Information Retrieval (IR) systems are a vital component in the core of successful modern web platforms. The main goal of IR systems is to provide a communication layer that enables customers to establish a retrieval dialogue with underlying data. However, the immense explosion of unstructured data and new ways to interact with IR systems (voice, image…) drives modern search applications to go beyond just fuzzy string matching, to invest in a deep understanding of user queries through the interpretation of user intention (we like the term Query-Understanding) in order to respond with a relevant result set. In short: humans search for things, not for strings.
How to Master the Challenge of locating Things not Strings
Since the problem is not always obvious, I spent some time to find relevant real-life examples that do not require a lot of domain knowledge to judge the result quality.
The good thing, here at searchHub, is that we currently have access to more than 15,000,000 unique search queries from the e-commerce domain. Why is it good? — well, by having access to this kind of information I was able to pick a very representative query — “women red dress size s” — which made it into our top-1000 fashion queries in terms of frequency and into the top-100 queries in terms of value per search. In essence, this query (and it’s variants) drives almost 1 Million USD in revenue per day for our customers!
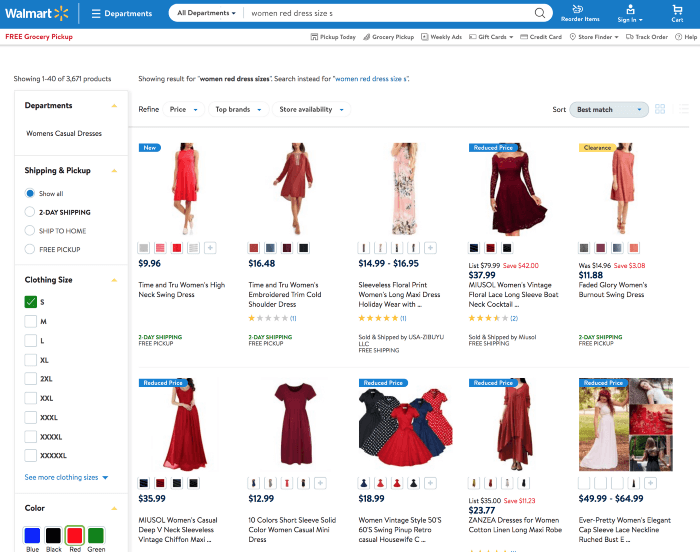
Having found an economically relevant query example I went on to check the results for this query, and it’s top-variant on one of the biggest retail-sites on the planet walmart.com and this is what I received as feedback:
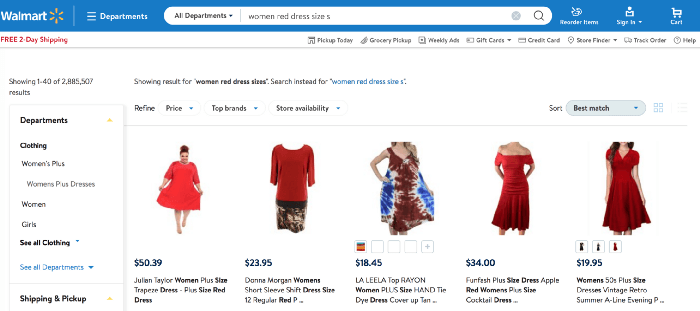
search result for “women red dress size s” on walmartcom
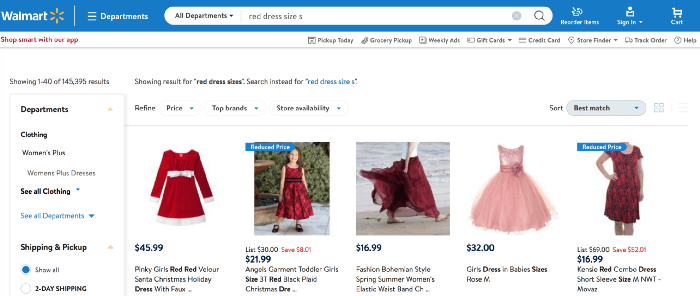
search result for “red dress size s” on walmart.com
I’m not going to criticize these results in detail, but I’m pretty confident that these results do not represent the best possible feedback the system could come up with in terms of economic performance. Why am I saying that? — Well, firstly, there is and will always be a strong correlation between result-size and search conversion rate— the reason for this lies in the “paradox of choice” with search-effort. The impact of result-size vs. search conversion rate increases even more the more specific a query gets.
