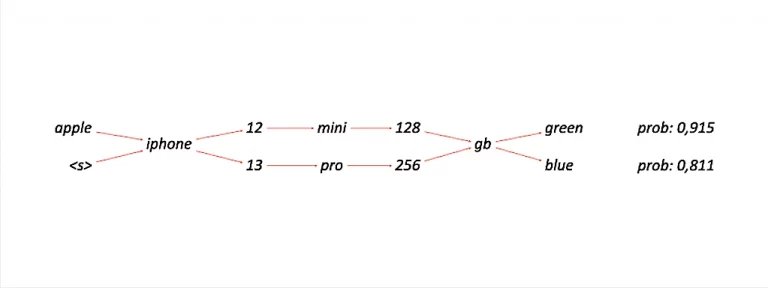
Information entropy optimization, however, has a different goal. Imagine you have a bag of queries with the same intent. This set of queries will include some more useful than others. Therefore the job of information entropy optimization is to weight queries containing more useful information higher than queries with less useful information. Example: Imagine a cluster with the following two queries “iphone 13 128” and “apple iphone 13 128gb”. It should be clear that the second query contains much more identifiable information, like the brand and the storage capacity.
Towards an Efficient Language Model for Sequence Validation and Information Entropy Optimization
Coming back to the WHY. During the evaluation we discovered that Context and Attention are the main concepts responsible for the improved metrics between language models. Therefore, we set out to understand in more detail how these concepts have been implemented, and if we might be able to add their conceptual ideas more efficiently, albeit less exactly, to a classical N-Gram Model.
If you are not aware of how N-Gram Language models work, I encourage you to educate yourself here in detail. From a high level, building an N-Gram LM requires parsing a text corpus into equal amounts of tokens (N-Grams) and counting them. These counts are then used to calculate the conditional probabilities of subsequential tokens and/or N-grams. This chaining of conditional probabilities enables you to compute further probabilities for longer token chains like phrases or passages.
Despite the ability of an N-Gram model to use limited context it is, unfortunately, unable to apply the contextual information contained in the tokens, which make up the n-grams, to a larger contextual framework. This limitation led to our first area of focus. We set out to define a way to improve the N-Gram model by being able to add this kind of additional contextual information to it. There are two different approaches to achieve this:
Increase corpus size or
Try to extract more information from the given corpus
Increasing the corpus size in an unbiased way is complicated and also less effective computationally. As a result, we tried the second approach by adding one of the core ideas of Word2Vec – the skipGrams – taking into account a larger contextual window. From a computational perspective the main operation for an N-Gram-model is counting tokens or n-Grams. Counting objects is one of the most efficient operations you can think of.
However, trying to get decent results makes it obvious that simply counting the additionally generated skipGrams as is, does not work. We needed to find some sort of weighted counting scheme. The problem of counting these skipGrams in the right way, or more specifically assigning the right weightings, is somehow related to the Attention mechanism in Transformers.
In the end we came up with a pretty radical idea, unsure of whether it would work or not, but the implied boost in computational efficiency and the superior interpretability of the model gave us enough courage to nevertheless try.
Additionally, we should mention that all of our core services are written purely in java. This mainly has efficiency and adoption reasons. We were unable to find any efficient Transformer based native java implementation enabling our use cases. This was another reason for us to try other approaches to solve our use-case rather than just plugging in additional external libraries and technologies.
Introducing the Pruned Weighted Contextual N-Gram Model
The main idea behind the pruned, weighted, contextual N-Gram Model is that we expand the functionality of the model to weight co-occurring n-Grams respective of context and type and, in the final stage, prune the N-Gram’s counts.
Weighted Contextual N-Gram Counting
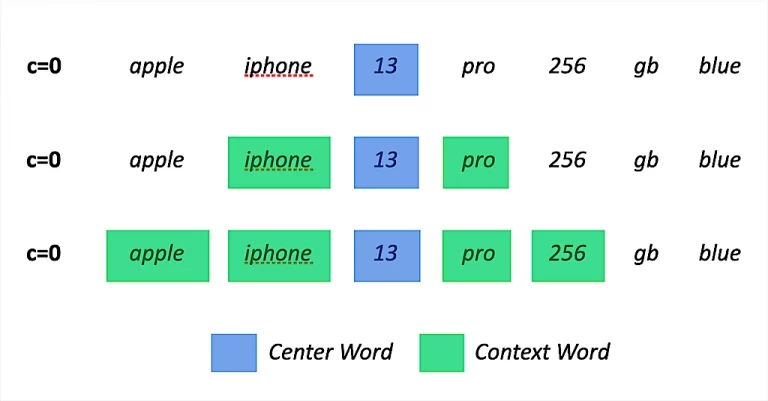
To visualize the idea and approach let’s use a typical ecommerce example. Imagine you have a corpus containing the following passage. “bra no wire with cotton cup b 100”.
N-Gram Generation
From here we would create the following unigrams, bigrams and skipGrams. (Where the skipGrams get deduplicated with the bigrams and we’ll use a context window of 5).
Set of uniGrams
[bra, no, wire, with, cotton, cup, b, 100]
Set of biGrams
[bra no, no wire, wire with, with cotton, cotton cup, cup b, b 100]
Set of skipGrams
[bra wire, bra with, bra cotton, bra cup, no with, no cotton, no cup, no b, wire cotton, wire cup, wire b, wire 100, with cup, with b, with 100, cotton b, cotton 100, cup 100]
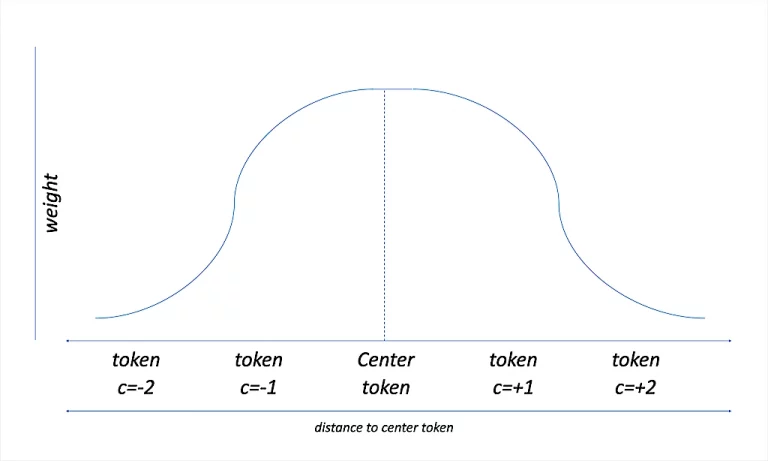
As you can see by using SkipGrams with a defined context window we dramatically increased the number of usable biGrams for our LM. However when it comes to counting them not all of these bigrams from this passage should be considered with the same relevancy.
Weighted Contextual skipGram Generation
To somehow overcome this issue we introduce what we call contextual proximity weighting. During the skipGram creation we penalize the created skipGrams depending on the positional distance to the current context. An example could be that “bra wire” gets a weight of 0.75 while “bra with” gets 0.4 and “bra cotton” gets 0.2 and so on. (the more positions the skipGram skips the less weight it gets). Now instead of purely counting the occurrences we count occurrences and weights of their positional encodings.
Intermediate Result
By adding this contextual proximity weighting we were able to improve the basic n-Gram Model recall by almost 48% with only a slight 7% decrease in precision.
Conceptual Tokenization
But we wanted to go a step further and encode even more information during this stage. Language contains a lot of logic & structure. For example, in the English language the terms “no/without” and “with” are special terms. Additionally “cup b 100” is a pretty special pattern. A lot of this structure and logic is lost by tokenization most of the time, and modern systems have to learn this sort of structure again from scratch during the training process. So what if we could somehow embed this logic & structure right from the beginning in order to further improve our fine grained weighting depending on context. To verify our intuition we extracted around 100 structural or logical concepts to cope with signal-words, and numerical patterns. We apply these concepts during tokenization and flag detected concepts before they enter the N-Gram generation stage where we finally get: “bra no-wire with-cotton cup-b-100”
Set of uniGrams
[bra, no, wire, no wire, with, cotton, with cotton, cup, b, 100, cup b 100]
Set of biGrams
[bra no, no wire, wire no wire, no wire with, with cotton, cotton with cotton, with cotton cup, cup b, b 100, 100 cup b 100]
Set of skipGrams
[bra wire, bra without wire, bra with, bra cotton, without wire, without with, no cotton, no with cotton, wire with, wire cotton, wire with cotton, wire cup, without wire cotton, without wire with cotton, without wire cup, without wire b, with cotton, with cup, with b, with 100, cotton cup, cotton b, cotton 100, cotton cup b 100, with cotton b, with cotton 100, with cotton cup b 100, cup 100, cup cup b 100, b cup b 100]
From here it’s possible to further manipulate the weighting function we introduced. For example words that follow signal words get less of a weight penalty, while the words with higher positional indexes receive a greater penalty. For subsequent numeric grams, we may consider increasing the weight penalty.
