A challenging and highly successful year is drawing to a close. We want to take a moment to pause and thank you for the trust you have placed in us and for everything we have achieved together over the past year. Looking back, 2025 was a year of milestones. Our expertise in E-commerce Search Optimization has grown stronger than ever. Our commitment extends beyond software. Here, we offer you an insight into our greatest successes, our ambitious Vision 2026, and how we live up to our responsibility in the local community.
Gabriel Bauer
2025 Review: Shared Milestones in E-commerce Search Optimization
Your partnership drives our innovations, and your success is our greatest motivation. Thanks to you, we took important steps toward a more human-centric search experience and significantly advanced the field of E-commerce Search Optimization in 2025:
NeuralInfusion Launch: We are excited about the first Beta installations of our groundbreaking NeuralInfusion technology [Link zur NeuralInfusion™ Produktseite]. This lays the foundation for a new age of semantic search intelligence and increased conversion rates, redefining modern E-commerce Search Optimization.
Successful Rollout of Query Suggestions: We saw great success with the rollout of our Query Suggestions feature [Link zur Query-Suggestions/SmartSuggest Produktseite]. This feature delivers more precise suggestions, helping you minimize search abandonment (zero-result pages) and boost revenue.
Community Growth: It was a pleasure connecting with many of you in our newly founded searchHub Community Group on LinkedIn. We appreciate your valuable feedback, which directly informs our product roadmap.
Vision 2026: The Technology that Understands Your Customers’ Needs
Technology should adapt to the human user—not the other way around. This is the foundation of our work and our central objective for the coming year.
For 2026, we are pursuing a clear goal: we want to further improve the connection between user intent and the digital result. Our vision is to evolve our AI to capture the actual needs of people behind search queries even more precisely. We are committed to making sure search doesn’t just find, but truly understands, setting a new standard for E-commerce Search Optimization.
Responsibility in Pforzheim/Enzkreis: More Than Just Software
This holiday season, it is especially important to us to extend the influence of our software company beyond the digital world and strengthen healthy social coexistence right here in our region.
Instead of traditional gifts, this year we are supporting the counseling and prevention work of the non-profit organization amwerden e.V.
We are proud to actively support them in developing a prevention program for primary and secondary schools in the Pforzheim and Enzkreis region. Our common goal is to close the gap between simple media education and individual psychosocial services.
Our Media Competency Curriculum:
Together, we are developing a media competency curriculum that:
Students: Teaches a healthy relationship with digital media.
Teachers and Parents: Offers concrete assistance and guidance—both for school and private life.
Connects Generations: The overarching goal is to foster cooperation between generations and sustainably strengthen the mental and cognitive development of children and adolescents.
Together and Leading the Way in the New Year
We look forward to continuing our partnership with you. In the new year, we remain committed to offering you a leading E-commerce Search Optimization solution while continuing to exert a positive influence on the lives of those around us.
We wish you and your family that we all find time in 2026 to be positive role models in our own spheres of influence—whether at work, in our communities, or at home.
Why Vocabulary Mismatch In Ecommerce Site Search Happens
At a high level, E-commerce Search faces two fundamental challenges. The first is the recall challenge: ensuring that all products potentially engaging to a given search intent are retrieved. The second is the precision challenge: ranking and organizing these products in a way that maximizes user engagement. This blog post will focus exclusively on the first challenge, a core problem in ecommerce site search optimization, which we refer to as the vocabulary mismatch.
When shoppers search for “sneakers” but your catalog only lists “athletic shoes”, or when they type “shirt dress” and instead get “dress shirts”, or when they look for “red valentino dress” but only find “valentino red dresses”, search often fails to meet their expectations.
These are just a few examples of one of the most persistent challenges in information retrieval: the language gap (also called vocabulary mismatch), the difference between how customers describe products and how sellers catalog them. It’s a longstanding problem in search, but in e-commerce its consequences are especially tangible:
Trust erodes when the site search solution “doesn’t understand” the shopper.
Bridging this gap is therefore a critical opportunity to improve both customer experience and business performance in modern e-commerce platforms.
Vocabulary mismatch in e-commerce has many, often overlapping, causes. Some are obvious, others more subtle, but all contribute to the gap between how shoppers express their intent and product descriptions when it comes to exact matching of words or tokens. A more technical explanation follows.
One of the fundamental technical challenges is token mismatch, where morphological, syntactic, and lexical differences across languages prevent direct alignment between query and document terms. This problem is further compounded by inconsistencies in tokenization schemes, variations in transliteration practices, and the scarcity of high-quality parallel corpora particularly for low-resource languages.
Compound Words
Different forms of product-specific compounds: “headphones” vs. “head phones”.
Inflections & Lemmas
Natural language variations: “shoe” vs. “shoes”, “run” vs. “running”. Search systems must handle morphology.
Misspellings & Typos
Common in short queries, they create artificial mismatches that obscure otherwise clear intent.
Syntactic differences:
Conceptual Confusions
Improving query understanding is key, as queries may express concepts rather than single terms, where word order matters: “shirt dress” vs. “dress shirt”, “table grill” vs. “grill table”.
Lexical gaps:
Synonyms & Variants
Classic cases like “sofa” vs. “couch” or “TV” vs. “television”. Without handling, these fragment search results.
Jargon vs. Everyday Language
Sellers use technical or marketing terms (“respirator mask”), while customers use plain words (“face mask”) (playstation 5 vs. PS5). New brand, color, or product-line names appear constantly.
Regional & Multilingual Differences
Geographic variations like “sneakers” (US) vs. “trainers” (UK), or “nappy” vs. “diaper”.
Evolving Language
Trends, slang, and branded phrases shift faster than catalogs: “quiet luxury”, “cottagecore”, “bespoke”.
Current State of Vocabulary Mismatch in Ecommerce
We found a considerable amount of literature addressing vocabulary mismatch in e-commerce. However, most of it concentrates on complementary strategies for mitigating the problem rather than on measuring it. Still, the most common approaches are worth noting: query-side, document-side, and semantic search techniques generally provide more precision. Embedding- and vector-based retrieval methods on the other hand, are typically looser and less exact, favoring broader coverage over strict matching.
Query-side Optimization Techniques
Query Rewriting & Expansion: transform queries into more effective versions. Example: “pregnancy dress” → “maternity dress.”
Conceptual Search / Semantic Search: Our approach to implementing semantic search interprets the underlying user intent to map queries to the product space.
Spell Correction: crucial since typos amplify mismatch.
Document-side Optimization Techniques
Document Expansion: enrich product metadata with predicted synonyms or missing tokens. Walmart’s Doc2Token (2024) helped reduce null search results in production. Attribute Normalization: standardize terms like “XL” vs. “extra large” vs. “plus size.”
Null-search rate (queries with few or zero results) and recall for “low-recall / short” queries + query expansion with BERT-based methods. sigir-ecom.github.io
Null searches were reduced by ~3.7% after applying PSimBERT query expansion. Recall@30 improved by ~11% over baseline for low-recall queries. sigir-ecom.github.io
Addressing Vocabulary Gap (Flipkart / IIT Kharagpur, 2019)
Fraction of queries suffering from vocabulary gap; experiments on rewriting. cse.iitkgp.ac.in
They observe that “a significant fraction of queries” suffer from low overlap between query terms and product catalog specifications. While they don’t always put a precise “% of queries” number for all datasets, they show substantial performance degradation for these queries, and that rewriting helps. cse.iitkgp.ac.in
Doc2Token (Walmart, 2024)
How many “missing” tokens are needed in product metadata; what fraction of queries target tokens not present in descriptions. arXiv
The paper describes “novel tokens” (i.e. tokens in queries that aren’t in the product document metadata). They found that document expansion paying attention to those “novel” terms improves search recall & reduces zero-result searches. The exact fraction of missing tokens varies by category, but it’s large enough that, in production A/B tests, the change was statistically significant. arXiv
Graph-based Multilingual Retrieval (Lu et al., 2021)
Multilingual and cross-locale query vs product description mismatch; measure improvement by injecting neighbor queries into product representations. ACL Anthology
They report: “outperforms state-of-the-art baselines by more than 25%” in certain multilingual retrieval tasks (across heavy-tail / rare queries) when using their graph convolution networks. This indicates that the vocabulary gap (especially across languages or speech/colloquial vs. catalog language) is large enough that richer models give big gains. ACL Anthology
But how big is the vocabulary gap?
While many efforts focus on bridging the vocabulary gap with the latest technologies, we found that actually quantifying vocabulary mismatch is far from simple. Its magnitude varies significantly depending on factors such as the domain, catalog size, language, and metadata quality. In fact, we identified only a few studies (cited above) that report meaningful metrics or proxy KPIs. These can indeed serve as useful signals for diagnosing the severity of the problem and for prioritizing improvements. However, they still fall short of capturing the full scale and subtle nuances of the mismatch.
To make well-founded and impactful product development decisions, we need a deep understanding of the vocabulary mismatch problem, its scale as well as its nuances. This is why we invested significant time and resources into conducting a large-scale study on vocabulary mismatch in e-commerce.
Large-Scale Study of Vocabulary Mismatch in E-commerce
Since vocabulary mismatch arises from many sources, our first step was to isolate and measure the individual impact of these causes. We analyzed more than 70M unique products and more than 500M unique queries, filtered according to our top 10 languages (EN,DE,FR,IT,ES,NL,PT,DA,CS,SV).
We initially planned a cross-language meta-analysis, but the analysis phase showed substantial inter-language differences and effect sizes, making pooling inappropriate. We’re therefore analyzing each language separately. We’ll begin with German, since it’s our largest dataset, and integrate the other languages in a later phase. The German dataset consists of 110 million unique queries and 28 million unique products with associated metadata. After tokenizing by spaces and hyphens (where the split yields valid, known tokens), we obtain 132,031,563 unique query tokens and 10,742,336 unique product tokens to work with.
