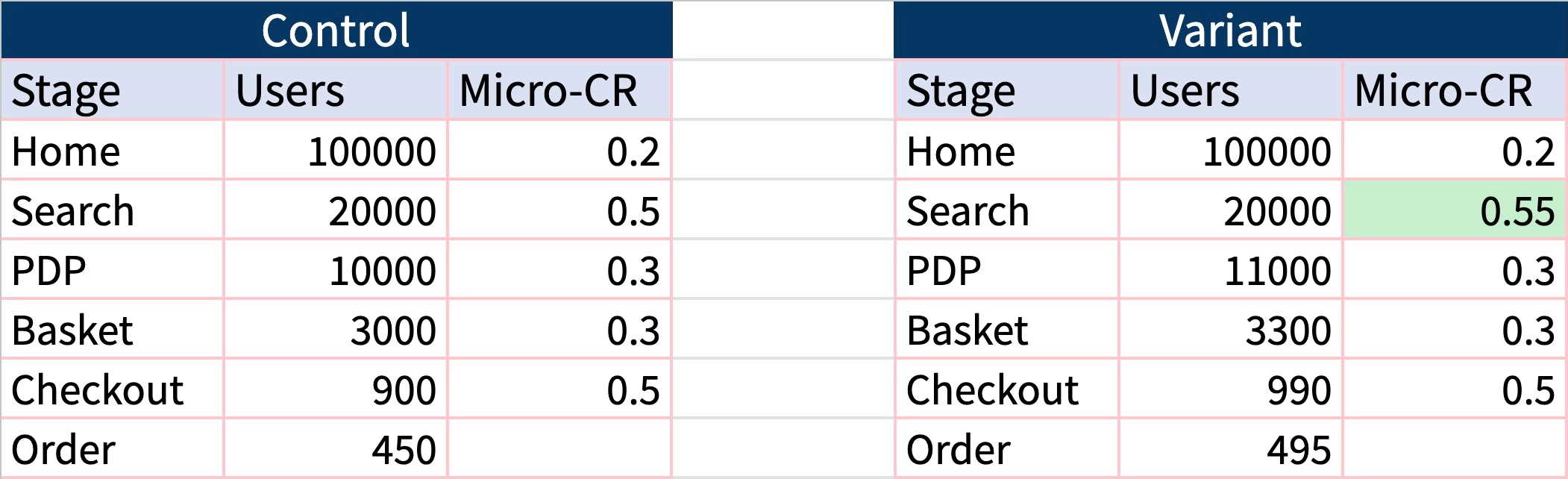
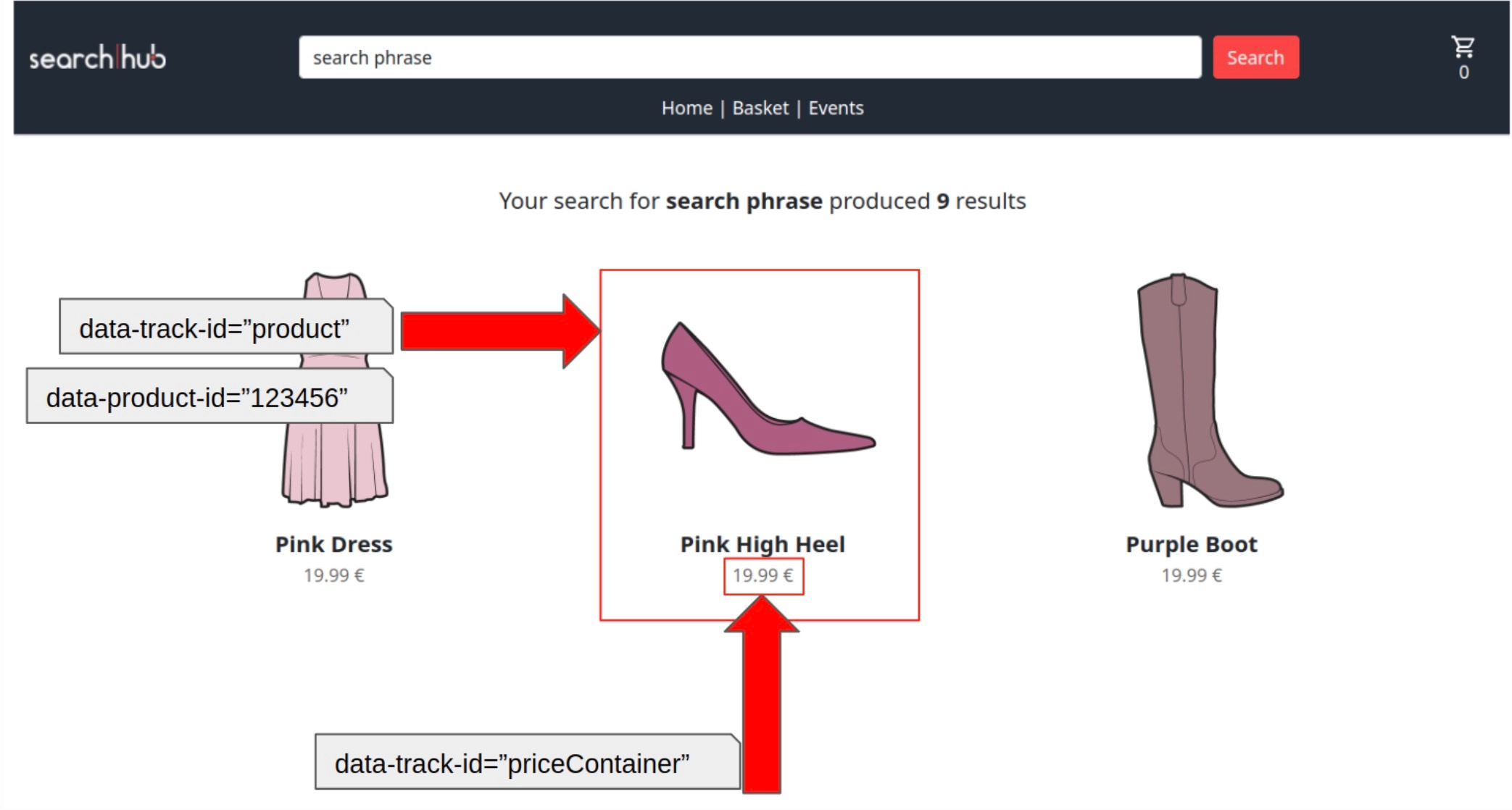
Sophie has been an online retail merchandiser for two decades, navigating the complex digital landscape where every click generates data. Her computer screen is her canvas, and product connections are her analytical craft.
When a customer lands on her e-commerce platform searching for a “summer weekend outfit,” Sophie observes the intricate patterns of interaction. A lightweight linen shirt isn’t just a digital SKU—it’s a data point in a complex computational network, waiting to be mathematically processed.
Modern vector search operates as a precise computational mechanism. It creates dense mathematical representations of products that reveal probabilistic connections all throughout Sophie’s ecommerce shop.
The Mathematics of Digital Interaction
Imagine each product as a point in a massive, multi-dimensional computational space. A pair of sandals isn’t defined by a simple tag like “beach wear,” but by a complex vector—a mathematical coordinate that captures its measurable characteristics. Its color, material, comfort, style versatility—all encoded into a single, dense numerical representation that transcends traditional categorization.
When a customer searches, the system calculates. It finds the nearest mathematical neighbors, revealing products with statistically similar characteristics beyond surface-level descriptions.
Beyond Traditional Matching
Traditional online search is rigid. Search for “blue shirt,” and you’ll get exactly that. Vector search is different. It infers potential product relationships by mapping complex multi-dimensional spaces of customer interactions and product attributes.
So let’s be clear: vector search doesn’t understand what customers want—it infers based upon mathematical proximity. Then it memorizes how users interact with those inferences and changes where necessary. This mathematical feat allows it to calculate the proximity between products with extraordinary precision, transforming complex digital product landscapes into navigable mathematical terrain.
Business Dynamics in the Digital Realm