Intermediate Results
By adding the contextual tokenization we were able to further reduce the decrease in precision from 7% to less than 3%. As you may have noticed, we have yet to talk about pruning. With the massive increase in the number of N-Grams to our model, we simultaneously increased the noise. It turns out we almost completely solved this problem, simply by using a simple pruning, based on the combined weighted counts, which is also very efficient in terms of computation. You could, for example, filter out all grams with a combined weighted count of less than 0.8. By adding the pruning we were able to further reduce the decrease in precision to less than 0.2%.
We also have yet to touch the Perplexity metric. Quite a lot of people are convinced that a lower perplexity will lead to better language models — the notion of “better” as measured by perplexity is itself suspect due to the questionable nature of perplexity as a metric in general. It’s important, however, to note that improvements in perplexity don’t always mean improvements in the upstream task, especially when considering small improvements. Big improvements in perplexity, however, should be taken seriously (as a rule of thumb, for language modeling, consider “small” as < 5 and “big” as > 10 points). Our pruned weighted contextual N-Gram model outperformed the standard interpolated Kneser-Ney 3-gram model by 37 points.
Training and Model building
Like many of our other approaches or attempts, this one just seemed way too simple to actually work. This simplicity makes it all the more desirable, not to mention the orders of magnitude better than anything else we could find when it comes to efficiency.
Our largest corpus currently is a German one, comprising over 43-million unique product entries, which contain about 0.5 Billion tokens. After our tokenization, ngram generation, weighted counting and pruning we ended up with 32-million unique grams with assigned probabilities which we store in the model. The whole process takes just a little under 9 minutes using a single-threaded standard Macbook pro, 2,3 GHz 8-Core Intel Core i9, without further optimizations. This means that we are able to add new elements to our corpus, add or edit conceptual tokens and/or change the weighting scheme, and work with an updated model in less than 10 minutes.
Retrieval
Building the LM-Model is just one part of the equation. Efficiently serving the model at scale is just as crucial. Since each of our currently 700-million unique search queries needs to be regularly piped through the LMs, the retrieval performance and efficiency are crucial for our business too. Due to very fast build times of the model we decided to index the LM for fast retrieval in a succinct, immutable data-structure using minimal perfect hashing for storing all the grams and their corresponding probabilities. Perfect hash is a hash which guarantees no collisions. Without collisions it’s possible to store only values (count frequencies) and not the original n-grams. Also we can use a nonlinear quantization to pack the probabilities into some lower bit representation. This does not affect the final metrics but greatly reduces memory usage.
The indexation takes around 2 minutes with the model using just a little bit more than 500mb in memory. There is still significant potential to further reduce memory footprint. For now though, we are more than happy with the memory consumption and are not looking to go the route of premature optimization.
In terms of retrieval times the Minimal Perfect Hash data structure which offers O(1) is just incredible. Even though we need several queries against the data structure to value a given phrase we can serve over 20.000 concurrent queries single-threaded on a single standard Macbook pro 2,3 GHz 8-Core Intel Core i9.
Results
All models including the 3-gram Kneser-Ney model are trained on the same corpus, a sample of our german corpus containing 50-million words for comparison. We tried BERT with the provided pretrained models but the quality was not comparable at all. Therefore we trained it from scratch in order to get a fair comparison.
Model
Accuracy
PPL
Trained On
Memory Usage
Training Time
95% / req time
Efficiency
Kneser-Ney-3-Gram
62.3%
163.0
CPU
385 mb
7 min
0.34 ms
47-Watt
Transformer
75.8%
110.5
CPU
3.7 gb
172 min
4.87 ms
3.6-kWatt
pruned weighted contextual 3-Gram Kneser-Ney
91.2%
125.7
CPU
498 mb
9 min
0.0023 ms
60-Watt
+20%
-12%
-87%
-95%
-99%
-98%
In summary we are very pleased with the results and achieved all our goals. We dramatically increased the computational efficiency whilst still not losing much in terms of quality metrics and maintaining maximum compatibility with our current tech stack.
What’s next…?
First of all we are working on documenting and open-sourcing our pruned weighted contextual N-Gram model together with some freely available corpus under our searchHub github account.
For now our proposed LM lacks one important aspect compared to current state of the art models in terms of the vocabulary mismatch problem – word semantics. While most neural models are able to capture some sort of semantics our model is not directly able to expose this type of inference in order to, for example, also properly weight synonymous tokens/terms. We are still in the process of sketching potential solutions to close this gap whilst maintaining our superior computational efficiency.
How to approach search problems with Querqy and searchHub
Limits of rule based query optimization
Some time ago, I wrote how searchHub boosts onsite search query parsing with Querqy. Now, with this blog post I want to go into much more detail by introducing new problems and how to address them. To this end, I will also consider the different rewriters that come with Querqy. However, I won’t cover details already well described in the Querqy documentation. Additionally, I will illustrate where our product searchHub fits into the picture and which tools are most suited for problem solving.
First: Understanding Term-Matching
In a nutshell the big challenge with site search, or the area of Information Retrieval more generally, is mapping user input to existing data.
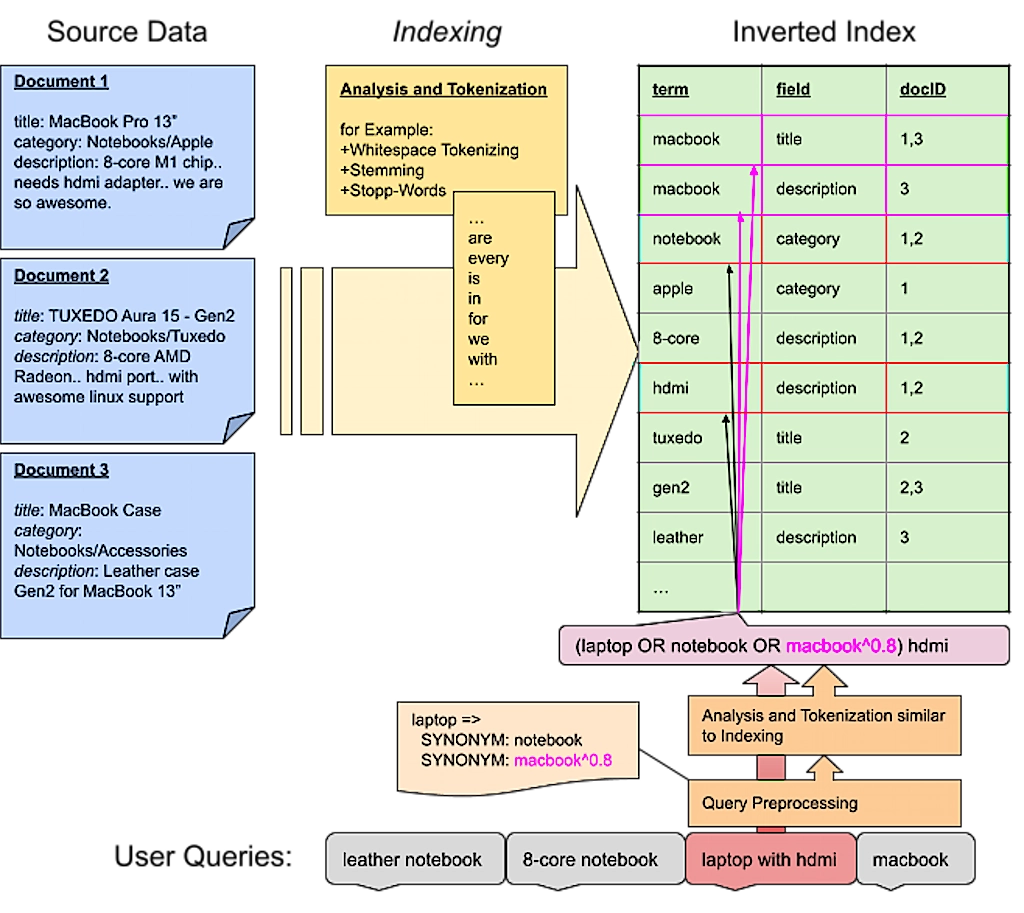
The most common approach is term matching. The basic idea is to split text into small, easy-to-manage pieces or “terms”. This process is called “tokenization”. Eventually these terms are transformed using “analyzers” and “filters”, in a process known as “analyzing”. Finally, this process is applied to the source data during “indexing” and the results are stored in an “inverted index”. This index stores the relationship of the newly produced terms to the fields and the documents they appear in.
This same processing is done for every incoming user query. Newly produced terms are looked up in an inverted index and the corresponding document ids become the queries’ result set. Of course this is a simplified picture, but it helps to understand the basic idea. Under the hood, considerably more effort is necessary in order to support partial matches, get proper relevance calculation etc.