Unfortunately, still most of the domain owners in search think that this challenge can be solved by a learning-to-rank approach. But you can’t — learning-to-rank will not solve the underlying precision problem. I agree that you might be able to reduce the negative impact by learning to push more relevant products to the top or to the first page, but you’ll still miss 70–80% of the underlying potential!
Let’s be honest: when somebody is willing to spend the effort to articulate a quite specific query like — “women red dress size s” — he has a specific intent and wants to be understood. — Essentially, the visitor is looking for a “red colored dress in size s.
Time for an experiment 🙂
Since Walmart.com is unfortunately not one of our customers yet  we don’t have access to qualitative query performance data. But to test our hypothesis, we did a simple experiment with real-life users.
we don’t have access to qualitative query performance data. But to test our hypothesis, we did a simple experiment with real-life users.
We used the faceted navigation result representing the intent of the given query “red dress size s” on walmart.com. We think that from a precision perspective, this would be the most relevant set of products Walmart could reply to the given query. Then we rebuild the page so that it matches perfectly a search results page in terms of look and feel.
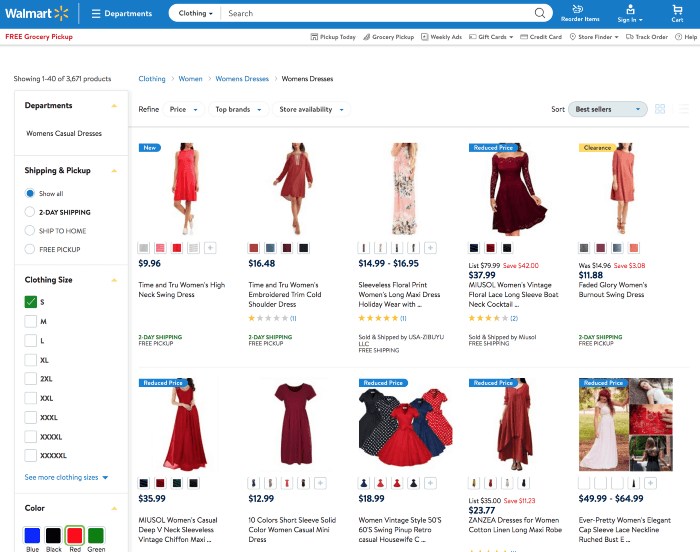
original faceted navigation result representing the intent for the given query “red dress size s” on walmart.com
fake search result for the given query “red dress size s” on walmart.com based on the faceted navigation result
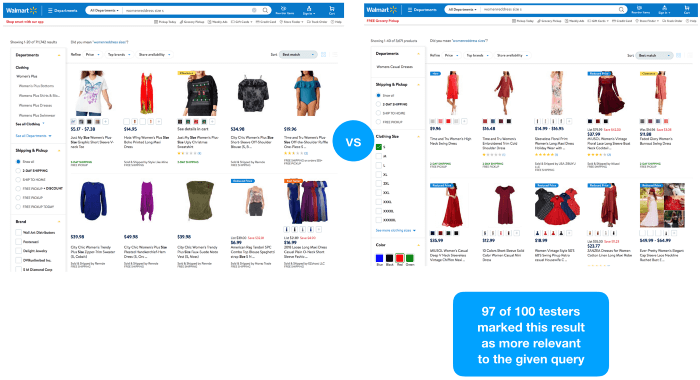
We did the same for our top-3 variant queries, whilst again maintaining the same look and feel. Afterwards, we established a crowdFlower Human-In-The-Loop Search Relevance experiment with 100 users to receive some relevancy judgments for the different variations.