Impact of Misspellings:
Since the primary goal of this analysis is to measure vocabulary mismatch, it is essential to begin by defining what we mean by vocabulary. In this context, vocabulary refers to the set of valid and actually used words or tokens across different languages. Because auto-correction, the accurate handling of misspelled tokens and phrases, is one of the most frequently applied (and most sophisticated) strategies in searchHub, it is important to first assess the extent of misspellings and exclude them. According to our definition, misspelled terms do not belong to the vocabulary and should therefore be filtered out while quantifying the vocabulary mismatch problem.
shared-token-ratio between search queries and product data across with and without misspellings
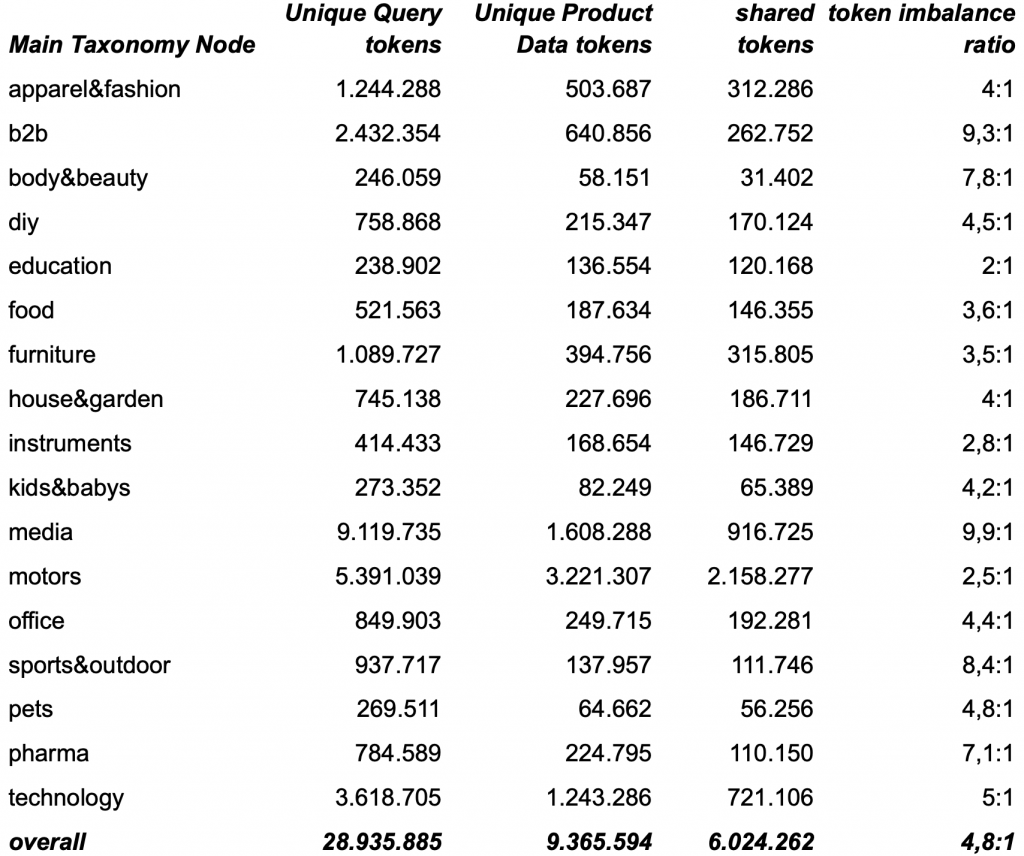
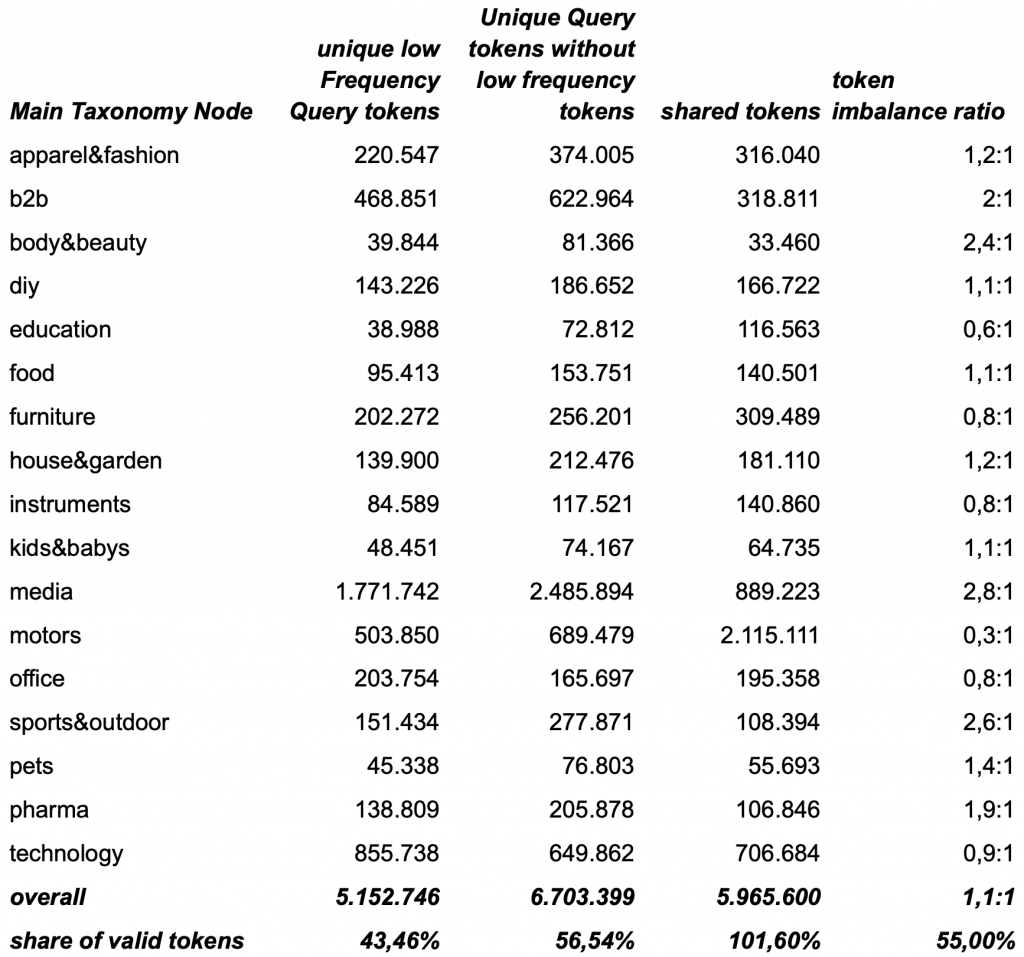
Filtering out misspellings reduces the amount of unique query & product-data tokens significantly (almost 7x). After excluding them, we first started with some simple statistics taking our Taxonomy-Nodes into account that revealed that the user query corpus contains on average 4.8x more unique valid tokens than the product corpus. As an important sidenote we should point out that the token imbalance ratio significantly varies across the taxonomy nodes.
shared-tokens and token imbalance-ratio between search queries and product data across our main taxonomy nodes
It’s important to note that both raw data sets (search queries and product-data) are messy, created mostly through manual input by people with often different domain expertise, and therefore some data cleansing practices like normalization & harmonization have been applied to see if this changes the picture.
Impact of Normalization & Harmonization on morphological differences
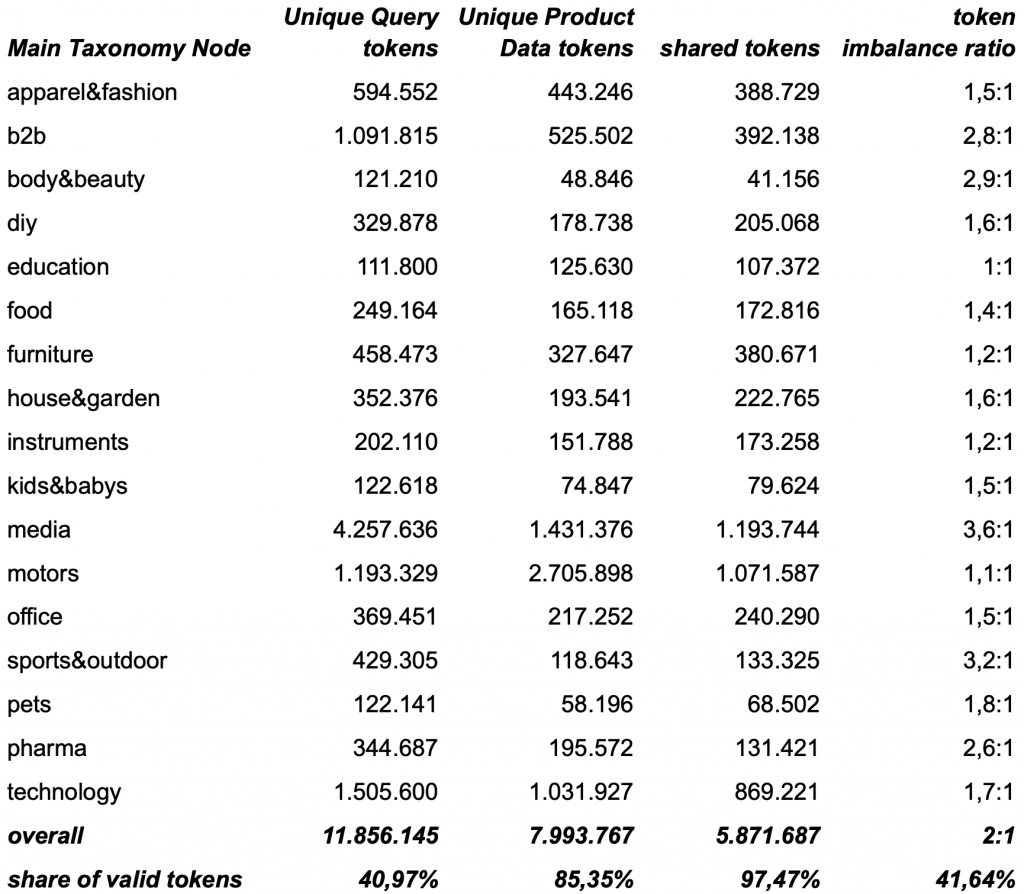
At searchHub, our AI-driven site search optimization excels at data normalization and harmonization, which are core strengths alongside spelling-correction. We therefore applied our probabilistic tokenization, word-segmentation, our morphological normalization for inflections and lemmas and our quantities and dimensions normalization for common attributes such as sizes and dimensions, quantities and others. After updating the analysis, the picture already shifted significantly:
Inconsistencies occur on both sides, about ~15% in product data and ~60% in queries. But their nature differs: queries suffer mostly from word segmentation issues, messy numeric normalization, foreign language vocab, and inflections, while product data issues stem mainly from compound words and inconsistent formatting normalization (dimensions, colors, sizes, etc.).
shared-tokens and token imbalance-ratio between search queries and product data across our main taxonomy nodes after normalization and harmonization
After normalization and harmonization the language corpus of queries has been reduced by ~59% while the product data corpus has been reduced by ~15%. It seems that normalization and harmonization reduce the language gap by roughly ~60%, as we have reduced the token imbalance ratio from 4.8:1 to 1.9:1. However looking closely at the table above reveals something interesting. While most taxonomy nodes now have an imbalance ratio of ≤ 2:1, but a subset remains markably skewed. A closer review points to two main drivers:
foreign-language vocabulary concentrated in Apparel & Fashion, Sports & Outdoors, and Pharma
rare identifier-like tokens occurring across B2B and Pharma.