Despite its computational precision, vector search faces significant challenges in real-world business applications. Most vector search systems struggle to incorporate critical business rules, leaving a substantial gap between mathematical potential and practical implementation.
Traditional vector search operates as a closed system, generating results based on mathematical proximity. But ecommerce businesses need more. They require the ability to inject specific products, prioritize strategic inventory, and apply complex ranking rules that go beyond pure adherence to a formulaic model.
This limitation creates a critical bottleneck in e-commerce performance. Mathematically perfect product recommendations mean little if they don’t align with immediate business objectives.
The Power of Computational Inference
With NeuralInfusion, searchHub represents a breakthrough in addressing these fundamental vector search limitations. It doesn’t just generate vector-based recommendations—it provides a sophisticated layer of business logic that can dynamically rerank and modify search results.
Imagine a vector search system that can:
Inject specific products based on strategic business goals
Apply complex ranking rules that override pure vector similarity
Dynamically adjust search results based on inventory, margins, and business priorities
NeuralInfusion transforms vector search from a purely mathematical exercise into a powerful, business-driven tool. It bridges the gap between computational inference and strategic business requirements, creating a new paradigm of intelligent product discovery.
Data-Driven Discoveries
Sophie knows something fundamental: great digital retail is about revealing probabilistic product connections through precise statistical analysis.
Vector search accomplishes this through mathematical inference. It transforms complex product data into a language of numerical proximity, where computational nearness suggests potential customer interactions. Paired with searchHub, Sophie’s customers receive curated results that perform in-line with her business goals.
In a world of infinite online choices, we need intelligent computational product discovery that respects the complexity of digital marketplaces.