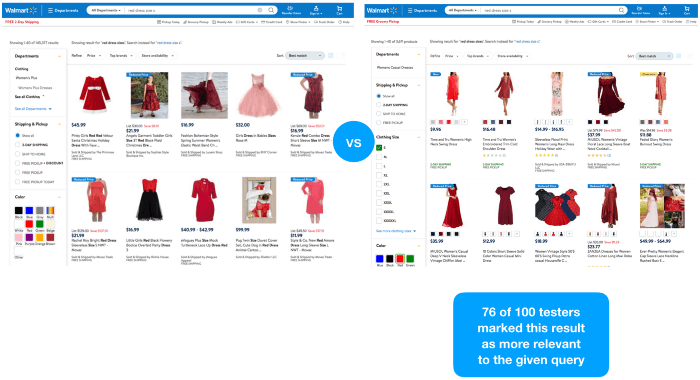
Test results for variation 1 compared to test results for variation 2
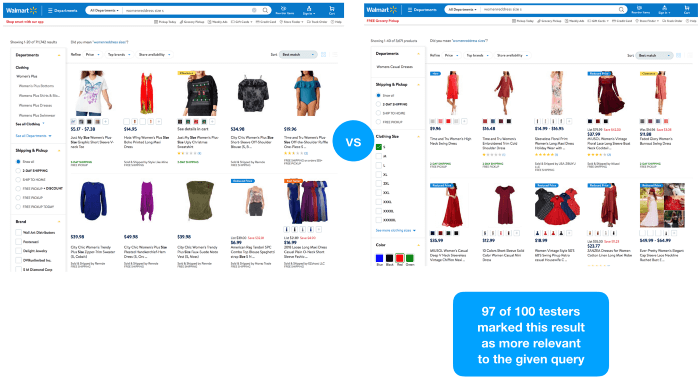
Test results for variation 3
Results
The results speak for themselves. Understanding the intent behind a search query is superior to string matching in isolation. And the reason for this is quite obvious — “people search for things rather than strings” —
The Solution — Query Understanding (We Know “Things”)
Search can and should be a gateway to open-ended exploration and discovery. Sometimes searchers want to be inspired, but most likely come to search with a specific need in mind. Here at searchHub, we work towards understanding user intent with the aim of bridging the gap between user intent and relevant results. We think a search engine should encourage searchers to express their specific needs by driving searchers to create search queries that are more specific. Our goal is to make the leap from query-to-intent less tedious to a more seamless search approach.
Our Approach to Help Humans find Things
Deciphering users’ ‘intent’ is the mind-reading game we have to continuously play with our customers. But how do we do that?
searchHub’s stages of Query Understanding
1. In the first stage, we start by improving the user queries themselves.
Here we take advantage of our superior contextual query correction service which uses our concept of controlled precision reduction control. It automatically handles typos, misspellings, term decomposition, stemming and lemmatization at a yet unmatched level of accuracy and speed.
2. In the second stage, we try to understand the intent/meaning of the query
at this stage, the system tries to extract the entities and concepts mentioned in a query. As a result, search|hub predicts one or more possible intentions with a certain probability, which is particularly important for ambiguous queries.
Most other solutions that attempt to tackle the same problem are using predefined knowledge bases / ontologies to represent dependencies and invoking meaning into the system. We spend a lot of time evaluating existing models and decided to do it differently because we wanted to build a system that learns at scale (different domains), can solve the language gap between visitors and catalog domain experts (wording and language) and even more essential automatically reshapes / optimizes and adapts itself based on explicit and implicit feedback. Therefore, we have developed an automated entity relationship extraction and management solution based on reinforced learning. Another benefit of this solution is that it does not waste computation time and money on building knowledge we don’t need to have
3. Continuously test and learn which query/queries perform best for a given intent/meaning
Another big differentiator of search|hub is that it is entirely data-driven. For quite several queries, there is no single best intent / meaning. In these cases, the right intent / meaning might be dependent on context (time, region, etc.) Therefore, we automatically multivariate test ambiguous queries and query intentions.
The technology behind searchHub is specifically designed to enhance our customer’s existing search, not replace it. With just two API calls, searchHub integrates as a proxy between your frontend application and your existing search engine(s) injecting its deep knowledge.
If you’re excited about advancing searchHub technology and enabling companies to create meaningful search experiences for the people around us, join us! We are actively hiring for senior Java DEVs and Data Scientists to work on next-generation API technology.
www.searchhub.io proudly built by www.commerce-experts.com