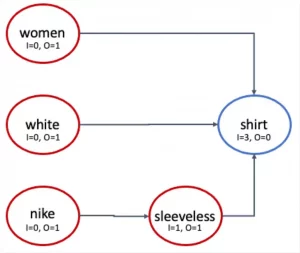
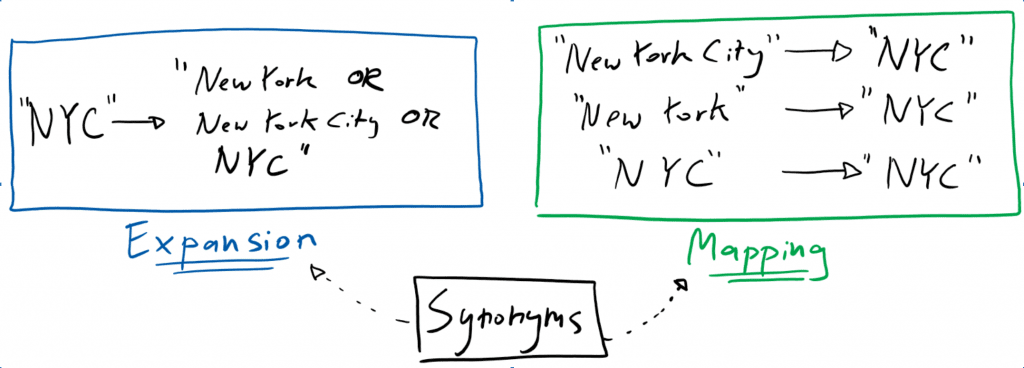
Be aware that, in addition to everything described above, rules too must be applied during query preprocessing. The following visualization illustrates the relationship and impact of synonyms on query matching.
Term matching is also the approach of Lucene – the core used inside Elasticsearch and Solr. On that note: most search-engines work this way, though many new approaches are gaining acceptance across the market.
A Rough Outline of Site Search Problems
Term matching seems rather trivial if the terms match exactly: The user searches for “notebook” and gets all products that contain the term “notebook”. If you’re lucky, all these products are relevant for the user.
However, in most cases, the user – or rather we, as the ones who built search and are interested in providing excellent user experiences – is not so lucky. Let’s classify some problems that arise with that approach and how to fix them.
Unmitigated order turns to chaos
What is Term Mismatch?
In my opinion, this is the most common problem: One or more terms the user entered aren’t used in the data. For example the user searches for “laptop” but the relevant products within the data are titled “notebook”.
This is solved easily by creating a “synonym” rewrite rule. This is how that rule looks in Querqy:
laptop =>
SYNONYM: notebook
With that rule in place, each search for “laptop” will also search for “notebook”. Additionally, a search for “laptop case” is handled accordingly so the search will also find “notebook case”. You can also apply a weight to your synonym. This is useful when other terms are also found and you want to rank them lower:
laptop =>
SYNONYM: notebook
SYNONYM: macbook^0.8
Another special case of term mismatching are numeric attributes: users search for ‘13 inch notebook’ but some of the relevant products, for example, might have the attribute set to a value of ‘13.5’. Querqy helps with rules that make it easy to apply filter ranges and even normalize numeric attributes. For example, by recalculating inches into centimeters, in case there are product attributes that are searched in both units. Check out the documentation of the “Number Unit Rewriter” for detailed and good examples.
However there are several cases where such rules won’t fix the problem:
In the event the user makes a typo: the rule no longer matches.
In the event the user searches for the plural spelling “notebooks”: the rule no longer applies, unless an additional stemming filter is used prior to matching.
The terms might match irrelevant products, like accessories or even other products using those same terms (e.g. the “paper notebook” or “macbook case”)
With searchHub preprocessing, we ensure user input is corrected before applying Querqy matching rules. At least this way the first two problems are mitigated.
How to Deal with Non-Specific Product Data?
The “term mismatch problem” is worse, if the products have no explicit name. Assume all notebooks are classified only by their brand and model names. For example: “Surface Go 12”, and put together with accessories and other product-types into a “computers & notebooks” category.
First of all some analysis needs to stem the plural term “notebooks” to “notebook” in the data and also in potential queries. This is something your search engine has to support. An alternative approach is to just search fuzzily through all the data, making it easier to match such minor differences. However, this may lead to other problems, for example not all stems have a low edit distance (e.g. cacti/cactus). Or yet another issue: other similar but unrelated words might match (shirts/shorts). More about that below, when I talk about typos.
Nevertheless, a considerable amount of irrelevant products will still match. Even ranking can’t help you here. You see, with ranking you’re not just concerned with relevance, but mostly looking for the greatest possible impact of your business rules. The only solution within Querqy is to add granular filters for that specific query:
First of all this “rule set” only applies to the exact query “notebook”. That’s what the quotes signify.
The synonym rules also include matches for “macbook” and “surface” in descending order.
Then we use filters to ensure only mid to high price products are shown excluding those with “pc” in the title field.
Noticeably, such rules get really complicated. Oftentimes there are products that can’t be matched at all. And what’s more: rules only fix the search for a specific query. Even if searchHub could handle all the typos etc. a shop with such bad data quality will never escape manual rule hell.
This makes the solution obvious: fix your data quality! Categories and product names are the most important data for term-matching search:
Categories should not contain combinations of words. Or if they do, don’t use such categories for searching. Also at least the final category level should name the “things” it contains (use “Microsoft Notebooks” instead of a category hierarchy “Notebook” > “Microsoft”) Also be as specific as possible (use “computer accessories” instead of “accessories”, or even “mice” and “keyboards”).
Similar for product names: they should contain the most specific product type possible and attributes that only matter for that product.
searchHub’s analysis tool “SearchInsights” helps by analyzing which terms are searched most often and which attributes are relevant for associated product types.
How to Deal with Typos
The problem is obvious: User queries with typos need a more tenable solution. Correcting them all with rules would actually be insane. However, handling prominent typos or “alternative spellings” using Querqy’s “Replace Rewriter” still might make sense. Querqy has a minimalistic syntax easily allowing the configuration of lots of rules. It also allows substring correction using a simple wildcard syntax.
Example rule file:
leggins; legins; legings => leggings
tshirt; t shirt => t-shirt
Luckily, all search engines support some sort of fuzzy matching as well. Most of them use a variation of the “Edit Distance” algorithm that accepts a match of another term if only one or two characters differ. Nevertheless fuzzy matching is also mismatch prone. Even more so if used for every incoming term. For example, depending on the algorithm used, “shirts” and “shorts” have a low edit distance to each other but mean different things.
For this reason Elasticsearch offers the option to limit the maximum edit distance based on query length. This means, no fuzzy search will be initiated for short terms due to their propensity for fuzzy mismatches. Our project OCSS (Open Commerce Search Stack) moves fuzzy search to a later stage during query relaxation. This means we first try exact and stemmed terms, and only if there are no matches do we use fuzzy search. Also running spell-correction in parallel fixes typos in single words of a multi-term query. (some details are described in this post)
With searchHub we use extensive algorithms to achieve greater precision for potential misspellings. We calculate them once, then store the results for significantly faster real-time correction.
Unfortunately, if there are typos in the product data the problem gets awkward. In these cases, the correctly spelled queries won’t find potentially relevant products. Even if such typos can consistently be fixed, the hardest part is detecting which products weren’t found. Feel free to contact us if you need help with this!
Cross-field Matches
Best case scenario: users search for “things”. These are terms that name the searched items, for example “backpack” instead of “outdoor supplies”. Such specific terms are mostly found in the product title. If the data is formatted well, most queries can be matched to the product’s titles. But if the user searches more generic terms or adds more context to the query, things might get difficult.
Normally, a search index is set up to search in all available data fields, e.g. titles, categories, attributes and even long descriptions – which often have quite noisy data. Of course matches in those fields must be scored differently, nevertheless it happens that terms do get matched in the descriptions of irrelevant products. For example, the term “dress” can be part of many description texts for accessory products, that describe how good they might be combined with your next “dress”.
With Querqy you can set up rules for single terms and restrict them to a certain data field. That way you can avoid such matches:
Example rule file:
dress =>
FILTER: * title:dress
But you should also be careful with such rules, since they would also match for multi-term queries like “shoes for my dress”. Here query understanding is key to mapping queries to the proper data terms. More about this below under “Terms in Context”.
Structures require supreme organization
Decomposition
This problem arises mostly for several European languages, like Dutch, Swedish, Norwegian, German etc. where words can be combined for new, mostly more specific words. For example the German word “federkernmatratze” (box spring mattress) is a composite of the words “feder” (spring), “kern” (core/inner) and “matratze” (mattress).
First problem with compound words: There are no specific rules about how words can be combined and what that means for semantics, only that the last word in a series determines the “subject” classification. Is a compound word made of many words, then each word in the series needs to be placed before the “subject” which always has to appear at the end.
The following German example makes this clear: “rinderschnitzel” is a “schnitzel” made of beef (Rinder=Beef – meaning that it’s a beef schnitzel) but a “putenschnitzel” is a schnitzel made of turkey (puten=turkeys). Here the semantics come from the implicit context. And you can even say “rinderputenschnitzel” meaning a turkey schnitzel with beef. But you wouldn’t say “putenrinderschnitzel” because the partial compound word “putenrinder” would mean “beef of a turkey” – no one says that. 🙂
By the way, that concept or even some of those words have swapped over into English. For example: “kindergarden” or “basketball”, however in German, for many generic compound words, it’s possible to also use the words separately: “Damenkleid” (women’s dress) can also be named “Kleid für Damen” (dress for women).