AI-Redirects have come a long way, helping eCommerce sites simplify keyword management, make customer paths more intuitive, and even increase conversions.
Without query-level-tracking, there’s no way for you to attribute your search revenue to specific keywords. You’re flying blind whenever it comes to measuring your landing-page value against natural search results. If, however, you’ve taken the time to ensure a smart deep-level query tracking is implemented, you can clearly:
Analyze customer intent. This is different than search conversions, which are misleading at best.
Consolidate intent traffic into clusters.
At this point, you will have built a perfect foundation so that your insights can begin offering more than the sum of its parts — like creating fresh revenue streams through Retail Media Ads.
This post explores how understanding keyword performance, an asset from AI-Redirects, can fuel targeted advertising opportunities, bringing measurable value to your brand and new income potential from your eCommerce traffic.
In previous discussions (like Beyond Redirects), we explored how AI streamlines keyword mapping and search experience. Now, let’s dive into how these insights create advantages for Retail Media Ads.
1. Granular Keyword Insights = Targeted Ad Opportunities
AI-Redirects, helps you understand whether a landing page, or natural search result page leads more customers to specific, sellable products. This insight allows you to create hyper-targeted ad spaces for brands—spaces backed by data showing high-performing keywords, such as “lightweight running shoes” or “safety shoes.”
Brands value precision and relevance, and with this performance data, you can offer 🤵 premium ad space that aligns their ads with the right customers. It’s the kind of advertising environment brands pay a premium for.
2. Increase ROI with Precise Ad Placements
Working like this, you have access to popular high-revenue search terms. That’s a pretty big differentiator, considering most retailers rely on broad, less tailored ad placements. By targeting ads that resonate directly with popular search terms, you’re not playing pin-the-tail-on-the-donkey blindfolded, but able to leverage your path to ROI by placing highly relevant ads for a complete cluster of search terms that are already driving valuable traffic.
For instance, you might discover over 300 different keyword variations for the keyword “leggings” in your AI-Redirects report. All you have to do is enter a redirect for that one “leggings” cluster, and shwup-di-woop, all 300 keyword variations benefit from a well-crafted landing-page, while simultaneously becoming prime real estate for brands competing for prominence. That’s your cue to collaborate with specific brands and display relevant ads. This relevance increases conversion rates, benefiting your ad partners and your bottom line.
3. Offer Brands Unmatched Value
Real-time keyword performance data makes your eCommerce site a valuable advertising partner. Brands know you can show clear, data-backed pathways for which keywords drive product sales and how these insights translate into highly targeted retail ad campaigns. This level of data granularity is rare, positioning you as a unique ad partner and setting your business apart from competitors who lack keyword-level insight.
Putting It All Together: Transforming AI-Redirects into New Revenue
AI-Redirects do more than enhance customer journeys. They unlock opportunities for monetizing keyword clusters, allow you to provide targeted ad opportunities for your brand partners, and help turn performance data into high-ROI retail media campaigns. Here’s how to leverage these insights:
Monetize top-performing keyword clusters through strategic ad placements
Build ad space that appeals to brands based on proven search demand
Create retail ad campaigns that align with specific customer needs
Wrapping Up Our Series on AI-Redirects
Throughout this series, we’ve covered how AI-Redirects streamline keyword management, improve customer journeys, and unlock ad potential. This final post emphasizes that AI-Redirects not only improves the technical side of search—it’s a revenue generator waiting to be tapped.
Whether you’re interested in optimizing site search or looking for new ad revenue, AI-Redirects offers tools to visualize keyword performance, maximize ad placements, and enhance your revenue streams. Thanks for joining us on this journey!
Redirects are a cornerstone of eCommerce search management, yet handling them well often feels like a puzzle with too many pieces. Ideally, you have to answer questions like: Are your redirects performing better than organic search results? Are customers finding what they need, or are they getting lost due to overlooked keywords or confusing paths?
In this post, we’ll explore how searchHub’s AI-driven redirects offer a smarter way to manage keyword complexity and provide actionable insights into redirect effectiveness. These tools not only simplify redirect setup but also offer you data-driven clarity on what works and what doesn’t—a game-changer for customer satisfaction and conversion.
The ongoing challenge of long-tail keywords
If you’ve tackled redirects before, you’ve probably wrestled with long-tail keywords. Each keyword variation represents a customer with specific intent, but mapping these terms effectively can be exhausting. Traditionally, this involves:
Manually building keyword maps
Tracking and updating redirects with every shift in inventory
Deploying static SEO terms or relying on manual keyword entries
As we discussed in our earlier post on using AI for site search optimization, traditional keyword approaches often fail to capture the breadth of customer language. Instead, AI can group related keywords based on intent, clustering searches that lead to the same product, regardless of phrasing. The system flags unknowns for review, while most terms are automatically mapped to the right results—no manual intervention needed.
Redirects should do more than just bring users to a landing page; they should guide them to the right content based on intent. Unfortunately, common tracking methods, like monitoring general hit counts, don’t provide the specificity needed to assess which keywords are driving customers to convert.