Impact of foreign vocab on mismatches in ecommerce search
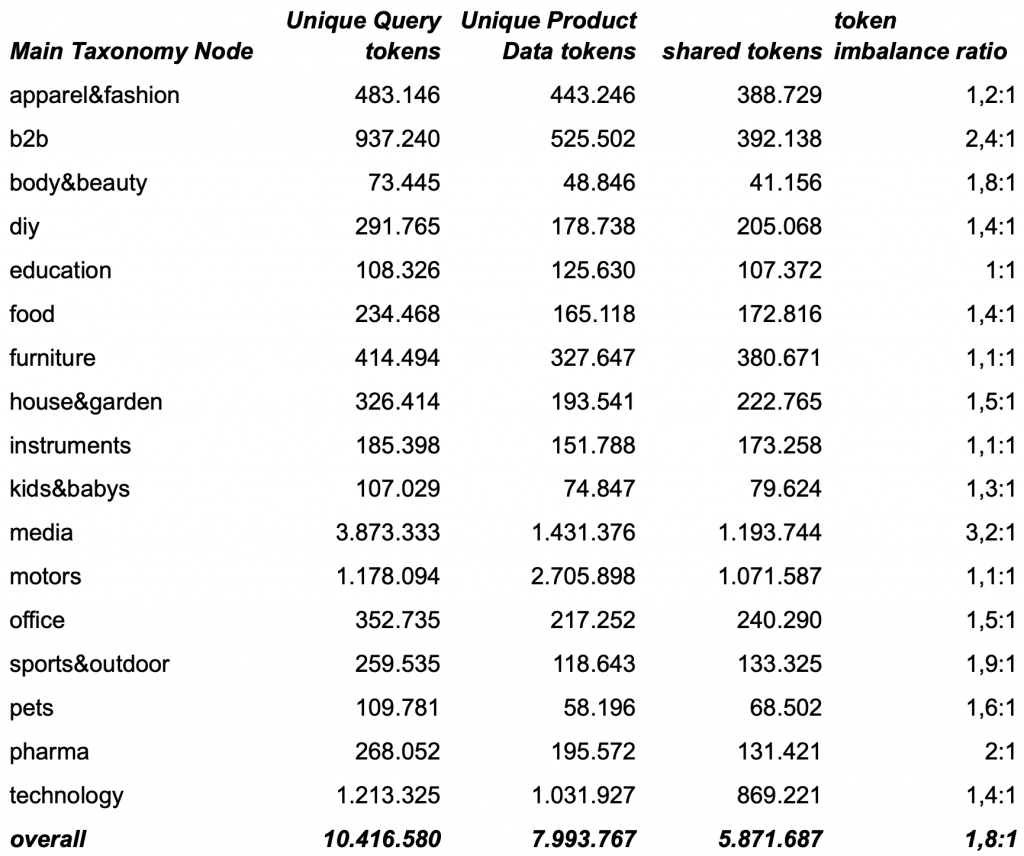
shared-tokens and token imbalance-ratio between search queries and product data across our main taxonomy nodes after removing foreign vocab
Removing the foreign, but known vocabulary reduces the imbalance ratio by roughly another 10%, which is more than we anticipated. But it seems that marketing related vocab like brand names, specific productLine names and product-type jargon play a significant role in some taxonomy nodes (zip-up, base-layer, eau de toilette, ….).
Impact of evolving language and infrequent vocabulary
As a next step we are going to try to quantify the impact of evolving language (vocabulary), focusing on the impact of both newly emerging tokens and very infrequent ones (frequency <2 over one year of data). This step is challenging because it requires distinguishing between genuine new vocabulary and simple misspellings of existing terms which might be the reason why we couldn’t find any generally available numbers about it.
Another strength of our stack is its ability to learn & update vocabularies across languages, customers and segments. That said, like any ML-based approach, it is not flawless. To ensure reliability, we follow a precision-first strategy: for this analysis, we only include cases where the system is ≥99% confident that a token represents valid new vocabulary over a time period of one year, excluding all others.
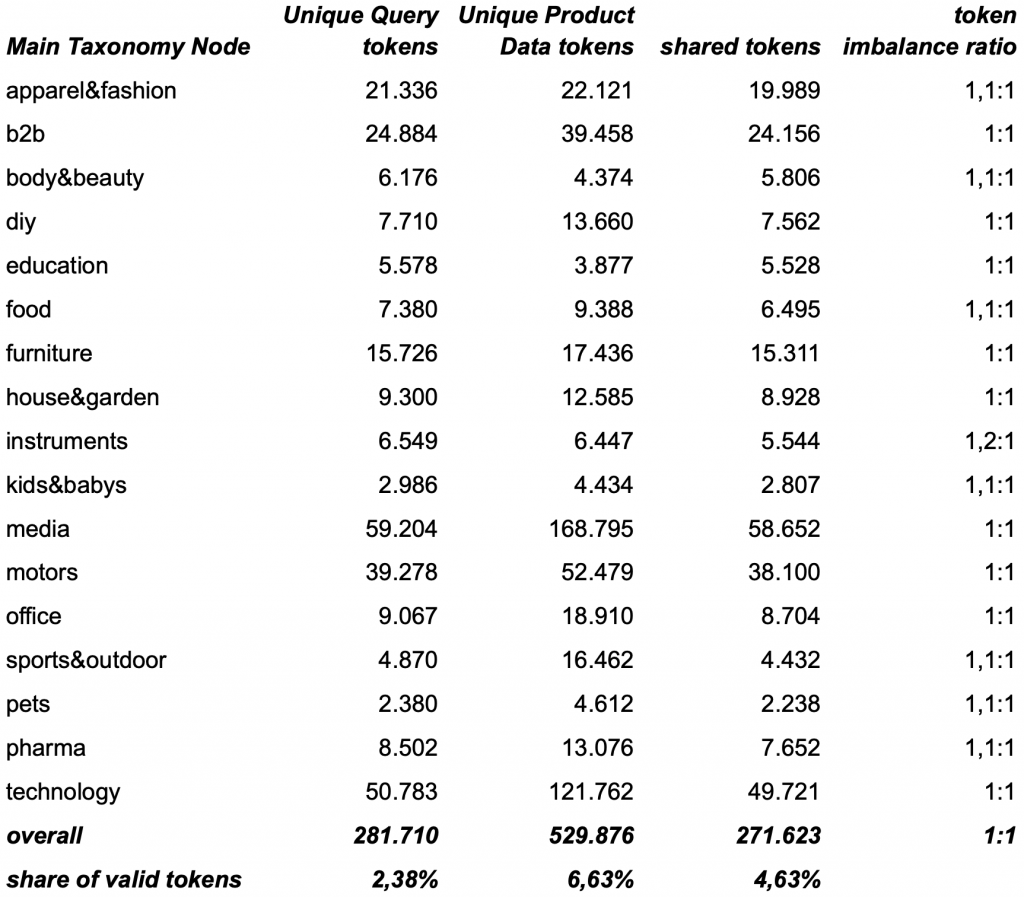
shared-tokens and token imbalance-ratio for new vocabulary between search queries and product data across our main taxonomy nodes
As expected, both sides show a steady influx of new vocabulary. However, the magnitude of change strongly depends on the product type / product segment, represented by the taxonomy node. Some segments exhibit relatively stable vocabularies over time, while others experience frequent shifts and updates. Mentionable types are productLine names, brand names, new trademarks and productModel names, materials, as well as somehow a never ending flow of newly created fashion color names. Interestingly, nearly 50% of the new vocabulary introduced into the product data over time does not appear to be adopted by users.
The impact of this type of vocabulary gap is not immediately obvious but becomes clearer when viewed longer term. Users often start adopting and using new product vocabulary popularized through marketing campaigns before the corresponding product content is indexed in eCommerce search engines, often due to stock or availability constraints. In many cases, this gap closes naturally once the relevant content is indexed.
Having quantified the effect of new tokens, we can now refine the analysis further by examining the share of infrequent tokens within query logs, where “infrequent” is defined as appearing in fewer than two unique searches over the span of one year.
shared-tokens and token imbalance-ratio for search queries with low frequency across our main taxonomy nodes
Surprisingly, a substantial share of valid words or tokens occur very infrequently (frequency ≤ 2) about 43% in queries and 23% in product data. At the same time, it is evident that this further amplifies the vocabulary imbalance between the two sides. Honorable mentions of types in this area are single product company products, product-model names, niche-brands and attribute or use-case specific vocab and tokens containing no useful information.
We specifically wanted to quantify the impact of very infrequent vocab since, to our knowledge, it accounts for most of the problematic or irrelevant search results when applying techniques to close the gap.
Summary:
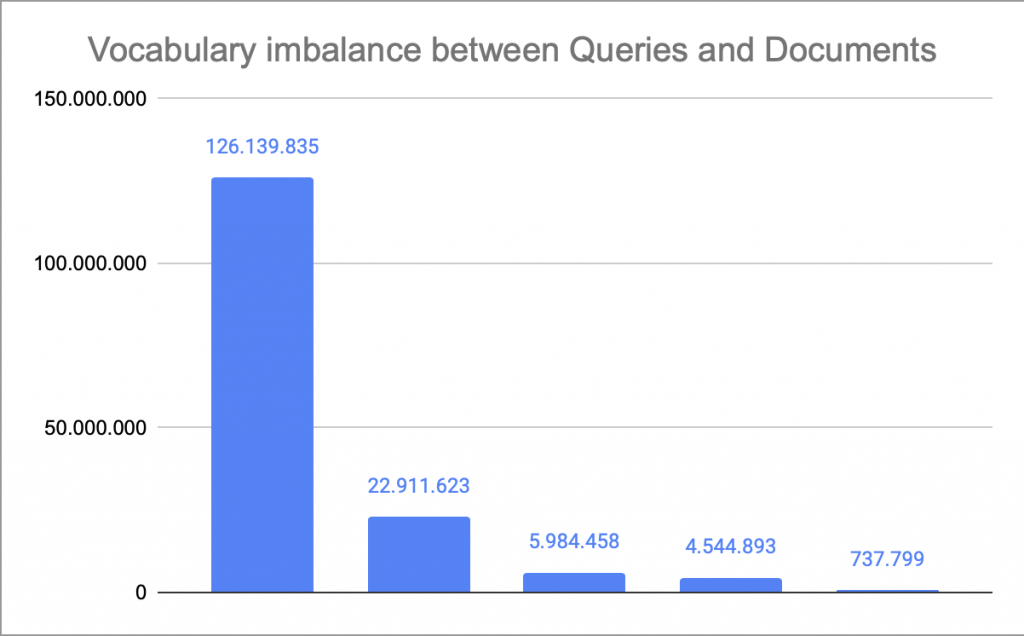
So far, we have demonstrated scientifically that misspellings and morphological differences down to their major nuances are the most influential factors in closing the language gap. We were able to reduce the token imbalance ratio from 22:1 down to 1.9:1. From there filtering low frequent vocabulary gets us down to 1.1:1.