The impending problem with these types of words is bidirectional though: these cases exist both inside the data, and come from users searching for them. Let’s distinguish between the two cases:
The Problem When Users Enter Compound Words
The problem occurs when the user searches for the compound word but the relevant products contain the single words. In English that doesn’t make sense (e.g. no product title would have “basket-ball” written separately. In German however the query “damenschuhe” (women’s shoes) must also match “schuhe” (“shoes”) in the category “damen” (“women”) or “schuhe für damen” (shoes for women).
Querqy’s “Word Break Rewriter” is good for such cases. It uses your indexed data as a dictionary to split up compound words. You can even control it by defining a specific data field as a dictionary. This can either be a field with known precise and good data or a field that you artificially fill with proper data.
In the slightly different case where the user searches for the decompounded version (“comfort mattress”) and the data contains the compound word (“comfortmattress”) Querqy helps with the “Shingle Rewriter”. It simply takes adjacent words and combines the terms. These are called “shingles”. It’s then possible to match them optionally in the data as well. A query could look like this:
If decompounding with tools like Wordbreak fails, you’re left with only one option: rewrite such queries. For this use case Querqy’s “Replace Rewriter” was developed. However, because searchHub picks the spelling with the better KPIs: like queries with low exitRates or high clickRates, we solve such problems automatically.
Dealing with Compound Words within the Data
Assume “basketball” is the term of the indexed products. Now if a user searches for “ball” he would most likely see the basketball inside the result as well. In this case the decomposition has to take place during indexing in order to have the term “ball” indexed for all the basketball products. This is where neither Querqy nor searchHub can help you (yet). Instead you have to use a decompounder during indexing and make sure to index all decompounded terms with those documents as well.
In both cases however, typos and partial singular/plural words might lead to undesirable results. This is handled automatically with searchHub’s query analysis.
How to Handle Significant Semantic Terms
Terms like “cheap”, “small”, and “bright” most likely won’t match any useful product related terms inside the data. Of course they also have different meanings depending on their context. A “small notebook” means a display size of 10 to 13 inches, while a small shirt means size S.
With Querqy you can specify rules that apply filters depending on the context of such semantic terms.
small notebook =>
FILTER: * screen_size:[10 TO 14]
small shirt =>
FILTER: * size:S
But as you might guess, such rules easily become unmanageable due to thousands of edge cases. As a result, you’ll most likely only run these kinds of rules for your top queries.
Solutions like Semknox try to solve this problem by using a highly complex ontology that understands query context and builds such filters or sortings automatically based on attributes that are indexed within your data.
With searchHub we recommend redirecting users to curated search result pages, where you filter on the relevant facets and even change the sorting. For example: order by price if someone searches for “cheap notebook”.
Terms in Context
A lot of terms have different meanings depending on their context. Like a notebook could be an electronic device or a paper device to take notes. A similar case for the word “mobile”: on its own the user is most likely searching for a smartphone. But in the context of the words “disk”, “notebook” or “home” , completely different things are meant.
Also brands tend to use common words for special products, like the label “orange” from “Hugo Boss”. In a fashion store this might become problematic if someone actually searches for the color “orange” in combination with other terms.
Next, broad queries like “dress” need more context to get more fitting results. For example a search for “standard women’s dresses” should not deliver the same types of results as a search for “dress suit”.
There is no specific problem about it and thus also no specific way to solve it. Just keep it in mind when writing rules. With Querqy you can use quotes on the input query to restrict it to be only for term beginnings, endings or full query matches.
With quotes around the input, the rule only matches the exact query ‘dress’:
"dress" =>
FILTER: * title:dress
With a quote at the beginning of the input, the rule only matches queries starting with ‘dress’:
"dress =>
FILTER: * title:dress
With a quote at the end of the input, the rule only matches queries ending with ‘dress’:
dress" =>
FILTER: * title:dress
Of course this may lead to even more rules, as you strive for more precision to ensure you’re not muddying or restricting your result set. But there’s really no way to prevent it, we’ve seen it in almost every project we’ve been involved: sooner or later the rules get out of control. At some point, there are so many queries with bad results that it makes more sense to delete rules rather than add new ones. The best option is to start fixing the underlying data to avoid “workaround rules” as much as possible.
Gears improperly placed limit motion.
Conclusion
At first glance, term matching is easy. But language is difficult. And this post merely scratches the surface of it. Querqy, with all the different rule possibilities, helps you handle special cases. searchHub locates the most important issues with “SearchInsights”. It also helps reduce the amount of rules and increase the impact of the few rules you do build.
Why Getting Your Query Preprocessing Technique Right makes Onsite Search better?
Query preprocessing
In this post, I present how query preprocessing can make your on-site search better in multiple ways and why this process should be a separate step in your search optimization. Below I will present the following points:
What is query preprocessing and why should you use it?
What is the problem with common structures?
What are the benefits of externalizing the query preprocessing step from your search engine?
What is Query Preprocessing and Why You Should Use It
Your onsite search is basically an Information Retrieval (IR) System. Its goal is to ensure your customer (the user) is able to get the relevant information from it. In the case of an ecommerce shop this is typically products he searched for or wants to buy. Of course, there are many goals for your website, like using marketing campaigns to increase revenue and so on. However, the main goal is to show your customers the products and information they searched for. The problem is that the user approaches a search in your shop in his or her own personal way. Each customer speaks his or her own vernacular if you will. Therefore, it simply isn’t feasible to force customers to, or imply they should speak the language of your particular onsite-search. Especially, considering the overwhelming likelihood that your search engine will require some kind of technical speak to reach peak performance.
In my experience, there are two extreme examples of why queries do not return the desired search results aside from the shop not stocking the right product or missing information the customer is looking for.
Not enough information in the query -> short queries like “computer”
Too much noise in the query -> queries like “mobile computer I can take with me”
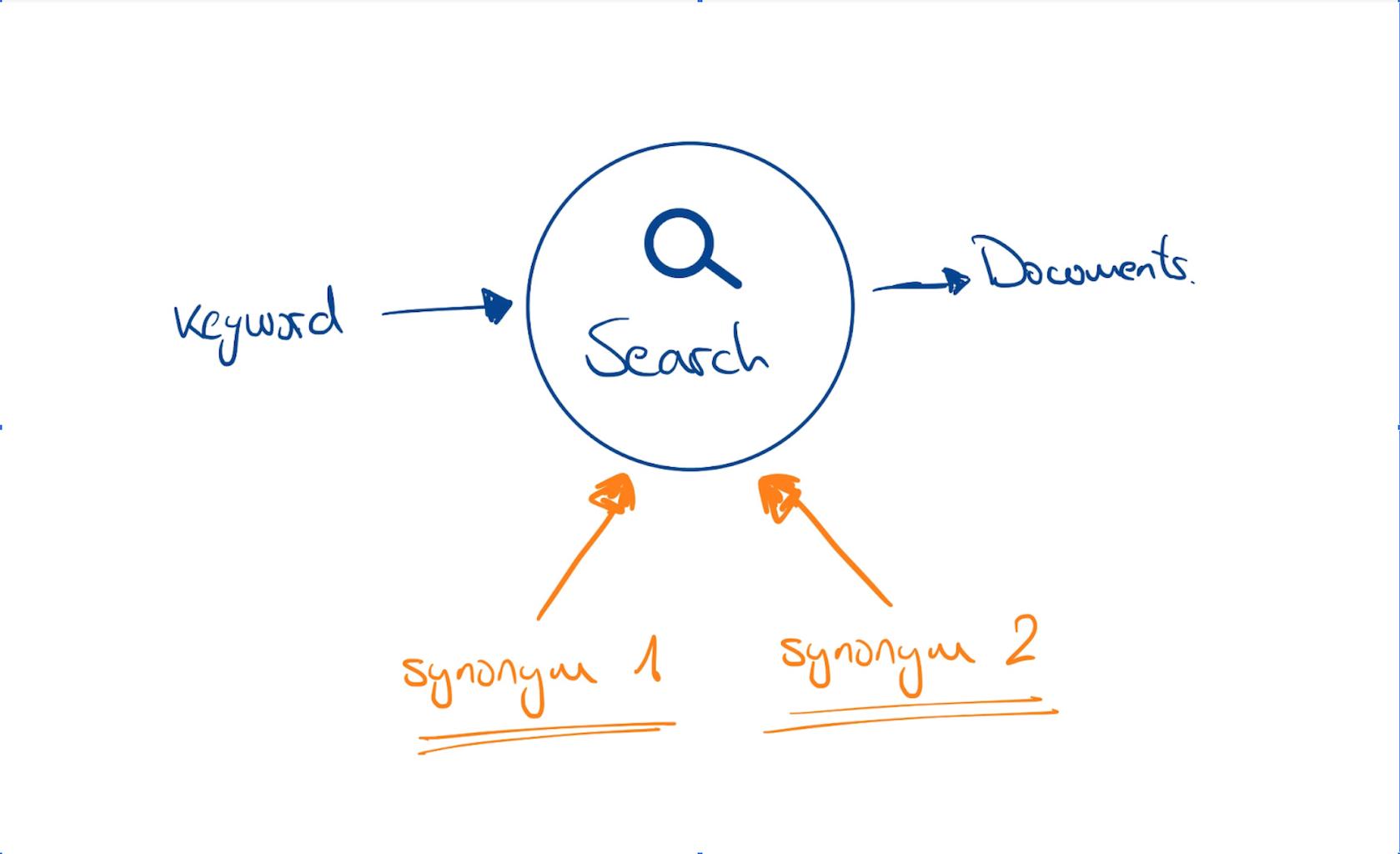
In the first case, we expand the query from “computer” to something like: “computer OR PC OR laptop OR notebook OR mobile computer”, to get the best results for our users.