This is wherekeyword-level insights come in. By tying redirects to specific keywords, you can see what brings customers in and whether they convert. You’ll get insights like:
Which keyword variations lead to sales
Where specific redirects outperform organic search results
How redirect improvements can close gaps
These insights go far beyond what traditional site search provides, giving you concrete data on what’s working and where there’s room to refine, ultimately helping you optimize the search experience.
Real-World Impact: How AI Redirects prevent customer frustration and boost insights
Imagine you manage a German eCommerce store that sells workwear. Your landing pages are optimized for the term “Sicherheitsstiefel” (safety boots in German). But many customers, especially non-native speakers, search for “safety boots” instead. Without AI to recognize and redirect them to the correct page, these customers might encounter a frustrating “no results found” page or land somewhere irrelevant.
AI-Redirects from searchHub eliminate this issue by grouping variations of “safety boots” and linking them to your optimized page. As we explored in the previous post, AI-driven clustering ensures that customer intent aligns with your content, reducing frustration and increasing conversions as customers find what they’re looking for right away.
Gaining deeper insights with granular keyword analysis
Beyond simply redirecting traffic, AI-Redirects also give you the ability to analyze keyword performance with a new level of granularity. This enables you to:
Pinpoint which keyword clusters bring high-traffic but low-conversion
Identify keyword gaps where searches don’t convert
Make informed adjustments to optimize pages
These insights allow you to refine your search strategy based on real data, aligning better with actual customer behavior and minimizing missed opportunities. As a result, you’ll improve both user experience and revenue.
Wrapping Up: Building on AI’s role in ecommerce site search
Summing up, effective keyword redirect management is a cornerstone of improving customer experiences and boosting search relevancy. With searchHub’s AI-Redirects, you gain advanced tools for:
managing keyword variations, also known as the long-tail
analyzing performance
and ensuring customers reach the right products with minimal friction
As we’ve seen, aligning redirects with customer intent and measuring the performance of these AI-driven adjustments unlocks more profound insights and revenue opportunities.
Beyond the obvious enhancement to search functionality, these granular keyword insights can open doors to new revenue streams. In our upcoming post, we’ll explore how to harness long-tail keyword data for Retail Media Ads—transforming keyword traffic into targeted, high-ROI ad opportunities that benefit both you and your brand partners.
Stay tuned for the next steps in creating a smarter, data-driven search experience.
Building on the insights and challenges discussed in PART-1 regarding effective and efficient vector retrieval for eCommerce, we developed an entirely new solution that introduces a groundbreaking new capability called NeuralInfusion™. Since the core principles and architectural choices behind this solution are applicable to any search system, we decided to share more details here in PART 2. In short NeuralInfusion™ is centered around three key concepts that set it apart from anything we’ve seen before in how it addresses the identified areas of improvement:
In this second part, we will shed some light on areas 1 and 2, while area 3 will be addressed in the third post of the blog series.
1. Identifying queries with optimization potential
We already learned in PART-1 that recall in modern search stacks is primarily driven by two methods: keyword-search and vector-search. Each method has its strengths and weaknesses when retrieving documents: keyword-search excels at keyword matching between query and document, while vector-search shines at more broadly inferring the query context.
Recognizing that hybrid-search-approaches primarily boost recall and precision in specific contexts, we focused on identifying these opportunities.
Recall: To enhance recall, we looked for both clear and subtle indicators of optimization potential. Clear signs include zero-result queries, queries with few results, low engagement, or very low findability. Additionally, we identified a less obvious area: queries where product data errors or inconsistencies hinder keyword-based retrieval systems from returning all relevant items. We further leveraged the concept of query entropy to jointly optimize the recall-set-generation across the different retrieval methods.
Precision: For improving precision, we analyze user data and relevance judgments to find queries with low engagement, poor findability, extensive search bounds, and high exit rates. Moreover, the diversity and appeal of search results are crucial, particularly for branded and generic but also very specific queries. Specific markers or indicators can be used to test and refine these aspects.
Fortunately, our searchHub searchInsights feature already identifies promising queries for improvement, while the Query Experimentation (Query Testing) tool allows us to test various retrieval strategies to optimize their combined performance. This ongoing experimentation helps us determine the most effective approach for each query type over time.
Once we identified queries where we expect some significant uplift potential by increasing recall and/or precision, we had to come up with a strategy to tune / balance it. As a first step towards a more optimal retrieval strategy, we decided to build a model that would allow us to adaptively tune the recall set size from each retrieval mechanism based on the request context. We refer to this as the “Adaptive Precision Reduction Model” or APRM. Its primary goal is to determine when to increase recall and when to hold back. If increasing recall would significantly compromise precision, the model either adjusts or avoids the recall boost altogether. This is especially helpful in zero-result scenarios where a recall expansion might lead to completely irrelevant results.