When search traffic (i.e., the number of searches per query) is taken into account, this influence also seems to stay almost equally strong. Our mapping data shows that, depending on the product vertical, effectively handling morphological nuances and being able to detect new vocab alone resolves between 81-86% of the language gap.
Conclusion
The goal is simple: make sure that when customers ask for what they want in their own words they actually find it. And when they do, conversions and customer satisfaction follow.
As shown, vocabulary mismatch remains one of the most stubborn problems, but one that the right e-commerce search best practices can solve. Customers rarely describe products the same way sellers list them. The solution is multi-pronged: query rewriting, document expansion, embeddings, and feedback loops all play a role.
Now that we understand the key drivers and their quantitative impact, we can focus on efficient, effective fixes. Notably, well-tuned, deterministic NLP steps reduced the language gap from 126,139,835 to 4,601,864 tokens (≈97%).
Next, we’ll assess how the impact of syntactic differences and of synonyms/variants distribute over the last 3%, and try to find the best solutions for them. For example, we’ll test whether the remaining gap can be closed by learning from sparse signals (few occurrences) and by leveraging LLMs’ generalization capabilities.
For B2B E-commerce Website Managers, Owners, and Operators
The “No Results Found” page: a seemingly innocent screen, yet in the complex world of B2B e-commerce, it’s a silent assassin of conversions, trust, and ultimately, revenue. For businesses operating in niche markets with highly specialized and technical product catalogs, the stakes are even higher. Every frustrated click represents a lost opportunity to connect a buyer with the exact product they need, often after a significant investment in acquiring that traffic.
This guide is for B2B e-commerce leaders wrestling with ineffective site search. We’ll dissect why “no results” is a conversion killer, pinpoint its hidden causes, and unveil practical ecommerce search best practices. Most importantly, we’ll show how an AI-driven site search strategy can transform your search bar from a frustrating dead end into an intelligent, proactive guide for your customers.
1. Why ‘No Results’ Is a Conversion Killer
Imagine a qualified buyer—an engineer or procurement manager—landing on your site with a specific part in mind. They head straight to your search bar, type in their precise query, and are met with… a blank page.
This isn’t a minor inconvenience; it’s a critical breakdown in the customer journey with cascading negative effects:
Immediate Revenue Loss: The most obvious impact. A buyer who can’t find what they need, even if it’s in your inventory, will go elsewhere.
Erosion of Trust and Credibility: A poorly functioning search suggests a poorly managed website. For B2B buyers who rely on precision, this undermines confidence in your entire operation.
Increased Bounce Rates: Dead ends frustrate users, causing them to abandon your site. This harms your SEO performance by signaling a poor user experience to search engines.
Wasted Marketing Spend: You’ve invested heavily to drive qualified leads to your website. If your site search then fails to convert them, that acquisition budget is wasted.
Missed Upsell Opportunities: A smart search can recommend related products or alternatives. “No results” pages cut off these revenue-generating opportunities entirely.
Damaged Brand Reputation: In a competitive B2B landscape, a reputation for a clunky website can be as damaging as a poor product.
The underlying issue is that a “no results” query is not the absence of intent; it’s a clear signal of demand. Your customer is telling you exactly what they want. Failing to respond is a monumental missed opportunity.
2. Identifying the Root Causes of “No Results Found”
Understanding why your site search falters is the first step toward a solution. In niche B2B e-commerce, the reasons are often complex:
Typographical Errors and Misspellings: Even for technical terms, typos are common. A conventional search engine that lacks sophisticated query understanding will fail on simple errors like “hydrolic pumpe” instead of “hydraulic pump.”
Synonyms, Jargon, and Industry-Specific Terminology: B2B industries have their own lexicon. Your search needs to understand that “PCB,” “Printed Circuit Board,” and “logic board” all refer to the same thing. This is a challenge of semantic search.
Lack of Product Metadata: Insufficiently detailed product descriptions or missing technical specifications severely limit the search engine’s ability to match queries to products.
Product Availability: A search for an out-of-stock item shouldn’t lead to a dead end. It’s a chance to offer alternatives or back-in-stock notifications.
Variations in Product Naming: Subtle differences in model numbers (e.g., “XYZ-123-A” vs. “XYZ123A”) can easily confuse basic search engines.
Long-Tail and Highly Specific Queries: B2B buyers often search with very specific, multi-word phrases. Standard keyword matching struggles with the nuance of these high-intent queries.
Poor Indexing or Catalog Management: If your product catalog isn’t properly indexed, relevant items simply won’t appear in search results.
Legacy Search Engine Limitations: Many out-of-the-box site search solutions rely on basic keyword matching. They lack the advanced AI capabilities to understand user intent, context, and semantic relationships.
Lack of Continuous Optimization: Site search isn’t “set it and forget it.” Without ongoing analysis and refinement, your search performance will degrade over time.
3. Strategies for a ‘No-Dead-End’ Search Experience
Let’s explore actionable strategies to transform “no results found” into “we found something valuable for you.” These foundational ecommerce search best practices are crucial for success.
3.1. Robust Data Foundation
Before any AI can work its magic, your product data must be impeccable.
Enrich Product Metadata: Go beyond basic descriptions. Include all relevant technical specifications, attributes, and the like.
Standardize Naming Conventions: Implement consistent naming structures for products and categories to reduce ambiguity.
Replace “miscellaneous” Category with proper sub-categories.
Regular Data Audits: Periodically review your product data for accuracy, completeness, and consistency.
3.2. Analyze and Optimize with Search Performance Data
With a solid data foundation in place, the next pillar of a ‘no-dead-end’ strategy is continuous analysis and optimization. How do you measure what’s working, find what isn’t, and act on that information? This is where you must leverage your search performance data.
The searchHub searchInsights dashboard is your command center for this task. It’s a dedicated analytics suite within the searchHub UI that gives you a transparent view into your search performance.
Inside searchInsights, you can:
Act on Zero-Result Searches: Get automatically notified about keywords that returned zero results. More importantly, searchInsights provides actionable suggestions on how to fix them, allowing you to quickly turn frustrating dead ends into successful conversions.
Track Meaningful KPIs: Move beyond simple query counts and monitor crucial e-commerce metrics like whether users are engaging with results, or identifying searches actually leading to purchases.
Validate Your Optimizations: To prove what works, you can leverage powerful query A/B testing. These tests run fully automated in the background, allowing you to compare the performance of different strategies for the same query, ensuring your optimizations are always backed by hard data.
By providing this deep, actionable understanding of your search performance, searchInsights equips you to make smarter strategic decisions.
3.3. Proactive Site-Search-Experience Design
Intelligent Auto-Suggestions: As users type, provide real-time suggestions for high-converting products, to prevent typos and guide users toward relevant terms.
Query Relaxation and Partial Matching: If a specific query yields no results, the search should automatically “relax” the query to show broader, yet still relevant, results.
Alternative Recommendations: If the exact item isn’t found, leverage product data to recommend similar products or suitable alternatives.
Strategic “No Results” Page Design: This page is an opportunity. Clearly state that no exact matches were found, but offer solutions like links to popular categories, best-selling products, and prominent customer support contact information. Find a good (and legal!) strategy to deal with searches for competitor products or brands you do not list.
4. Using AI to Proactively Guide Users: The searchHub Advantage
This is where the game truly changes. Traditional approaches to reducing “no results” are reactive and manual, requiring constant human intervention. In the complex B2B landscape, this is unsustainable.
searchHub is not a new search engine. This is a crucial distinction. We understand you’ve invested heavily in your current infrastructure, like Elasticsearch or Solr. Instead, searchHub enhances your existing site search by adding a powerful layer of keyword intent mapping to improve site search performance.
Here’s how we leverage AI to eliminate “no results found” pages:
4.1. Translating Customer Intent with smartQuery
The core of searchHub’s innovation is its ability to understand customer intent, not just match keywords. Using smartQuery, our AI analyzes user behavior, click-through rates, and conversion data. This contextual understanding allows searchHub to infer what the user really wants, even if their query is imprecise. Our algorithms continuously learn from your specific product data and user behavior, ensuring the system is always adapting to your audience.
4.2. smartQuery: Automating Keyword Clustering for Ecommerce
This is a powerful differentiator. smartQuery doesn’t just swap keywords around; it performs automated keyword clustering for ecommerce. Imagine a thousand ways a customer might search for a “heavy-duty industrial valve.” They might use “high-pressure valve,” “large flow control,” or even incorrect part numbers. Our AI identifies that these diverse queries represent the same underlying intent and groups them into a single, cohesive “query cluster,” automatically capturing the vast long tail of B2B search.
4.3. Defining a Best Performing Query (MasterQuery)
Within each cluster, smartQuery intelligently defines a “best performing query”—what we call a MasterQuery. This isn’t arbitrary. The AI evaluates KPIs for every query within the cluster:
Did it produce results?
Was there interaction with the results (clicks) or only doom-scrolling? – we call this “findability”.
Was something added to the cart?
Did a purchase occur? – we call this “sellability”.
By analyzing these metrics, the AI identifies the single query that most consistently leads to conversions. This MasterQuery becomes the funnel point for all related traffic.
4.4. Funneling Traffic with AI-Powered Search Redirects
Once the MasterQuery is identified, our unique mechanism comes into play. When a user types a query from a cluster (like a typo or synonym), smartQuery intercepts it. Instead of sending the original, problematic query to your site search, it sends the designated, high-performing MasterQuery.
No Replacement, Just Enhancement: Your existing search engine receives a “clean,” high-performing query, dramatically reducing “no results” pages and improving relevance.
Simplified Optimization: You no longer need to manually create and maintain endless lists of synonyms or redirects. searchHub automates this complex optimization process, freeing up valuable resources.
Enhanced Landing Page Potential: By channeling traffic through MasterQueries, you gain clear insights for targeted merchandising and landing page optimization without having to account for every keyword variation.