In the second case, we first have to shrink the query by removing the noise from “mobile computer I can take with me” to “mobile computer”, before expanding to something like: “laptop OR notebook OR mobile computer” to get the best results for our users.
Of course, these aren’t the only query preprocessing tasks. The following is an overview of typical tasks performed to close the gap between the user’s language and the search engine to return better results:
Thesaurus and Synonyms entries
Stemming – reducing words to their root parts
Lower Casing
Asciifying
Decomposition
Stop-Words handling – eliminating non-essential words like (the, it, and, a, etc.)
Localization
etc.
The Problem with Common Information Retrieval Structures
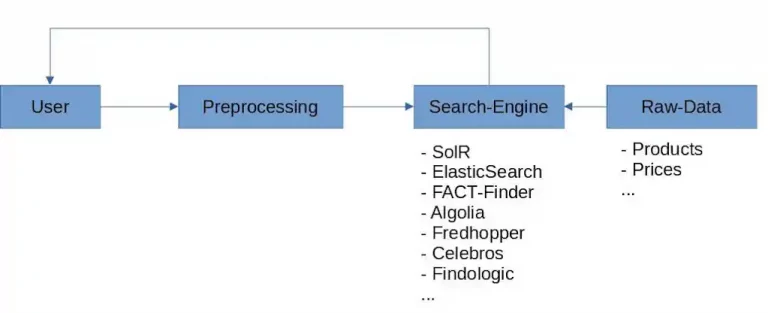
The preprocessing described above is normally carried out and configured within your search engine. The following graphic shows an overly simplified common onsite search structure:
Users search using their own language and context regarding your products. This means that they will not intuitively understand the language most preferable to your Information Retrieval (IR) System.
In a nutshell your onsite search is a highly configurable IR which currently performs all preprocessing.
The raw data used by your IR for searching.
In addition to optimizations like correctly configuring fields and their meanings, or running high-return marketing campaigns, most optimizations to your onsite search are done by query preprocessing.
So here’s my question: does it really make sense to do all this pre-processing within a search engine?
Have a look at this overview of potential obstacles when pre-processing is handled within the search engine:
A deep knowledge of your search engine and its configuration is necessary.
Changing to a new onsite search technology means losing or having to migrate all previous knowledge.
Onsite search is not inherently able to handle all your pre-processing needs.
Debugging errors within a search result is unwieldy, then it’s necessary to audit both pre-processors as well as related parts of the onsite search configuration.
The Benefits of Extracting the Query Preprocessing Step from Your Onsite Search Engine
Having illustrated what query preprocessing is, and which potential problems you could face when running this step inside your search engine, I want now to make a case for the benefits of externalizing this step in the optimization process. Have a look at the graphic below for a high-level illustration of the concept when preprocessing is done outside your search engine.
The effort it takes to configure your onsite search engine when migrating from one search vendor to another, can be dramatically decreased as a result of having externalized the query preprocessing. This also has the following benefits:
less time spent trying to understand complex search engine configurations.
Lower total cost of onsite search ownership
Your query preprocessing gains independence from your search engine’s main features.
Externalizing means you can cache the query preprocessing independently of your search engine which has a positive impact on related areas like total cost of ownership, the environment, and so on. Take a look at this article for more information.
Debugging search results is easier. The exact query string, used by the search engine, is always transparently visible.
Now you know the benefits of query preprocessing and why it could make sense to externalize this step in your data pipeline optimizations.
Wer nicht direkt die komplette Suche in seinem Shop austauschen möchte (meist ein größeres Projekt das Wochen bis Monate dauert), kommt um intelligente Erweiterungen nicht herum. Deshalb geht searchhub – unser junges KI Startup aus Pforzheim – genau diesen Weg. Umso mehr freuen wir uns über den tollen Beitrag des Internetworld Business zum Thema “Suche” in dem wir auch prominent erscheinen.
“Im Bereich Shopsuche setze man auf neue Produkte wie Searchhub oder die Headless-Lösung von Makaira” Anatolij von Kosmonaut.
Als headless KI Erweiterung für alle Suchlösungen hilft Searchhub durch intelligente Clusterung von Suchbegriffen die Ergebnisqualität durchgängig zu erhöhen und gleichzeitig den manuellen Pflegeaufwand (Synonyme, Vertipper, etc) deutlich zu reduzieren.
Vielen Dank Matthias Hell für die Erwähnung in deinem IWB Artikel in dem du dich mit Anatolij & Christian zu Suchen ausgetauscht hast.
Und wer mehr wissen möchte >>> Mathias & Markus stehen gerne für einen unverbindlichen Blick hinter die Kulissen zur Verfügung.
Query Understanding: How to really understand what customers want – Part 1
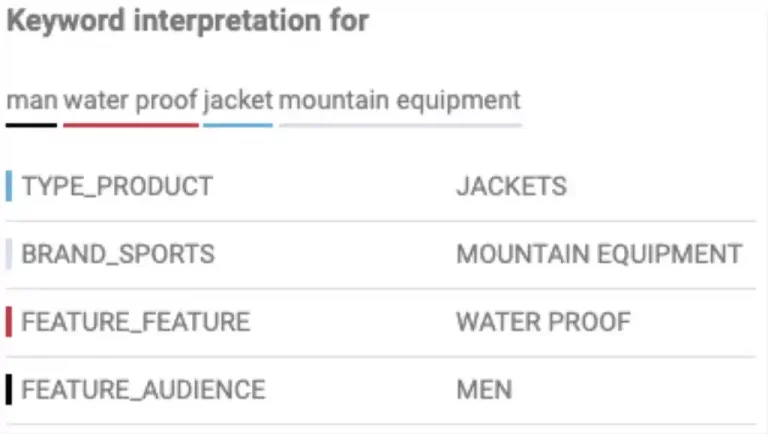
When users search for things like “men’s waterproof jacket mountain equipment” they’re seeking help. What they expect is for the search engine to understand their intent, interpret it and return products, content or both that match. It’s essential for the search engine to differentiate types of products or content they are looking for. In this case, the customer is likely shopping for a jacket. Equipped with this domain-specific knowledge, we can tailor the search results page by displaying jacket-specific filters, banners and refine the search results by prioritizing or only showing jackets. This process is often called query-understanding. Many companies both site search vendors as well as retailers have tried developing, building and improving these systems but only few have made it work properly at large scale with manageable effort.
Query Interpretation the backstory
At the time of this post, all our customers combined sell
more than 47 million different products
in over 13 different languages
across about 5.3 million unique search intent clusters.
These clusters represent approximately 240 million unique search queries that cover
a couple billion searches.
All our customers use some kind of taxonomy to categorize their products into thousands of “product classes”. Then they append attributes mainly for navigational purposes.
Examples of product classes include
jackets
waterproof jackets
winter jackets
Query Classifier
The Query Classifier predicts product classes and attributes that customers are most likely to engage with, based on their search queries. Once a query classifier accurately predicts classes and attributes, we can enrich the search-system with structured domain knowledge. This transforms the search problem from purely searching for strings to searching for things. The result is not only a dramatic shift in how product filters are displayed relative to their product classes, but also how these filters can be leveraged to boost search results using those same classes.
The Challenge
Deciphering, however, which types of products, content or attributes are relevant to a search query is a difficult task. Some considerations:
Challenge
Context
SCALE
Every day, we help our customers optimize millions of unique search queries to search within millions of products. Both dimensions, the query-dimension and the product-dimension change daily. This makes scale a challenge already.
LANGUAGE GAP
Unfortunately, most of our customers are not focused on creating attributes and categories as a main optimization goal for their search & discovery systems. This leads to huge gaps when comparing the product catalog to the user query language. Additionally, every customer uses individual taxonomies making it hard to align different classes across all customers.
SPARSITY
A small percentage of queries explicitly mention product type making them easy to classify. Most queries do not. This forces us to take cues from users’ activities to help identify the intended product class.
AMBIGUITY
Some queries are ambiguous. For example, the query “desk bed” could refer to bunk beds with a desk underneath, or it could mean tray desks used in bed.
While there isn’t much we can do about the first challenge, the good news is we already cluster search queries by intent. Knowing customer intent means searchhub can leverage all the information contained in these clusters to address challenges 3 and 4. Sparsity for example, is greatly reduced because we aggregate all query variants into clusters and use the outcome to detect different entities or types. Also the ambiguity challenge is greatly reduced as query clusters do not contain ambiguous variants. The clusters themselves, on the other hand, give us enough information to disambiguate.
Having solved problems 3, and 4, we are able to focus on addressing the Language gap problem and building a large scale, cost efficient Search Interpretation Service.