We are still convinced that avoiding zero-results in all cases is not the best strategy as it hides critical information about the observed gaps in product assortment, user needs vs. the product assortment on offer. Therefore, precise adjustment and tuning of precision vs. recall is essential but very difficult to achieve with a standard vector search that is based on approximate nearest neighbors algorithms. Search managers, gain total control over precision vs. recall with the Adaptive Precision Reduction Model approach. To retain search platform independence, we decided to decouple the new advanced retrieval stack from the underlying search platform.
2. Decoupling advanced retrieval from the search platform
Search platform independence is central to searchHub’s philosophy. Our customers use a wide variety of search solutions, including vendors like Algolia, FactFinder, Bloomreach, Constructor.io, SolR, Elasticsearch, and OpenSearch. Some rely on search platforms integrated into their commerce platforms, while others build and fine-tune their homegrown search engines using open-source software or custom implementations.
We design our enhancements to be platform-agnostic because we believe our customers should retain control over their core business logic. This encompasses critical components such as stock control, pricing, merchandising strategies — like retailMedia Ads, and personalization. Retaining control over these elements allows retailers to maintain flexibility and innovation, adapting swiftly to market changes, customer preferences, and evolving business goals. And it enables retailers to create unique experiences aligned with their brand and operational strategies, without being limited by the constraints of a particular platform. Recognizing that many of our customers have invested considerable time and resources in customizing their search platforms, we aimed to offer NeuralInfusion™ in a platform-agnostic manner—without requiring them to re-platform. The challenge was finding an efficient way to achieve this.
I’ll admit, we were well into the development of many parts of the system before we had a clear solution for decoupling. It’s necessary to point out how deeply grateful I am, to my development team and our customers. Over the better part of a year, they remained patient as we worked through this challenge. In the end, we developed a solution that is IMHO both simple and elegant. Though, admittedly, it now seems straightforward in hindsight.
The breakthrough came when we realized that direct integration of different technologies was unnecessary. Instead, we focused on integrating the results—
whether documents or products. Essentially, every search result listing page (SERP) is just a set of products or documents retrieved from a system in response to a given query, which can then be refined through filters, rankings, and additional layers of personalization.
This led us to find a way to add missing or more relevant documents to the search process and, by extension, to the search results. In this way, we would maintain platform independence while ensuring our customers benefit from cutting-edge neural retrieval capabilities, without the disruption of replatforming.
The high-level blueprint architecture:
Instead of requiring our customers to implement and manage additional systems like a vector retrieval system, we optimized and simplified the retrieval process by dividing it into distinct phases and decoupling them. Rather than applying multiple retrieval methods to every query in real-time, we perform hybrid retrieval asynchronously only for specific cases, such as clustered intents or predefined queries. This is especially true for queries that revealed clear opportunities for improvement, as mentioned above.
By separating the embedding model inference from query execution, we can precompute results and retrieve them through very efficient key-value lookups. At query time, we use the query intent as the key, and link it to a set of documents or product IDs as values, which are then incorporated into the search engine query.
NeuralInfusion architectural diagram.
Fortunately, 9 out of 10 search platforms support combining language queries with structured document or record ID lookups via their query APIs. This enables several interesting specialized optimization use cases like adding results, pinning results and removing results from the initial search results.
Here is a simple integration example for the elasticsearch search platform:
This approach effectively tackles multiple challenges at once:
Latency and Efficiency: By decoupling the complex retrieval phases, we enhance speed and responsiveness. This shift transforms expensive real-time look-ups into cost-efficient batch lookups that primarily utilize CPU resources without significantly increasing response times.
Business Feature Support: We maintain essential business functionalities that retailers depend on, such as filtering or hiding products, implementing searchandising campaigns, applying KPI-based ranking strategies, and integrating third-party personalization capabilities.
Testable Outcomes: The system’s performance can be continuously measured and optimized on both a global scale and at the query/intent level.
Transparency and Control: Customers retain full visibility and control over the process and returned results, ensuring they can oversee and manage outcomes effectively.
Future-Proof Architecture: This decoupling strategy allows us to maximize potential retrieval strategies. We can integrate or combine any current or future models or architectures into our execution pipelines without requiring our customers to adjust their APIs or hurting their response times.
For new or previously unseen queries, the system requires one initial attempt before reaching its full effectiveness. However, this limitation affects only a small portion of queries, as our system already successfully maps over 85% of queries to known search intents. We expect to capture more than 90% of the potential value immediately. We will evaluate the economic impact of this minor limitation in future analyses.
Summary
In this post, we outlined the careful design behind the Infusion component of our NeuralInfusion™ capability. By reframing what was once seen as a capability issue into a straightforward integration process, we’ve created a solution that requires minimal additional investment while preserving high agility for future needs. With this architecture, setup, and integration, our customers can realize 90-95% of the identified optimization potential—all with complete transparency, no added latency, and no increase in system complexity.