The result is a site search that is significantly more robust in handling variations, typos, and nuanced B2B terminology, leading to fewer zero-result hits and higher conversion rates.
In the competitive landscape of B2B e-commerce, the “No Results Found” page is a glaring symptom of a missed opportunity. By welcoming an AI-driven site search optimization strategy with searchHub, you transform these dead ends into dynamic pathways to conversion, building trust and driving significant revenue growth.
In the competitive landscape of B2B e-commerce, the on-site search bar is more than a utility; it’s your most valuable salesperson. It’s the digital equivalent of a customer asking, “Where can I find…?” If your site search can’t understand the nuance and user intent behind that question, you’re not just losing a sale—you’re losing a customer.
This is where semantic search comes in. It’s not about overhauling your entire system. It’s about making your existing search bar smarter through AI-driven site search optimization. This guide, inspired by the searchHub methodology, will walk you through a practical approach to implementing semantic search, designed for mid-sized e-commerce businesses looking for a competitive edge without a complete technological rebuild.
What is Semantic Search and Why It Matters
At its core, semantic search is the ability of a search engine to understand the intent and contextual meaning behind a user’s query, rather than simply matching keywords. Traditional, or lexical, search looks for literal matches. If a user searches for “protective work gloves for cold weather,” a lexical search might struggle if your product is listed as “insulated safety mittens.” It sees different words and often returns zero results—a frustrating dead end for a motivated buyer.
Semantic search, however, goes deeper. It understands that “gloves” and “mittens” can be synonyms, that “cold weather” implies “insulated,” and that “protective work” relates to “safety.” It deciphers the user’s goal and provides the most relevant results.
Why is this a game-changer for your B2B store?
Drastically Improved User Experience: B2B buyers use specific, technical, or long-tail queries. They expect your site to understand their jargon. When your search can handle synonyms and conceptual queries, you eliminate friction and build confidence.
Higher Conversion Rates: A better search experience directly translates to more sales. When customers find what they’re looking for on the first try, they are significantly more likely to convert. Semantic optimization connects buyer intent with the right product.
Actionable Customer Insights: The queries your customers use are a goldmine of data. Analyzing them through a semantic lens reveals not just what they are looking for, but how they think about your products.
Crucially, with a tool like searchHub, this doesn’t mean you need to replace your existing site search engine. The goal isn’t to be a search engine; it’s to optimize the one you already have. By improving query understanding, you can guide your current system to perform at its absolute best.
Common Challenges for Mid-Sized Retailers
While the benefits are clear, mid-sized e-commerce businesses face unique obstacles.
The Synonym and Jargon Problem: A “hex key” is also an “Allen wrench.” Manually maintaining synonym lists for thousands of SKUs is a Herculean task that isn’t scalable. This is where the automation provided by a platform like searchHub becomes essential.
The “Long-Tail” Keyword Conundrum: Traditional search engines often fail with multi-word phrases like “12-volt DC submersible water pump with 2-meter head,” breaking them down and returning irrelevant results. This is a classic failure of query understanding that searchHub is designed to solve.
The Dreaded “Zero Results” Page: This is the ultimate conversion killer. Every “zero results” page represents a missed opportunity. The goal is to reduce null search results by intelligently understanding the user’s true intent, ensuring you connect them with products you already have.
Limited Technical Resources: You probably don’t have a team of AI engineers on standby. You need a solution like searchHub that is powerful yet practical, one that leverages advanced technology without requiring you to build it yourself.
Step-by-Step Implementation Guide
Here’s a practical, four-step guide to ecommerce site search optimization. This is the core process that searchHub automates to deliver results, enhancing your current search engine by intelligently managing queries.
Step 1: Gather and Analyze Your Search Query Data
Your first step is to become an expert on what your customers are asking for. Use searchHub searchCollector to gather the highest quality search data. Collect at least four to six weeks of search query data. This data is the foundation of optimization and is made accessible through the searchHub searchInsights dashboard. You’ll want to collect:
The search term itself
Frequency (number of searches)
Click-through rate (CTR)
Conversion rate
Number of “zero results” instances
Step 2: Use AI to Cluster Queries by Intent
Manually sorting thousands of queries is impossible. This is where searchHub’s smartQuery feature applies AI and machine learning for keyword clustering for ecommerce. The goal is to group semantically related queries based on user intent. For example, an AI model recognizes that “men’s size 11 waterproof hiking boots” and “waterproof trekking shoes for men 11” share the same intent and groups them into a single “intent cluster.”
Step 3: Identify the “Best Performing” Query in Each Cluster
Not all queries are created equal. Within each intent cluster, one query will inevitably perform better on your existing search engine. Using the data from Step 1, smartQuery analyzes the performance of each query within its cluster. For our hiking boot example, you might find:
Query
CTR
Conversion Rate
“men’s size 11 waterproof hiking boots”
65%
8%
“waterproof trekking shoes for men 11”
45%
5%
“gore-tex hiking boot male size 11”
30%
3%
“best size 11 boots for mountain trails”
25%
2%
Here, “men’s size 11 waterproof hiking boots” is the clear winner. This “Master Query” unlocks the best possible outcome from your existing search infrastructure.
Step 4: Funnel All Related Traffic to the Best Result
This final step is the most critical. Now that you’ve identified the top-performing query for each group, searchHub’s smartQuery automatically funnels all queries within that cluster to the search results page of the best-performing query.
When a user searches for the low-performer (“gore-tex hiking boot male size 11”), they are automatically shown the results for the high-performer. The user gets the best possible experience, and you’ve created a semantic layer on top of your existing search engine. This method elegantly solves the core challenges:
Synonyms and long-tail queries are handled automatically.
“Zero results” pages are dramatically reduced.
It requires no change to your existing search engine. You are simply optimizing the traffic that flows into it, making it work smarter, not harder.
Measuring Success
To prove value, you need to track the right Key Performance Indicators (KPIs), which platforms like searchHub centralize in a searchInsights dashboard.
The Real Way to Calculate Conversion Rate from Search: The ultimate metric. Search Conversion Rate = (Number of unique items ordered from search / number of unique search trails) x 100%
Reduction in “Zero Results” Rate: Shows your intent clustering is effective. Zero Results Rate = (Number of Searches with Zero Results / Total Number of Searches) x 100%
Search-Led Revenue: Ties your optimization efforts directly to the bottom line.
Click-Through Rate (CTR) from Search Results: Shows your results are more relevant.
To get a definitive measure, run an A/B test comparing the original experience to the new, intent-funneled experience. The data will provide clear, undeniable proof of the ROI.
In conclusion, transforming your on-site search is one of the highest-impact investments you can make. By focusing on understanding and optimizing for user intent, you can create a superior user experience and unlock the revenue hidden in your search data. The path forward isn’t about a bigger budget or a risky “rip and replace” project; it’s about a smarter strategy, powered by searchHub.
Motivation: In the Beginning, There Was One Tenant…
When starting a new Apache Solr project, your setup is usually straightforward—one language, one tenant, one tidy schema file.
You get everything running perfectly…
“…and you see that it is good!”
Adding another tenant, say expanding from Germany to Austria, doesn’t create many challenges. You still have similar configurations: same language, same synonyms, same analysis.
“…and you see it’s still good!”
But trouble arises when you grow further—introducing more countries, more languages, and more complex configurations. Synonyms change, text analysis gets complicated with different stemmers, and unique fields pop up everywhere.
Suddenly, your clean configs turn messy and confusing.
“…and you see it’s no good anymore!”
You start leaving marks everywhere in your configs to keep track of what’s specific and what’s shared, feeling more lost by the minute. But relax, there’s an elegant, developer-friendly solution: Jinja2 templating.
The Solution: Enter Jinja2 Templating
If you’re a Solr developer who likes Python, Jinja2 is your friend. With it, you maintain a single, central configuration template, embedding placeholders where tenant-specific differences exist. You never repeat yourself unnecessarily, making everything neat and manageable again.
Here’s how simple it is:
Create one main template for shared config settings.
Use placeholders to mark tenant-specific items.
Define these differences in small, individual tenant-specific files.
Render your configurations automatically, painlessly, with a Python script.
“…and you see that it’s good again!”
How to Use Jinja2 in Your Solr Project (Examples)
You only need to understand three core concepts:
extends: to base tenant configs on a shared template.
set: to define variables unique to each tenant.
block: for inserting full sections unique to certain tenants.
Example: Multilingual schema.xml Config
Step 1: Extend your central template.
{% extends "template.schema.xml" %}
Step 2: Set your tenant-specific placeholders.
In your central template (template.schema.xml), use placeholders clearly:
If you don’t define the block in the tenant-specific file, it remains empty.
A small Python script neatly handles generating your configurations automatically:
A small Python script automates rendering your final Solr config files:
from jinja2 import Environment, FileSystemLoader
def write_template(pathToTemplate, templateFileName, targetFileName, targetEnv, tenant):
environment = Environment(loader=FileSystemLoader(pathToTemplate))
template = environment.get_template(templateFileName)
content = template.render()
filename = f"{targetEnv}/{tenant}/{targetFileName}"
with open(filename, "w", encoding="utf-8") as message:
message.write(content)
print(f"... wrote {filename}")
pathToTemplate : defines in which directory your template files are located; one folder per file type (schema, solrconfig, etc.) helps to easily find what you are looking for.
templateFileName : the file name of the (language or tenant) specific template, e.g. template.schema.de.xml
targetFileName : the file name of the final config file (schema.xml or solrconfig.xml)
targetEnv : in this example we also have several different environments, such as “dev,” “qa,” or “prod.” So each of those stages has its own set of config files. This enables you to test new config changes before you deploy and destroy your production environment. 😉
tenant : For the schema.xml, templates have been set up per language but used for multiple tenants. That’s why it’s not only the tenant. This might be different in your setup, of course, so feel free to adapt how the files are organized.
Now you are ready to call your function to actually render some config files. We do it here for both dev and qa in one step, and for a list of defined tenants. The language code is taken from the tenant name:
for env in ["dev", "qa"]:
for tenant in ["DE-de", "AT-de", "NL-nl"]:
language = tenant.split("-")[1]
pathToTemplate = "templates/schema/"
templateFileName = f"template.schema.{language}.xml"
targetFileName = "schema.xml"
write_template(pathToTemplate, templateFileName, targetFileName, env, tenant)
Note: Ensure directories exist before running this script.
Now you can set up the same for the solrconfig.xml and render both file types in your code. This will give you a complete config for each environment and each tenant that you can now upload to your Solr installation.
Final Thoughts: Quick Tips for Agile Config Management
Templates are powerful, but during rapid testing, editing configs directly can sometimes speed things up. Once you’re happy, move changes back into templates to effortlessly roll them out.