Our Approach
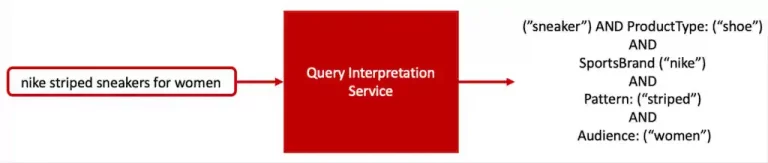
To tackle the query understanding challenge searchhub developed our so-called Search Interpretation Service to perform live search query understanding tasks. The main task of the Interpretation service is to predict the query’s relevant classes (attributes) for a given query in real-time. The output can then be consumed by several downstream Search applications. The Query Classifier model (NER-Service) powers one of these Interpretation microservices.
Once a query is submitted to the search interpretation service we start our NER-Service (named entity recognition and classification). This service identifies entities in user queries like brands, colors, product category, product type and product type specific attributes. All matched entities in the query are annotated with predefined tags. These tags & entities are based on our unified ontology which we’ll cover in a bit.
For the actual query annotation, we use an in-house Trie-based solution comparable to the common FST based SolrTextTagger, only an order of magnitude faster. Additionally, we can easily add and remove entities on the fly without re-indexation. Our solution extracts all possible entities from the query, disambiguates them and annotates them with the predefined tags.
Results
Challenge
Precision
Recall
F1
Baseline (productType)
0.97
0.69
0.81
Since the detected entities in our case are applied to complete intent-clusters (representing sometimes thousands of search queries) rather than a single query, precision is of highest priority. We tried different approaches for this task but none of them gave us a precision close to what you see in the above table. Nevertheless, a quick glance and you’ll easily spot that “Recall” is the weakest part. The system is simply not equipped with enough relevant entities and corresponding tags. To learn these efficiently, the logical next step was to build a system able to automatically extract entities and tags based on available data sources. We decided to build a unified ontology and an underlying system that learns to grow this ontology on its own.
searchhub’s unified Ontology
Since taxonomies differ greatly across our customer base we needed an automated way to unify them, that would allow us to generate predictions across customers and languages. It’s essential we are able to use this ontology to firstly classify SKUs and secondly, use the classes (and subclasses) as named entities for our NER-service.
Since all existing ontologies we found tend to focus more on relationships between manufacturers and sellers, we needed to design our taxonomy according to a fundamentally different approach.
Our ontology requires all classes (and subclasses) to be as atomic as possible to improve recall.
“An atomic entity is an irreducible unit that describes a concept.” – Andreas Wagner
It also appends an “is-a” requirement on all subclasses for a given class. Additionally, we try to avoid combo classes unless they are sold as a set (dining sets that must contain both table and chairs). This requirement keeps the ontology simple and flexible.
What was our process for arriving at this type of ontological structure? We began by defining Product Types. From there we built the hierarchical taxonomy in a way that maximizes the query category affinity. In essence we try to minimize the entropy of the distribution of a search result set across its categories for our top-k most important queries.
Product Types
A Product Type is defined as the atomic phrase that describes what the customer is looking for.
Consider an example, “men’s waterproof jacket mountain equipment”.
Here, the customer is looking for a jacket.
It is preferable if the jacket is waterproof
designed for men
by the Brand Mountain Equipment
but these requirements are secondary to the primary requirement of it being a jacket. This means that any specialized product type must be stripped down to its most basic form jacket.
Attributes
An Attribute is defined as an atomic phrase that provides more information about a product type.
Consider an example “bridgedale men’s merino hiker sock”.
Here, we classify the term sock as a Product type
and we can classify the remaining terms (bridgedale, men’s, merino and hiker) as Attributes and/or Features.
This gives us a lot of flexibility during recall. Attributes can be subclassed in Color, Material, Size, etc. depending on the category. But since our aim is to create a simplified ontology for search, we restrict attribute subclasses to what is actually important for search. This makes the system more maintainable.
Learning to grow ONTOLOGIES
Data Collection
It should be obvious that building and growing this type of ontology needs some sort of automation, otherwise our business couldn’t justify maintaining it. Our biggest information source is anonymous customer behavior data. So, after some data-analyses we were able to prove that customers generally add relevant products to their shopping cart during search. This allowed us to use historical user queries and the classes of the related products added-to-cart, within a search session, as the model development dataset. For this dataset we defined a search experience as the sequence of customer activities after submitting a search query and before moving on to a different activity. For each search experience, we collected the search query and the classes of the added-to-cart-products. Each data point in our dataset corresponds to one unique search experience from one unique customer.
Connecting Queries and Signals
From here we build a bipartite graph that maps a customer’s search query to a set of added-to-cart-products – SKUs. This graph can be further augmented by all sorts of different interactions with products (Views, Clicks, Buys). We represent search queries and SKUs by nodes on the graph. An edge between a query and a SKU indicates that a customer searched for the query and interacted with the corresponding SKUs. The weight of the edge indicates the strength of the relationship between the query and the SKU. For the first model we simply modeled this strength by aggregating the number of interactions between the query and the SKU over a certain period of time. There are no edges between queries or between SKUs.
As broad queries like “cheap” or “clothing” might add a lot of noise to the data we use the entropy of a query across different categories to determine if it is broad and remove it from the graph. We use several heuristics to further augment and prune the graph. For example, we remove query-SKU pairs that have edge weights less than some predefined threshold. From here we have simply to find a way to compute a sorted list of Product sub-classes that are atomic and relevant for that category.
Extracting Product Entities
To our knowledge there exist several methods to automatically extract atomic Product entities from search queries and interaction data, but only one of them offered us what we needed. We required the method to be fully unsupervised, cost efficient and fast to update.
The Token Graph Method
This method is a simple unsupervised method for extracting relevant product metadata objects from a customer’s search query, and can be applied to any category without any previous data.
The fundamental principle behind it is as follows: If a query or a set of queries share the same interactions we can assume that all of them are related to each other, because they share some of the same clicked SKUs. In other words, they share the same intent. This principle is also known as universal-similarity and its fundamental idea is used in almost any modern ML-application.
Now that we have a set of different queries that are related to each other we apply a trick. Let us assume that we can detect common tokens (a token might be a single or multi-word-token) between the queries. We can now create a new graph where each token is a node and there are edges between adjacent tokens. The above figure shows the token graph for the query set {women shirt, white shirt, nike sleeveless white shirt}.
It is quite safe to say that in most cases, the product token is the last term in a query (searchub is almost able to guarantee this since we use aliases that represent our clusters that are created by our own language models). With this assumption the product token should be the node that maximizes the ratio (I /(O+I)) , where O = is the number of outgoing edges and I is the number of incoming edges for the node corresponding to the token. If the search query contains just a single token, we set I = O = 1.
We can further improve precision by requiring that I ≥ T , where T is some heuristic threshold. From here we can generate a potential product from each connected component and, aggregated over all connected components gives us a potential list of products. With this simple model we can not only extract new product types, we can actually leverage it further to learn to categorize these product types. Can you guess how ? 🙂
What’s Next
This approach of using a kind of rule-based-system to extract, and an unsupervised method to learn these rules, seems too simple to produce good enough results, but it does and has one very significant advantage over most other methods. It is completely unsupervised. This allows it to be used without any training data from other categories.
Results
Challenge
Precision
Recall
F1
Baseline (productType)
0.97
0.78
0.86
Additionally, this approach is incremental. This means we remain flexible, able to rollback almost instantly, all or only some newly learned classes in our ontology if something goes wrong. Currently we use this method as the initial step acting as the baseline for more advanced approaches. In the second part we’ll try some more sophisticated ways to further improve recall with limited data.
Almost any person working with search is somehow aware of Synonyms and their importance when optimizing search to improve recall. Therefore, it will be no surprise to say that adding synonyms is one of the most essential methods of introducing domain-specific knowledge into any symbolic-based search engine.
“Synonyms give you the opportunity to tune search results without having to make major changes to your underlying data and help you to close the vocabulary gap between search queries and product data.”
To better underline the use-cases and importance, please consider the following eCommerce examples:
If a customer searches for “laptop,” but the wording you are using in your product data is “notebook,” you need a common synonym, or you won’t make the sale. More precisely, this is a bidirectional synonym-mapping which means that both terms have an equivalent meaning.
If a customer is looking for “accu drill” or “accumulator screwdriver,” you’ll end up setting up several bidirectional synonym-mappings, one for accu = accumulator and another one for drill = screwdriver.
If a customer searches for “trousers,” you might also want to show him “jeans,” “shorts,” and “leggings.” These relationships are particular types of synonyms, so-called Hyponyms. The most intuitive definition I’m aware of for a hyponym is the “directed-typeOf” definition. So every jeans, shorts or leggings is a “typeOf” trouser but not the other way around.
We use synonyms to tell the search system to expand the search space (synonym-expansion). Or in other words, if a search query contains a synonym, we ask the search engine to also search for other synonymous words/phrases in the background.
All of the above cases are very common and sound pretty straightforward. But the internal dependencies on other parts of the search analysis chain and the fundamental context-dependent meaning of words are often hidden away and not evident to the people trying to solve specific problems by introducing or managing synonyms. This often leads to unexpected, sometimes even unwanted, results.