In the 3rd and final part of this series, we’ll focus on the “Neural” part of our NeuralInfusion™ capability and how we found unique ways to overcome most challenges related to tokenization and domain adaptation.
Navigating site search can be challenging. Many companies struggle with guiding customers efficiently from a search query to relevant products or information. This post explores common challenges in search redirects, explains why typical solutions often fall short, and introduces a dynamic, AI-driven approach to manage redirects effectively. By the end, you’ll have a clearer understanding of modern search optimization techniques and a hint of what’s next in the evolving field of search engineering.
The Challenge of Onsite Search and Redirects
How do you accurately redirect customers to the right product or result page without creating a tangled mess of rules?
Site search engineers often face the complex task of directing customers from their initial search to relevant results in an efficient, user-friendly manner. Imagine a well-organized library where visitors quickly find what they need without knowing where every book is. Similarly, an optimized search system can guide users directly to the relevant “shelves” without manual interventions—minimizing both time and frustration.
However, traditional built-in systems for managing search redirects are limited. They often leave customers with irrelevant results and businesses with missed opportunities to optimize sales. So, how can you know if a search result aligns with customer intent? Or if your manually-set redirects perform better than the default search results?
This is where searchHub can help. Unlike search engines, searchHub enhances your existing search capabilities, aligning users more accurately with the products or pages they’re looking for. Let’s dive deeper into how different redirect methods compare and why some fail to deliver the results you might expect.
Common Redirect Approaches: Their Limits and Drawbacks
To address the challenges of search redirects, teams often rely on three common strategies:
1. Pulling Data from CMS with Keyword Pairing
Many start by pairing top product data from the CMS with obvious keywords. This may seem straightforward, but with fluctuating stock and product attributes, it quickly becomes unmanageable. Constant updates turn into a full-time task, often becoming obsolete before they’re completed.
2. Relying on SEO Keyword Lists
Leveraging SEO’s keyword lists might seem logical; however, static SEO keywords don’t adapt quickly to changes in product offerings. This leads to mismatches in search results, such as a search for “pink skateboarding shoes” showing no results, even though there are similar products in stock. SEO-driven lists rarely reflect the nuances of inventory and customer intent, creating a frustrating experience.
3. Using Regular Expressions (RegEx)
Some try to handle search term variations with regular expressions. While useful for some scenarios, RegEx often creates an overly complex and error-prone system when applied to unpredictable customer queries. For instance, broad expressions like “Under*” to capture brand-related queries may mislead users searching for unrelated terms.
These approaches are often inefficient and lack the adaptability required for a dynamic eCommerce environment. Without data-driven insights, it’s nearly impossible to gauge whether redirects improve user experience and conversion rates.
A Smarter Solution: AI-Driven Redirect Management
To overcome these limitations, searchHub’s AI-Redirects takes a different approach. By automating keyword mapping based on user intent, AI-Redirects adapts dynamically to the variety in search terms without requiring extensive manual adjustments. For instance, whether a customer searches for “Nike running shoes” or “lightweight shoes from Nike,” AI-Redirects can guide them to the same optimized landing page, reducing error and maintaining consistency in customer experience.
This shift to AI-based redirects provides several key benefits:
Efficiency: Streamlines redirect management by consolidating variations without endless manual input.
Consistency: Enhances customer experience by delivering relevant results, regardless of wording.
Insightful Tracking: Provides data on whether AI-driven redirects outperform default search results.
Why This Matters
Using AI-driven redirects not only saves time but also enhances the customer journey. A frictionless search experience leads to higher conversion rates, and fewer abandoned searches—contributing to improved customer satisfaction and business outcomes.
Recap
We discussed:
The challenges in creating effective site-search redirects.
The limitations of manual methods like CMS data pulling, SEO keywords, and RegEx.
The advantages of AI-Redirects in automating and enhancing the search experience.
What’s Next?
In this post, we explored the limitations of traditional redirect methods and introduced an AI-driven alternative for managing search. In a follow-up, we’ll delve into specific metrics to track the impact of redirect optimization, helping you evaluate the success of these AI-powered changes.
Stay tuned for our next post, where we’ll dive into performance metrics to optimize and refine your search strategies even further.
In the past 2–3 years, vector search has gained significant attention in ecommerce, primarily because it claims to offer a solution to a major challenge in keyword-based search known as the language gap or, in more technical terms, proximity search. The language gap refers to the disconnect between the words that a user types in to formulate the search query and the terms used in product titles and descriptions, which often leads to no or poor search results. At the same time, vector retrieval can infer semantic similarities between queries and documents, making it an effective tool for use as a re-ranking layer in the later stages of search to enhance the relevance of the results.