“…and once again, you’ll see that it’s good!”
Jinja2 templating makes Apache Solr configurations manageable, structured, maintainable, and scalable, letting you efficiently handle complexity without losing your sanity.
Monday, March 31st – incident report
On Monday, March 31st, searchHub’s infrastructure had its first measurable downtime for years. Between 11:30 UTC and 12:38 UTC, numerous systems, including our UI used to analyze and manage search, were practically unavailable. In this post, I want to explain what happened and how it is connected to our current global situation.
To begin …
searchHub was built by design to run independent of customer systems. That’s why more than 90% of our customers didn’t even realize that there was a problem, as their system ran totally normal. All customers who follow our recommended integration method use a small but mighty client system that holds all necessary data to optimize search in real-time without the need to do synchronous calls to the outside world. That’s how we not only achieve extremely low latency, but (as we have seen on Monday) also a very comforting level of independence. No single point of failure. No submarine that can destroy an underwater cable connection, as there is no cable in between.
Unfortunately, some of our customers cannot use any of our provided client systems, or just prefer to use a full SaaS. These clients were partially affected – that means that we were unable to optimize their onsite search and their search ran with a lower quality of service during that time. This hurts, and I sincerely apologize for the inconvenience.
Now, what happened?
All our systems run on standardized cloud infrastructure. Kubernetes with auto-scaling, shared-nothing, load-balanced and distributed between data centers. Certain services require mighty machines to do our machine-learning stuff. Some machines are needed 24/7, others are scheduled on demand as needed or configured. Some services serve billions of cheap requests that don’t require lots of server power. They can be reached through an API layer, commonly named Ingress. This is especially true for our tracking systems. Practically, they have little to do but send tiny pieces of data to an asynchronous messaging system. These services are heavily load balanced and distributed between machines. As they don’t produce a significant load, they are allowed to run everywhere. We carefully monitor these services to ensure that enough ingress pods are available to process these requests.
Kubernetes allows an affinity between services and machine types to be defined, ensuring software runs with suitable resources, especially CPU and memory. Conversely, anti-affinity makes sure that certain services don’t run on machines too small for the task (bad performance) or disproportionately large machines (high costs). These affinity settings allow the most efficient use of the underlying hardware. A goal that we consider crucial, as data centers worldwide are responsible for a significant portion of global emissions. But these settings can grow complex, as in “this Pod should (or, in the case of anti-affinity, should not) run in an X if that X is already running one or more Pods that meet rule Y” (https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/#affinity-and-anti-affinity).
In our case, it happened that due to some missing constraint, a huge number of the ingress pods were scheduled on only a very small number of nodes. From a Kubernetes perspective, this fit perfectly well with memory and CPU limits and thus was not detected by any monitoring system. But the sheer number of simultaneous network connections at 11:30 UTC overwhelmed the network interfaces, as they can only handle 2^16 connections in parallel.
All of this is not a real problem even if the network interface is running at 99.9% of its maximum capacity. However, a tiny bit more, and the tipping point is crossed, everything breaks down, and you need quite some time and effort to get everything up and running again. Of course, we have fixed not only our configuration, but also extended our monitoring systems to alert us early if heavily autoscaled, cheap services such as ingress are not distributed widely enough across the cloud infrastructure.
See any similarities? Tipping points are an issue. Your environment can look totally green, although being close to its limit. It is challenging to tell when the tipping points are reached. If we have signals which indicate that such a tipping point could be reached, we need to take action early enough. Once a tipping point is crossed, there might be no way back. Cloud infrastructure can easily be recovered by experienced personnel. But we most likely cannot recover our planet.
Understanding Current Embedding Models And Retrieval Stacks
After fully decoupling our customers’ search platforms from the NeuralInfusion™ retrieval stack (see PART-2 of this blog series) and identifying the queries we aim to enhance, we were still confronted with the challenges outlined in PART-1 of this blog series: tokenization and vocabulary limitations, domain adaptation, multilingual understanding, and optimizing hybrid result combinations.
Domain Adaptation: Most models require specialized training to align with our specific use case and domain. While numerous embedding models exist, only a few are designed or fine-tuned for retail and ecommerce applications.
Multilingual Support: With 92% of our customers operating also in non-English-speaking regions, it is essential that models provide effective multilingual capabilities.
Tokenization: Tokenization and corpus size remain critical constraints for modern embedding models. Many of the models we analyzed impose corpus size limitations for efficiency, defaulting to substring tokenization when an exact token or string is missing. Our testing revealed that while vector retrieval occasionally yields good results, it frequently misinterprets query intent.
Most existing solutions … neglect core issues such as retrieval quality.
To tackle these challenges, our first step was to identify a robust vector retrieval stack for evaluation purposes. We evaluated various options, hybrid search systems, and API vendors to optimize document and document ID retrieval during the initial retrieval stage. However, we were surprised to find that most existing solutions focused primarily on embedding, indexing, and retrieval—while neglecting core issues such as retrieval quality.
Selecting A Retrieval Stack For NeuralInfusion
The only vendor showing substantial promise from the start was Marqo.ai with its open-source vector retrieval solution. Despite their focus on multi-modal embedding, indexing, and retrieval—utilizing Vespa.ai as their backend retrieval engine—Marqo.ai’s emphasis on multi-modal retrieval and their thoughtful approach to UX/UI challenges and fine-tuning solutions (Generalized Contrastive Learning) made them a strong candidate. Our internal benchmarks indicated that Vespa.ai excelled as an ideal backend retrieval engine, meeting our key criteria for performance and flexibility. Vespa offers extensive configurability, including custom data structures and choices between memory and disk storage, and supports multiphase ranking for optimizing search results. Convinced that Vespa.ai was the most promising backend retrieval engine and that Marqo.ai provided the ideal tooling around it, we decided to utilize Marqo.ai to power the vector-based retrieval component of our new NeuralInfusion™ capability. During production-data testing, we observed that while Marqo.ai’s multi-modal retrieval performs strongly, there are opportunities for further enhancement in three key areas: Domain Adaptation, Multi-Language Support, and Tokenization. Marqo.ai offers a paid service called Marqtune for domain adaptation aka fine-tuning, which helps address some of these challenges. However, it requires huge amounts of high-quality training data, GPU resources, and, in most cases, customer-specific fine-tuning. As a result, this approach is particularly well-suited for larger customers, but may present additional overhead for smaller-scale implementations.
A note about benchmarking
If you’re wondering why we haven’t included benchmarking data in this blog post, here are the key reasons:
When we conduct benchmarks, we do so with a specific use case in mind—not for generic evaluation. For example, in NeuralInfusion, our primary focus is on peak indexing performance and achieving optimal, consistent recall, since real-time retrieval isn’t required. Instead, all vector retrieval is performed in scheduled batches. As a result, the outcomes of our benchmarks may differ significantly from what you might observe in your use case.
For us, the retrieval stack is purely infrastructure—a fundamental tool that enables us to implement various use cases while balancing financial and human resource constraints. This means our technology choices are driven by practical requirements and constraints, rather than marketing-driven benchmark comparisons.
Understanding The Impact Of Embedding Models On Your Retrieval Quality
Now that we’ve selected a retrieval stack (the engine), it’s time to focus on the data being indexed and identify key areas for improving the use of embedding models (the fuel). We’ve already discussed the fundamental challenges of domain adaptation, multilingual support, and tokenization. These issues arise from the embedding model’s limitations in understanding and confidence—whether due to unknown tokens, insufficient statistical representation in the training corpus, or not enough context in the query itself. As a result, the model may struggle to properly position and differentiate words, phrases, and products within the embedding space. In the retrieval process, the search query is also embedded into the vector space, and these vector queries are matched against documents in the embedding space. Generally, the input query is processed by the same machine learning model that created the indexed embeddings, producing a vector within the same space. Since similar vectors cluster together—the foundation of dense retrieval—finding relevant results becomes a matter of identifying the vectors closest to the query vector and retrieving the associated documents.
Simple embedding model for color representations
The quality of the retrieved results predominantly depends on two factors (not accounting for the quality of the underlying training data-set):
The quality of document and query embeddings—which can be improved through fine-tuning.
The effectiveness of the chosen retrieval algorithm, whether Approximate Nearest Neighbors (ANN) for efficiency or K-Nearest Neighbors (KNN) for exact matching.
While this might seem obvious, we frequently see teams focusing exclusively on the technical aspects of retrieval algorithms—without giving enough attention to the quality of indexed data and embeddings, which are just as crucial for improving search quality. In such scenarios, the go-to-solution for most people is to throw in some fine-tuning. The primary objective of fine-tuning multi-modal embedding models is to improve the alignment and relevance between different data modalities (e.g., text and images) within a specific domain or task.
Strictly speaking
we are referring to the use of additional signals (user-feedback, synthetic training data) to manipulate the embeddings in a way that they form dense clusters with minimal semantic overlap. This ensures that embeddings better capture semantic relationships and produce more accurate and meaningful retrieval results.
Silhouette of a pre-trained vs. a fine-tuned multi-modal CLIP model
Selecting An Embedding Model For Neuralinfusion
Given the three major challenges outlined in the beginning, we strongly believe that multi-modal embeddings are the most efficient approach to addressing the fundamental obstacles in ecommerce retrieval. To evaluate embedding quality, we selected the following two models:
Marqo-Ecommerce-B (fine-tuned model by marqo.ai) Link
As previously discussed, dense retrieval is built on the principle that similar documents should cluster together in vector space. Since our primary goal is relevant retrieval, our first step is to assess how effectively the embedding model utilizes indexed documents—ensuring they are positioned in vector space in a way that accurately reflects and differentiates their semantic meaning.
IMPORTANT NOTE
Since we serve customers across multiple verticals, we won’t be covering highly specialized, domain-specific models in detail. However, it’s important to acknowledge that these models can significantly enhance retrieval performance.
The Effect Of Document Embedding Quality On Retrieval
For the following example, we embedded a corpus of 50,000 fashion products using both embedding models, assigned each product the taxonomy leaf category that best represents its product type, and visualized the results using t-SNE.
embedding silhouette with open_clip/ViT-L-14/laion2b_s32b_b82kembedding silhouette with Marqo-Ecommerce-B
Visualizations Annotation
t-SNE is a dimensionality reduction technique used to visualize high-dimensional data in a lower-dimensional space (typically 2D or 3D) and helps to analyze how well an embedding model clusters similar concepts in vector space
This type of embedding visualization is highly valuable, as it allows for the quick identification of areas with significant semantic overlap (e.g., coats vs. jackets or shirts vs. jackets and some shirts vs. polo shirts). As seen in the two figures, even a highly fine-tuned embedding model struggles to generate embeddings that form dense clusters with minimal semantic (taxonomic) overlap, although it significantly improved the situation.