Spaghetti-Synonyms best of
1. Synonyms with dependency on proper spelling and tokenization
For most search engines, the quality of the synonym expansion is highly dependent on the quality of the so-called tokenization. So, for example, if we consider search phrases like “sonylaptopcharger”; “sony laptopcharger”; “sony laptopchager” or “charger for sonylaptop,” a simple synonym-expansion with “notebook” will most likely not work as expected. That’s because the tokenization process is unable to produce a token “laptop” that could be expanded with “notebook.”
Additional logic and manual effort are needed to cover these cases. Unfortunately, that’s usually the point at which users start to flood the synonym files by adding misspellings and decompositions. But this is obviously not a scalable, long-term solution to the problem.
2. Transitive compounding effects of synonyms
Since there might be hundreds or even thousands of synonyms you’d need to cover, you will most probably end up with a long list of synonyms defining some terms and their specified mappings (“expansion candidates”).
Now imagine you have the following two entries:
dress, attire, apparel, skirt, costume
shoes, boots, footgear
Maybe you have added these synonym mappings at different times to improve the recall for a specific query like “dress” or “shoes,” for example. For these queries in isolation, everything seems fine. However, you may have unintentionally opened Pandora’s box from the moment you added the second entry. From now on, it’s likely that searches for “dress shoes” will no longer deliver the expected results. Furthermore, depending on the query parsing used, these results will be inflated by irrelevant matchings of all sorts of dresses and shoes.
Again the most common way to solve this problem is to add manual rules like preprocessors or filters to remove the unwanted matches from the result.
To be clear, taking the semantic context into account is the single greatest challenge for synonyms. Depending on the context, a word can have different meanings in all natural languages. For example, the word “tee” is often used as a synonym for “t-shirt” in the context of fashion, while “tee” has an entirely different meaning in the context of “food.”
“When your customers are formulating a query they take a specific semantic context for granted. The applied synonym expansion needs to capture this context to give the best results.”
Let’s say you work for an electronics shop and came up with the following well-thought-through list of synonyms to increase recall for searches related to the concept of “iphone cases.”
iphone case, iphone backcover, apple backcover, apple smartphone case
You check a couple of queries, and it seems like the job is done. Well, until someone types in the query “ipad apple backcover” and gets flooded by numerous irrelevant iPhone covers. That’s because the synonym expansion does not consider the context around the synonyms.
BTW: do you still remember the example “accu drill” or “accumulator screwdriver” from the beginning? Hopefully, you spotted the point where I might have tricked you. While accu and accumulator are accurate synonyms, drill and screwdriver are context-dependent synonyms.
We have seen these kinds of challenges pop up with every eCommerce retailer. Even the most advanced retailers have struggled with the side-effects of synonyms in combination with (stopwords, acronyms, misspellings, lemmatization, and contextual relationships).
At searchhub, we thrive on making it easier to manage and operate search engines while helping search engines better understand search queries. That’s why we decided to tackle the problem of synonyms as well.
Introducing searchhub concepts
The main idea behind searchhub is to decouple the infinite search-query-space from the relatively small product-catalog-space. As a search user, the number of words, meanings, and ways to formulate the same intent are much much higher than the number of words you have available in your product catalog and, therefore, in your index. This challenge is called the “language gap.”
We meet this query intent challenge head-on by clustering the search-query-space. The main advantage of taking this approach is the sheer volume of information gathered from several, sometimes thousands of queries inside a single cluster, which allows us to add information and context to every query naturally. Not only that, this enriched query context provided us with the necessary foundation to design a unique solution (so-called “concepts”) to solve the challenges of transitive compound synonyms, naturally handling contextual synonyms, and removing dependencies on spelling and tokenization.
Let’s take a very typical example from the electronics world where we would like to encode the contextual semantic relationship between the following terms:
”two door fridge” and “side by side”
This is a pretty challenging relationship because we try to encode “two door” and “side by side” as equivalent expressions but only in the context of the query intent fridge. That’s why the search manager intelligently added the word fridge, as many other products might have two doors and not be side by side.
But maybe the search manager was unaware of the brand called “side by side,” and that next week the shop will also list some fantastic side-by-side freezers which are not precisely fridges 🙂
In searchhub, however, you could easily add such an underlying relationship (we call it concept-definition) by simply defining “two door” = “side by side.” Under the hood, searchhub takes care of morphology, spelling, tokenization, contextual dependencies and only applies the concepts (synonyms) if the query intent is the same.
But not only that. Since every query in our clusters is equipped with performance KPIs, we naturally support performance-dependent weighted synonyms if your search platform supports them.
We tested this solution intensely with some of our beta customers, and the results and feedback have been overwhelming. For example
We reduced the number of synonyms previously managed in the search platform for our customers, on average, by over 65%. At the same time, we increased query synonym expansion coverage by 19% and precision by more than 14%.
This means we found a very scalable, and more importantly fully transparent, way for our customers to manage and optimize their synonyms at scale.
BTW searchhub also learns these kinds of concept-definitions automatically and proactively recommends them so you can concentrate on validation rather than generation.
If you are interested in optimizing your synonym handling, making it more scalable and accurate, let’s talk……..
Under the hood – for our technical audience
Synonyms are pretty easy to add in quite a lot of cases. Unfortunately, only a few people understand the challenges behind correctly supporting synonyms. Proper synonym handling is no easy task, especially for multi-word expressions, which introduce a lot of additional complexity.
We decided to use a staged approach consisting of two stages to tackle this challenge with our concepts method.
Stage 1 – Query Intent Clustering
Before we have a deeper look at the solution, let’s define some general conditions to consider:
By using query-clusters where morphology, spelling, tokenization, and contextual dependencies like (dresses for women, drill without accu, sleeveless dress) are already taken into account, we can finally ignore spelling, tokenization and structural semantics’ dependencies.
We also no longer have to account for language specifics since this is already handled by the query clustering process (for example, a “boot” can mean a shoe or a boat in german, while in English, it can mean shoe or trunk).
Stage 2 – Concepts, a way to encode contextual equivalent meaning of words or phrases
Once a concept is defined, searchub begins with a beautifully simple and efficient concept matching approach.
We scan all clusters and search for those affected by one or more concept definitions. This is a well-known and easy to solve IR problem even at a large scale.
We reduce all concept-definitions for all concept-candidates using so-called concept-tokens (for example <concept-ID>). This is necessary as several transitive concept-definitions may exist for a single concept-object in multiple languages.
Aggregate all reduced candidates, evaluate them based on their semantic context, and treat only the ones as conceptually equivalent, which share the same semantic context. This stage is essential, so it needs the most attention. You don’t want <concept-1>grill and grill<concept-1> to be equivalent even though they contain the same tokens or words.
The last step is to merge all conceptually equivalent candidates/clusters provided they represent the same query intent. This might seem counter-intuitive since we usually think of synonym expansion. Still, to expand the meaning of a query-intent-cluster, we have to add information by merging it into the cluster.
As a search expert, this approach might look way too simple to you, but it has already proved bullet-proof at scale. And since our searchhub platform is designed as a lambda architecture, this is all done asynchronously, not even affecting search query response times.
credit feature image: Diego Garea Rey | www.diegogarea.com
How To DIY Site Search Analytics Using Athena – Part 3
This is the final post in a series of three. If you missed Part 1 and Part 2, please head over and read them first as this post will build on the work from our sample analytics application.
Remember: we are building an Ecommerce Site Search Analytics tool from scratch. The goal is to allow for you to more accurately gather detailed information from your site search tool in order to optimize your business for more online revenue.
So let’s get right to it and discuss how to add the following features to our application:
How-To generate random sample data to easily create queries spanning multiple days.
How-To create Athena queries to fetch the E-Commerce KPIs: CTR and CR.
How-To create an HTML page to visualize the KPIs in a line chart.
1. How-To generate random sample data
So far, our application can process a single CSV file, which it then converts into an Apache Parquet file. This file is then uploaded to AWS S3 under the partition key of the last modification date of that file.
Now, we will create a method to generate random data across multiple days. This enables us to write Athena queries that span a time range. (E.g., get the CTR of the last 7 days.) First, we need to make some necessary changes to the FileController and FileService classes even though this clearly violates the Single-Responsibility-Principle. However, for the purposes of this post, it will serve our needs.
Open up the FileController and add the following method:
@GetMapping("/randomize/{numDays}")
@ResponseBody
public List<URL> randomize(@PathVariable int numDays) {
return fileService.createRandomData(numDays);
}
The endpoint expects a path variable containing the number of days the random data should be created. This variable is subsequently passed to a new method in the FileService which contains the actual logic:
# Create random data for the last seven days
curl -s localhost:8080/csv/randomize/7
# The response returns the S3 URLs for every generated Parquet file
["https://s3.eu-central-1.amazonaws.com/search-insights-demo/dt%3D2021-10-11/analytics.parquet","https://s3.eu-central-1.amazonaws.com/search-insights-demo/dt%3D2021-10-10/analytics.parquet","https://s3.eu-central-1.amazonaws.com/search-insights-demo/dt%3D2021-10-09/analytics.parquet","https://s3.eu-central-1.amazonaws.com/search-insights-demo/dt%3D2021-10-08/analytics.parquet","https://s3.eu-central-1.amazonaws.com/search-insights-demo/dt%3D2021-10-07/analytics.parquet","https://s3.eu-central-1.amazonaws.com/search-insights-demo/dt%3D2021-10-06/analytics.parquet","https://s3.eu-central-1.amazonaws.com/search-insights-demo/dt%3D2021-10-05/analytics.parquet"]
Now that our files are uploaded to S3 let’s check if Athena partitioned the data correctly by executing the count request.
curl -s localhost:8080/insights/count
# The response should look like
Executing query : select count(*) from "ANALYTICS"
Fetched result : +-----+
: |count|
: +-----+
: | 73|
: +-----+
Fetched row(s) : 1
2. How-To create Athena queries to fetch the E-Commerce KPIs: CTR and CR
The Click-Through-Rate (CTR) and Conversion-Rate (CR) are among the most frequently used KPIs when it comes to measuring the performance of an E-Commerce-Search.