After stripping away the inflated marketing claims from vector search vendors and so-called domain experts, which our customers and users often echo, we identified a mere two areas of genuine optimization:
Improving recall and
Enhancing precision, primarily through re-ranking
While this may seem obvious, defining these two areas broadly allows us to challenge current solutions with alternative approaches or technologies later on. We anticipate this will incite further discussion within the community, which we welcome. Even still, these are the only two aspects to be both technically and economically verifiable. In terms of our customers’ business language, these core areas translate to:
Finding more (still relevant) results for a given set of queries (improving recall)
Ranking more relevant items higher in the results list (enhancing precision)
However, the feedback we received from our customers, who tried to productize vector retrieval, essentially boils down to one striking problem: vector retrieval always returns the k closest vectors to an encoded query vector. This is the case, even if those vectors are completely irrelevant.
So the open task is clear: Identify or, better yet, mitigate these situations to significantly increase trust in vector retrieval and enable more effective use of the strengths of both vector and keyword retrieval methods.
Hybrid search: the silver bullet?
Hybrid search — combining Vector and Keyword Search
It is crucial to acknowledge a recent consensus within the search community: vector search is not a one-size-fits-all solution. While it performs exceptionally well in some query types and retrieval scenarios, it can also fail dramatically in others. This has led to the emergence of hybrid search approaches that combine the strengths of both vector and keyword-based retrieval methods. Although this approach is appealing, our real-world observations highlight a key issue:
Many hybrid methods merely average the results of both techniques, undermining the goal of leveraging the best of both. Consequently, the overall value often falls short of the combined potential of the two strategies.
But that’s not at all, the least, questionable issue in current hybrid approaches.
Low maturity level of hybrid search approaches
For an Ecommerce shop, there are essentially two possible paths to choose from:
Switch to a new “sophisticated” vector search vendor that has bolt on rudimentary keyword search support
Stick with an established keyword-based vendor or solution that has recently bolted on vector search capabilities.
In either case, there’s a noticeable gap in quality and maturity between the two retrieval methods and solutions, especially when applied to the retail and ecommerce domain.
1. Lack of essential business features
While working closely with our customers, we’ve noticed that many hybrid search approaches often lack critical day-to-day business features. Essential functionalities like exclude-lists, results curation, and multi-objective optimization are frequently missing, despite being vital for retailers who prioritize not just relevance or engagement, but also margins and customer lifetime value (CLTV).
For example, our customers regularly receive trademark enforcement inquiries, sometimes multiple times a week. Brand or manufacturer lawyers may prohibit retailers from displaying results for queries containing trademarked terms. A case in point is the trademarked phrase “Tour de France”; during the event, many users searched for cycling-related products, but most retailers were forbidden from showing results for these queries. Additionally, established brands typically restrict the display of competing products close to their own, and non-compliance can lead to legal repercussions.
Retailers also need the ability to manage or curate search results. For broad queries, there’s often a need to guide customers through the results to avoid overwhelming them with too many options. In branded searches, retailers can generate additional revenue through promotional placements and Retail Media Ads.
Search result pages are key revenue and margin drivers for retailers. Effectively managing this multi-objective optimization challenge—which includes stock clearance, promoting bestsellers, highlighting high-margin items, and featuring mannequin products—is crucial for their success and is commonly known as Searchandising. Unfortunately, these essential business features are frequently missing in new hybrid search solutions or are added as an afterthought, leading to less than optimal outcomes.
2. Added dependencies and complexity
Hybrid search scenarios introduce many additional dependencies to the retrieval system. In addition to indexing and searching tokens or words, there’s also a need to embed and retrieve vectors, which can significantly slow down the indexing process—often extending it from minutes to hours. This added complexity creates challenges, particularly in near real-time (NRT) search scenarios common in ecommerce and retail, where factors such as new product listings, stock levels, and fluctuating business metrics (like demand) are crucial.
Moreover, fine-tuning and optimizing the models that embed data into vector space is more challenging than it initially appears, especially over time. These systems regularly experience a notable decline in performance as time goes on, adversely affecting business KPIs. This issue is amplified when decisions to implement these systems are made based on a single initial experiment or test 🤦. One contributing factor, in system performance decline, is the use of information-rich multimodal embeddings, which can lead to a phenomenon known as the Modality Gap or Contrastive Gap. In such cases, embeddings do not form a consistent and coherent space but instead form distinct subspaces, despite being trained and fine-tuned to avoid this outcome.
3. Significant increase in cost per query
Due to the added complexity and the substantial increase in computational demands of hybrid systems, many ecommerce shops experience costs 10 to 100 times higher per query. Our aggregated data indicates that keyword-based searches usually cost equal to or less than 0.05 cents per query. However, in hybrid search scenarios, we’ve observed costs ranging from 0.25 to 2 cents per query, depending on the vendor or system used. Although these amounts may seem small individually, they quickly accumulate when processing millions of queries each month, significantly squeezing already tight profit margins. This cost escalation comes at a time when economic challenges make efficiency one of the most crucial factors for market sustainability.