In terms of retrieval performance, let’s compare the results of the two multi-modal embedding models with the one already measured in PART-1 of this blog series:
Query recall analysisPrecision@12 analysis, with an average improvement of 11 percent.
Even though others claim higher numbers, we saw limited impact of fine-tuning, leading up to an 11% improvement in the Precision@12 score. On the other hand, it definitely enhances the embedding model’s ability to form denser clusters with minimal semantic overlap. However, achieving these gains requires a substantial amount of high-quality training data and incurs significant GPU computational costs, making it crucial to carefully assess the trade-offs from a business perspective.
The Effect Of Query Embedding Quality On Retrieval
Now that we detailed the impact of the embedding model quality for the portion we control (the documents), let’s also confirm what this means for the query side of things. This is necessary because the search query is embedded into the same vector space. As this is the case, the effect of the improved embedding model quality allows the top-k closest documents to be returned. A very simple description of the search process would be to think of using the embedded query as a kind of entry point into the embedding space. Again, it’s beneficial to visualize the process to understand the implication of each component:
Finding the best possible entry point into the embedded document space during query embedding is crucial. Otherwise, retrieval may return only the top-k closest documents—which, despite their proximity in vector space, might be completely irrelevant to the query.
Marqo-Ecommerce-B embedding of the query “polo shirt”
Since queries and documents are embedded using the same model, the primary limitation isn’t the document embeddings but rather the information richness (context) of the query. Our analysis revealed that the most significant opportunity for improving relevant vector retrieval doesn’t lie solely in the embedding model itself but in query enrichment—enhancing the user query to better capture intent, allowing the embedding model to interpret it more effectively. As can be seen, over 85% of all valid queries have equal or less than 3 tokens.
cumulative share of information across our known queries
The hypothesis formed was: What if we could improve retrieval by 30-40% simply by enhancing the query embedding, without any fine-tuning? Leveraging our deep expertise in optimizing user search queries, we explored an innovative approach: mapping user queries into an intermediate intent space. This intent-mapping technique effectively addresses domain adaptation, multi-language support, and tokenization, while remaining fully compatible with fine-tuning strategies.
This innovative intent-mapping technique effectively addresses domain adaptation, multi-language support, and tokenization, while remaining fully compatible with fine-tuning strategies.
Intent Mapping
The core idea behind intent mapping is simple — instead of directly embedding the user query, we first map it into an intermediate intent space, thereby significantly enriching the query’s information. Then we send it to the retrieval system that retrieves the closest documents from the customer’s indexed document space. You can think of the query-intent model as a foundational tool that helps pinpoint a more precise entry point into the product embedding space during retrieval.
The main objective of intent mapping is to find a better entry point into the embedded document space and by doing so, maximize the amount of relevant documents during retrieval.
Please understand, we cannot disclose the full details of how we are building and enhancing the intent-space model at this time, as we are exploring the possibility of patenting the process or parts of it. However, we’re still eager to share the underlying concept together with some example use cases.
A quick breakdown
The beauty of this approach lies not only in decoupling the user query from the embedded query, but also in its ability to incorporate additional contextual information as needed. By doing so, we can address the respective retrieval or ranking challenges through specifically optimized strategies for each case.
Take, for example, one of the most common queries across our customer base: “trousers”. On its own, this single-word query offers little contextual information to refine retrieval—right? Not necessarily. With intent-space mapping and a multi-modal model, we can enrich the query dynamically. For instance, we can integrate recent user behavior, such as trending or highly engaged items from the past 1–2 weeks, simply by appending this data to the query. This allows for more context-aware retrieval, improving relevance without requiring any changes to the underlying embedding model.
Benchmarking Neuralinfusion’s Vector Retrieval
As always, if you come up with an entirely different approach compared to market trends, you are naturally curious how your approach performs against the current state and to which extent it varies. Therefore, we compared the performance against what is currently considered state-of-the-art, mentioned in PART-1 of this blog series, and also included a state-of-the-art multi-modal-model (Marqo-Ecommerce-B) specifically fine-tuned for ecommerce data.
Results:
Our standardized precision-versus-recall analysis confirmed that our “intent mapping” approach significantly outperforms all the evaluated state-of-the-art methods. Although recall is generally robust across existing approaches, combining Intent Mapping with a fine-tuned multi-modal model increased precision on average more than 25%. Notably, it even surpassed all other models when paired with the non–fine-tuned CLIP model—a result that we found particularly impressive. Keeping Twyman’s law in mind—that when something looks too good to be true, it often isn’t—we also conducted extensive manual evaluations with our customers. Once the two versions were compared side by side, the boost in confidence was unmistakable. To illustrate this improvement, we have selected several impressive examples for you to review. Keep in mind that these examples were performed without any additional re-ranking applied. This means there are no incorporated re-rankers, user-feedback or any other sort of business rules applied, however these could easily be inserted on top in a follow-up ranking stage.
Some hand-picked examples
Pure Marqo-Ecommerce-B
query: sensorarmatur
case 1: assortment offers no perfect match but very close alternatives
Intent Mapping + Marqo-Ecommerce-B
query: sensorarmatur
case 1: assortment offers no perfect match but very close alternatives
Pure Marqo-Ecommerce-B
query: wand styropor leiste
case 2: assortment offers more perfect matches
Intent Mapping + Marqo-Ecommerce-B
query: wand styropor leiste
case 2: assortment offers more perfect matches
Pure Marqo-Ecommerce-B
query: yatak odası dolapları
case 3: foreign language, tokens not included in the model vocabulary
Intent Mapping + Marqo-Ecommerce-B
query: yatak odası dolapları
case 3: foreign language, tokens not included in the model vocabulary
Pure Marqo-Ecommerce-B
query: bauplatten für feuchträume
case 4: a query that needs some serious semantic understanding
Intent Mapping + Marqo-Ecommerce-B
query: bauplatten für feuchträume
case 4: a query that needs some serious semantic understanding
Pure Marqo-Ecommerce-B
query: sensorarmatur
case 1: assortment offers no perfect match but very close alternatives
Intent Mapping + Marqo-Ecommerce-B
query: sensorarmatur
case 1: assortment offers no perfect match but very close alternatives
Pure Marqo-Ecommerce-B
query: wand styropor leiste
case 2: assortment offers more perfect matches
Intent Mapping + Marqo-Ecommerce-B
query: wand styropor leiste
case 2: assortment offers more perfect matches
Pure Marqo-Ecommerce-B
query: yatak odası dolapları
case 3: foreign language, tokens not included in the model vocabulary
Intent Mapping + Marqo-Ecommerce-B
query: yatak odası dolapları
case 3: foreign language, tokens not included in the model vocabulary
Pure Marqo-Ecommerce-B
query: bauplatten für feuchträume
case 4: a query that needs some serious semantic understanding
Intent Mapping + Marqo-Ecommerce-B
query: bauplatten für feuchträume
case 4: a query that needs some serious semantic understanding
Recap
As this is the 3rd and final part of this blog series about NeuralInfusion, it’s only appropriate to review our main objectives laid out when we began work on this capability:
To identify the most challenging problems of product retrieval in ecommerce and retail, which we established in PART-1.
To come up with an architecture to address these challenges, irrespective of the underlying search platform and technologies used. This architecture must be orders of magnitude cheaper compared to solutions considered to be state-of-the-art, while also simple to integrate and operate as described in PART-2.
To address the challenges of search relevance within the scope of dense retrieval. To this end, we introduced a new method to augment the user-query called “Intent Mapping”. It by far surpassed all expectations.
Why we think it matters
A picture is often worth more than 1000 words. And so, we would like to finish off this series with one:
A picture speaks a thousand words
The above illustration is a high-level blueprint of NeuralInfusion, depicted using a smart thin-client (smartQuery) in the same environment as your search engine which infuses pre-inferred docs into your search results (here as an example with elasticsearch as the underlying search engine)
Rather than at query-time combining myriad retrieval methods for all queries all the time, we instead run asynchronously and only for clustered intents OR predefined queries. This method applies to scenarios like, zero-result-queries, underperforming queries, or simply queries with few results, that show adequate room for improvement. Structuring our retrieval method in this way, we decouple the online embedding & inference from query runtime. This is made possible because the results are already precalculated and can be served by extremely efficient K/V lookups in our thin-client called smartQuery. This eliminates the need for slow, blocking, or expensive inference—and only needs to be applied to a single query within a search intent cluster (with practically no added latency < 2ms @p99 avg response times).
This setup allows you to leverage the latest model improvements without the need to deploy, manage and expose them publicly. At the same time, seamlessly integrating model benefits into your existing search engine preserving all business rules, including filtering, sorting, as well as re-ranking. We have already demonstrated that NeuralInfusion is fully supported through native APIs by (elasticsearch, opensearch, solr, typesense, bloomreach).
This means that you can significantly enhance the efficiency of your current retrieval system without needing to replace or build any sort of side-car solution. Secondly, it provides unparalleled flexibility by allowing the curated results to be adjusted whenever required. This is particularly true when certain models’ relevancy performance is subpar. In such cases, it enables the seamless inclusion of supplementary models, either by using the entire query set or only a portion of it — a typical use case in the instance of visual merchandising activities.
Closing words
Although there is still much to achieve in terms of relevant and efficient retrieval and product discovery in ecommerce, our team—and our customers’ teams—remain dedicated to advancing what’s possible in this space. We believe this blueprint is immensely valuable for search teams worldwide, helping them navigate resource constraints while maintaining ownership and continuously enhancing their retrieval stack.
Following a reading of the article “Wie KI Produktdaten zum Leben erweckt” (How AI brings product data to life) by Dominik Grollmann, from the German ecommerce magazine ONEtoONE (Q4 2024), a fundamental question arises: Why invest so much effort in machines trained on behavioral science to interpret human purchase behavior when all that’s needed is to correctly interpret keyword entries into the search box?
Featured prominently in the ONEtoONE article, Paraboost and Contentserv position themselves as AI-driven powerhouses in the realm of product information management (PIM), aiming to transform static product catalogs into dynamic, experiential content. Their approach is, in part, based on Maslow’s hierarchy of needs—mapping products to human motivations in an attempt to optimize engagement and conversion. The theory is intriguing: by understanding whether a consumer is prioritizing safety, esteem, or self-actualization, online retailers can tailor product recommendations accordingly. But how well does this psychological framework translate into the fast-moving, intent-driven world of ecommerce? While understanding human motivations can be valuable, ecommerce search, more specifically, operates on a different principle: technocrats call it “onsite search,” which essentially amounts to customers explicitly expressing their needs, through keywords, to a chatbot of sorts: the search box. The real challenge isn’t decoding deep motivations—it’s ensuring search engines correctly understand and match those keyword signals to the right products.