Most search vendors claim that their solution boosts your Conversion-Rate by X %
Often the promise is made to increase the CR by upwards of 30%. More than anything, this is clever marketing as the potential increase goes hand in hand with increased sales. However, as highlighted in the blog series by Andreas Wagner it’s necessary to not only rely on these KPIs to optimize search. Nevertheless, they are part of the big picture, so let’s talk about retrieving these KPIs. Technically, if you already have the correct data, the calculation is pretty straightforward.
A Definition of the KPIs CR and CTR:
CR or Conversion Rate: Number of transactions / Number of searches
CTR or Click Through Rate: Number of clicks / Number of searches
Now that we know what these KPIs are and how to calculate them, we need to add the new REST endpoints to the AthenaQueryController
@GetMapping("/ctr")
public ResponseEntity<ChartData> getCTR(@Valid AnalyticsRequest request) {
return ResponseEntity.ok(queryService.getCTR(request));
}
@GetMapping("/cr")
public ResponseEntity<ChartData> getCR(@Valid AnalyticsRequest request) {
return ResponseEntity.ok(queryService.getCR(request));
}
The parameter of both methods has two unique features:
@Valid This annotation is part of the Java Bean Validation specification. It ensures that the fields of the subsequent object (AnalyticsRequest) are validated using their internal annotations. This ensures that inputs made in most cases by a user via a GUI meet specific criteria. In our case, we want the user to enter the period for calculating the CR/CTR, and we want to make sure that the start date is before the end date. We achieve this with another annotation @AssertTrue in the AnalyticsRequest class:
@Data
@AllArgsConstructor
@NoArgsConstructor
public class AnalyticsRequest {
@DateTimeFormat(iso = ISO.DATE)
private LocalDate from;
@DateTimeFormat(iso = ISO.DATE)
private LocalDate to;
@AssertTrue
public boolean isValidDateRange() {
return from != null && to != null && !to.isBefore(from);
}
}
The incoming REST request will automatically be validated for us. Additionally, our service method will only be called if the isValidDateRange method returns true otherwise, a validation error response will be sent to the client. If you followed the second part of this article and tried to add those annotations, you will get an error due to missing required dependencies. So let’s go ahead and add them to the pom.xml
This Spring starter pulls in hibernate-validator, the reference implementation of the validation API. Additionally, jakarta.el, an implementation of the Expression Language specification, which supports variable interpolation as part of the validation API, is also loaded.
AnalyticsRequest is not preceded by any @RequestParam, @RequestBody or @PathVariable annotation. As a result, Spring tries to map each request parameter to a field in the specified DTO – Data Transfer Object. In order for this to work, the parameter and field name must be identical.
In our case, this means the request must look like this: baseUrl/cr?from=yyyy-MM-dd&to=yyyy-MM-dd
That’s it for the controller.
How-To Make The Necessary Changes to the AthenaQueryService
Let’s dig into the details of the changes in the AthenaQueryService using the example of CR
public ChartData getCR(AnalyticsRequest request) {
Field<BigDecimal> crField = saveDiv(sum(ANALYTICS.TRANSACTIONS), sum(ANALYTICS.SEARCHES), new BigDecimal(0));
return getKPI(request, crField);
}
Very straightforward with the help of two auxiliary methods – where the real magic is at. So let’s examine those auxiliary methods in more detail now.
Here we use several functions of the JOOQ DSL to protect ourselves from division errors. The most infamous, known by every developer, is division by 0. You see, in practice, there is hardly a webshop that tracks all data correctly. As a result, these protective mechanisms are of utmost importance for volatile data such as E-Commerce search tracking.
coalesce: returns the first value of the list that is non-null.
nullif: returns null if both expressions are equal otherwise, it returns the first expression.
The second helper method getKPI creates the actual Athena query and extracts it. This allows the query to be reused when calculating the CTR, thanks to JOOQ and its Field abstraction.
The JOOQ DSL should be very easy to read for anyone who understands SQL syntax. First, we select the date, and our aggregation (CR or CTR), grouped and sorted by date. A slight peculiarity is hidden in the where clause where another auxiliary method is used.
Here we restrict the result based on the start and end date of our DTO. With the help of the JOOQ DSL trueCondition, we can ensure that our method always returns a Condition object. Even if we do not have a start or end date in our DTO object. This is excluded by the bean validation, but it is common practice to take protective measures in the service class and not rely solely on functions outside of it. In the last part of the method, each data record from the database is converted into the response format using a for-loop.
Let’s complete the AthenaQueryService by adding the missing CTR calculation.
public ChartData getCTR(AnalyticsRequest request) {
Field<BigDecimal> ctrField = saveDiv(sum(ANALYTICS.CLICKS), sum(ANALYTICS.SEARCHES), new BigDecimal(0));
return getKPI(request, ctrField);
}
That’s it!
We should now be able to start the application and call our new endpoints.
# GET the CR. Please adjust from and to accordingly
curl -s "localhost:8080/insights/cr?from=2021-10-04&to=2021-10-11"
# GET the CTR. Please adjust from and to accordingly
curl -s "localhost:8080/insights/ctr?from=2021-10-04&to=2021-10-11"
However, instead of the expected response, we get an Internal Server Error. Looking at the Stacktrace you should see:
org.jooq.exception.DataAccessException: SQL [select `ANALYTICS`.`DT`, coalesce((cast(sum(`ANALYTICS`.`TRANSACTIONS`) as decimal(18, 3)) / nullif(sum(`ANALYTICS`.`SEARCHES`), ?)), ?) from `ANALYTICS` where (true and `ANALYTICS`.`DT` >= ? and `ANALYTICS`.`DT` <= ?) group by `ANALYTICS`.`DT` order by `ANALYTICS`.`DT` desc]; [Simba][AthenaJDBC](100071) An error has been thrown from the AWS Athena client. line 1:23: backquoted identifiers are not supported; use double quotes to quote identifiers
So how do we tell JOOQ to use double quotes instead of backquotes for identifiers? In the world of Spring, this is done mainly by declaring a bean, so here too. Open the SearchInsightsDemoApplication class and add the following:
@Bean
Settings athenaSettings() {
return new Settings().withRenderQuotedNames(RenderQuotedNames.NEVER);
}
If you try the request again, you will fail once again! This time with:
Caused by: java.sql.SQLException: [Simba][AthenaJDBC](100071) An error has been thrown from the AWS Athena client. SYNTAX_ERROR: line 1:1: Incorrect number of parameters: expected 4 but found 0
This is a tricky one as it’s not immediately clear what’s going wrong here. However, after spending a decent amount of time scanning the Athena and JOOQ documentation, I found that Athenas engine in version 1 and its corresponding JDBC driver do not support Prepared statements.
This behavior changed in version 2 of the Engine as the Docs claim. But I haven’t tested it so far … The fix in our case is to add another JOOQ configuration setting withStatementType. This is how our final bean definition looks:
@Bean
Settings athenaSettings() {
return new Settings().withStatementType(StatementType.STATIC_STATEMENT).withRenderQuotedNames(RenderQuotedNames.NEVER);
}
Fingers crossed for our next try, and voila, we have our CR response:
3. How-To create an HTML page to visualize the KPIs in a line chart
The project contains a very minimal frontend that uses Chartjs to render two line charts for CR and CTR. I don’t want to go into detail here; just have a look at the index.html file under src/main/resource/static. Once you start the application, point your browser to http://localhost:8080/ and enter from and to dates in the format yyyy-MM-dd. Afterward, you can press one of the buttons to see the chart rendering
This ends our series on how to develop your own site search analytics that
Is cost-effective
Is highly scalable
Is expandable as it’s self-owned
However, this is only the beginning. For a proper site search analytics tool that you can use to optimize your business, additional KPIs are required. These can be added easily enough if you have the appropriate data.
And that’s a crucial, if not the most important, factor!
Without the RIGHT DATA it’s shit in, shit out!
No matter how good the underlying architecture is, without correct data, an analysis of the search offers no added value. On the contrary, wrong decisions are made from wrong data, which leads to a direct loss of sales in the worst-case scenario. If you want to minimize the risk of bad data, try tackling E-Commerce search tracking yourself and use an open-source solution such as the Search Collector. But please keep in mind that these solutions only provide the framework for tracking data. If used incorrectly, they cause the same problems as commercial solutions.
Do Ecommerce Site Search analytics, but do it properly or not at all!
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.