The Behavioral Science Dilemma in Ecommerce
Modern AI-supported PIM solutions assume that consumers follow a structured path through Maslow’s pyramid when shopping. Take, for example, the airbag helmet purchased by a safety-conscious cyclist or the stylish sunglasses chosen by a fashion-forward biker. In theory, these choices reflect fundamental human needs. But ecommerce is rarely so neatly categorized. A customer might buy a princess-themed bicycle not because they prioritize self-expression over safety, but simply because their child insisted on it. Another shopper might frequent a specific online store based on habit, brand affinity, or even a one-time recommendation—factors that have little to do with psychological needs and more with convenience or loyalty.
Moreover, data from mid-tier ecommerce stores is often too fragmented or inconsistent to support such sophisticated behavioral models. Customer behavior is complex, sometimes contradictory, and often driven by external variables—seasonality, trends, pricing fluctuations, and promotions—all of which introduce inconsistencies that challenge the accuracy of behavioral AI models. These external influences can create false correlations, leading AI to misinterpret why a product is being purchased or which factors are truly driving consumer decisions. And if an AI-driven PIM solution does trigger an immediate uptick in sales, is that truly the result of better product data, or simply the novelty effect of fresh content?
These questions are left unanswered by the authors.
The Real Missed Opportunity: Search
The ONEtoONE article makes broad claims about enhanced product experience management, yet it lacks a crucial perspective: time. The success of AI-driven PIM solutions cannot be measured solely by short-term engagement spikes; their true value lies in sustained improvements in product discoverability, conversion rates, and customer retention. Without accounting for how these effects evolve over time, it’s difficult to separate genuine progress from a fleeting novelty effect. How does this supposed improvement sustain itself beyond initial implementation? Does customer behavior truly shift long-term, or do we simply see a temporary spike before shoppers revert to seeking the highest quality at the best price?
Yet, despite these claims, an exact answer remains elusive. This raises an important question: how does an online retailer cater to customers who don’t fit neatly into behavioral models? Let’s shift the focus to a different scenario—one where the customer enters the online store as a blank slate. They don’t know the industry jargon. They’re not searching for trending terms. They don’t even know exactly what they need. Here, neither the AI-driven product enrichment of modern PIM-solutions nor their behavioral analysis can bridge the gap. The only interface capable of making sense of this unstructured intent is the search box.
This is where searchHub changes the equation:
Instead of overloading the product database with fleeting trends and subjective customer sentiment, searchHub refines and prioritizes keyword intent.
It enhances search performance without invasive modifications to existing PIM infrastructure.
Its low-maintenance approach ensures that ecommerce teams are not constantly chasing data updates.
If AI is to be leveraged effectively in ecommerce, it must be in ways that yield sustained, scalable benefits. searchHub’s keyword clustering approach does precisely that. Consider an online store that receives 699 different variations of the keyword “yoga mat.” Search engines treat these as separate queries, often leading to scattered, inconsistent results. searchHub offers search engines assistance. It understands that these variations share a common intent. By analyzing purchase behavior, it identifies the single most effective term—the keyword ambassador—which is then sent on to the search engine for further processing. In the meantime, the other 698 variations undergo continuous reassessment.
searchHub identifies the Keyword ambassador within a cluster.
The Symbiosis of AI-PIM and AI-Search
The true power of AI in ecommerce lies not in forcing product data into a psychological framework, but in seamlessly connecting customer intent with the right products. Intent-based AI prioritizes what customers explicitly express—through their search queries—rather than attempting to infer motivations from abstract psychological models. In the ‘yoga mat’ example above, the customer’s immediate need is clear, and a well-optimized search engine ensures they find the right product without requiring behavioral analysis to deduce their motivations. A modern PIM solution can certainly benefit from AI-driven enrichment, but it does best, when paired with an intelligent search solution.
searchHub feeds real-time keyword-intent data into AI-powered PIMs like those mentioned in the ONEtoONE article. This integration ensures that product descriptions evolve dynamically, not based on rigid psychological theories but on actual customer behavior. The result? A more responsive, adaptive ecommerce ecosystem that continuously aligns product discovery with the way real people search and shop.
So whether your goal is a streamlined, low-effort solution or a fully integrated AI-driven search and PIM ecosystem, the key to success in ecommerce is not about speculating on customer motivations—it’s about precisely understanding and responding to their purchase intent.
We look back with gratitude on an eventful and successful 2024.
Before we set our sights on an exciting 2025,
we’d love to share some of our highlights with you.
Highlights 2024
This year, we developed 21 new searchHub extensions, fulfilled 13 customer development requests, and welcomed 15 new clients. We’re proud of these achievements and grateful for the trust placed in us.
Industry Benchmark
Compare your search KPIs with those of other companies—now available in the performance charts, segmented for B2B and B2C.
Query-Testing
We automatically test different clusters continuously to optimize your search results. Say goodbye to rigid search patterns—always the best results for you.
AI-Redirects
Based on your customers’ search behavior, searchHub automatically generates suggestions for redirects. This ensures your customers land on the strongest landing pages faster—and saves you valuable time.
In addition to the ongoing development of searchHub, we’ve actively supported a project that is making a real difference.
A Project Close to Our Hearts: Well Construction in Zambia
A special project close to our hearts is our commitment to well building in Zambia. Scaling is in the DNA of searchHub. And that’s exactly what the construction of drinking water wells in 25 villages in the Mambwe district of eastern Zambia is all about. How is it “scalable”?
Children now have more time for school and education, as they no longer have to travel long distances to collect water.
Clean water leads to fewer illnesses caused by contaminated water. Dangers along the way to water sources, such as wildlife, are no longer a concern.
The local community is strengthened through the training of WASH committees and wildlife rangers.
Looking Ahead to 2025
Next year is going to be exciting! We’ll be developing new features, strengthening our platform, and looking forward to inspiring projects, events, and collaborations with our partners—all aimed at sustainable growth and your success.
Feature Outlook: NeuralInfusion™
Vector search is all the rage, but like traditional text search, it has its pitfalls. With searchHub, we’ll be introducing a “best of both worlds” hybrid search add-on that can enhance any search! Smart, AI-driven, and cost-efficient!
Of course, we will…
Remain search provider-agnostic
Continue to prioritize automation in search
Expand and strengthen platform partnerships, ensuring we remain your trusted partner for all things search in 2025.
Looking Ahead to 2025
A heartfelt thank you to our valued customers, partners, and collaborators—your support makes all of this possible! We wish you and your families a Merry Christmas and a successful start to the New Year! 🎅🎁
Stay healthy and successful—we look forward to shaping 2025 together with you!
Wir blicken mit Dankbarkeit auf ein ereignisreiches und erfolgreiches Jahr 2024 zurück. Wir möchten einige unserer Highlights mit dir teilen, bevor wir uns auf ein vielversprechendes 2025 freuen.
Highlights 2024
In diesem Jahr haben wir 21 neue searchHub Erweiterungen entwickelt, 13 Kundenwünsche umgesetzt und damit 15 neue Kunden gewonnen. Wir sind stolz auf diese Erfolge und das uns entgegengebrachte Vertrauen.
Industry Benchmark
Vergleiche Deine Such-KPIs mit denen von anderen Unternehmen – jetzt in den Performance-Charts, segmentiert für B2B und B2C.
Query-Testing
Ganz automatisch testen wir permanent verschiedene Cluster, um Deine Suchergebnisse kontinuierlich zu optimieren. Nie wieder starre Suchmuster – immer die besten Ergebnisse für Dich.
AI-Redirects
Basierend auf dem Suchverhalten Deiner KundInnen generiert searchHub automatisch Vorschläge für Weiterleitungen. So landen Deine KundInnen schneller auf den stärksten Landing-Pages – und Du sparst wertvolle Zeit.
Neben der Weiterentwicklung von searchHub haben wir gezielt ein Projekt unterstützt, das echte Veränderung bewirkt.
Ein Projekt von Herzen: Brunnenbau in Sambia
Ein besonderes Herzensprojekt ist unser Engagement für den Brunnenbau in Sambia. Skalierung ist die DNA von searchHub. Und genau so ein skalierendes Projekt ist der Bau von Trinkwasserbrunnen in 25 Dörfern des Mambwe-Distrikts im Osten Sambias. Wie „skaliert“ das?
Kinder haben jetzt mehr Zeit für Schule und Bildung, da sie nicht mehr weite Wege zum Wasserholen zurücklegen müssen.
Sauberes Wasser sorgt für weniger Krankheiten, die durch verunreinigtes Wasser verursacht werden. Gefahren auf dem Weg zu Wasserstellen, wie z.B. Wildtiere, sind vorbei.
Die lokale Gemeinschaft wird gestärkt durch Ausbildung von WASH-Komitees und Wildhütern.
Ausblick 2025
Das nächste Jahr wird spannend! Wir entwickeln neue Features, stärken unsere Plattform und freuen uns auf inspirierende Projekte, Events und die Zusammenarbeit mit unseren Partnern – alles für nachhaltiges Wachstum und den Erfolg unserer Kunden.
Feature-Ausblick: NeuralInfusion™
Vektorsuche ist in aller Munde. Aber Vektorsuche hat, wie klassische Textsuche auch, ein paar Fallstricke. Mit searchHub werden wir ein „best of both worlds“ auf den Markt bringen, das als Hybrid-Search Add-on jede Suche erweitern kann! Intelligent, KI-basiert und kosteneffizient!
Wir werden natürlich …
Suchanbieter-Agnostisch bleiben
Automatisierung rund um die Suche weiter in den Vordergrund stellen.
Plattform-Partnerschaften weiter ausbauen und stärken, um auch 2025 euer kompetenter Ansprechpartner zu allen Suchthemen zu sein.
Danke und frohe Festtage!
Ein herzliches Dankeschön an unsere geschätzten Kunden, Partner und Wegbegleiter – eure Unterstützung macht all das möglich! Wir wünschen euch und euren Familien ein frohes Weihnachtsfest und einen erfolgreichen Start ins neue Jahr! 🎅🎁
Bleib gesund und erfolgreich – wir freuen uns darauf, gemeinsam mit Dir 2025 zu gestalten!
Herzliche Grüße Dein Team von searchHub
Guten Rutsch!
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.