4. BM25, Tokenization and vocabulary size
In many hybrid systems, keyword retrieval often relies solely on BM25, which is not ideal for ecommerce contexts. Critical aspects like model numbers, price ranges, sizes, dimensions, negations, lemmatization, field weights, and bi- or trigram matching are frequently neglected.
Additionally, unlike everyday language, ecommerce data is characterized by highly specific, low-frequency vocabulary. Examples of terms, you’d be hard-pressed to find in everyday language but appear disproportionately often within ecommerce:
brand names
model names
marketing colors
sizes
etc.
The issue is that most embedding models used for vector retrieval struggle to capture this kind of terminology. Why is it such a challenge for vector search to include this type of mundane information? Vector search has a smaller vocabulary due to constrained memory and efficiency limitations. It’s no fault of vector search, but rather a question of using the right tool for the job. More on that later.
While we currently manage vocabulary sizes ranging from 1.5 million to 18 million unique entries, most embedding models (vector search solutions) that are performant enough for ecommerce scenarios top out at around 100,000 to 250,000 unique entries. Words or tokens not included in these vocabularies are approximated by their character fragments (ngrams) and their corresponding probabilities. As with any form of approximation, this can compromise result precision.
Vector search can be useful in handling misspellings due to its ability to leverage contextual subword information. However, it can perform poorly if the embedded tokens are not well-represented in the training set.
Vector search, or dense retrieval, can significantly outperform traditional methods, but there’s a catch: it requires embedding models that have been fine-tuned for the target domain. When these models are used for “out-of-domain” tasks, their performance can decline dramatically.
If we have a large dataset specific to a domain, like “fashion items,” it’s possible to fine-tune an embedding model for that domain, resulting in dense vectors that offer strong or decent vector search performance. However, the challenge arises when there isn’t enough domain-specific data. In such cases, it’s possible that a pretrained embedding model may outperform traditional keyword search, but it is highly unlikely.
This is the situation we most often encounter in production environments. B2B ecommerce shops usually have a wealth of data about their products and services but lack comprehensive domain data that could help them better understand customer queries.
6. Multilingual understanding
While many search vendors assert a significant increase in natural language understanding query volume, our production data does not support this claim. We observed a slight upward shift, but not substantially or statistically significant. However, what has notably increased are multilingual queries. Cross-border commerce is becoming more prominent. Multilingual queries originating from foreign languages across Europe now account for about 2-7% of ecommerce search volume. Along the same lines, we see an increasingly diverse mix of queries in English, French, Spanish, Italian, Chinese, Turkish, Arabic, and Russian in our customer logs.
Later in our evaluation, we’ll show how most current embedding solutions, including advanced multilingual cross-encoders, struggle with handling and understanding low-frequency vocabulary (infrequent search terms) across several of these languages.
As it stands, there is no universally proven “best” approach for effectively combining the results of keyword and vector-based retrieval strategies in hybrid search. Existing methods like Fusion and Re-ranking are evolving, but still fall short of realizing the full potential of hybrid search. This owes largely to each strategy’s distinct strengths and weaknesses, making it challenging to achieve an optimal combination.
Fusion combines results from different search methods based on their scores and/or their order. It often involves normalizing these scores and using a formula to calculate a final score, which is then used to reorder the documents.
Re-ranking involves reordering results from various search methods using additional processing beyond just the scores. This typically includes some more in-depth analysis with models like cross-encoders, which are used only on a subset of candidates due to their inefficiency on large datasets. More efficient models, like ColBERT, can re-rank candidates without needing to access the entire document collection.
However, these methods often struggle to dynamically adapt to different query types, resulting in inconsistent performance across various scenarios, which we will show later.
Analyzing current approaches
This seeming divergence between these two methods led us, along with our customers, to question whether there are more efficient approaches that fully leverage the strengths of both retrieval strategies. Preferably, we are looking to create a scenario where 1+1 is equal to or ideally greater than 2. We began by analyzing specific customer use cases. Our goal was to deeply understand the specific problems our customers sought to address when they adopted or transitioned to hybrid search.
We studied how these two improvements affect hybrid search in real-world production. Since searchHub is built on an experimentation-centric approach, we can evaluate performance at global-shop, search-shop, and query-specific levels for our customers. Unlike many vendors who claim hybrid search is the best retrieval method without providing concrete data, we aim to share our findings with our customers’ permission. A big thank you to them for that. Please note that the numbers presented are based solely on hybrid search systems that are not under our direct control, whether developed in-house or sourced from external vendors.
Setting up the analytical foundation
As previously mentioned, we began by identifying and analyzing the specific problems and use cases our customers initially set out to address. We distilled these into the following types of queries they aimed to improve:
Query Type Definitions
To offer some quantitative insight, here is the distribution of query demand and search frequency across these types, based on data from the customer base that participated in this analysis. In total, we identified 3,000 unique queries, representing 83% of the overall search demand from these customers. The distribution of these 3,000 queries across the different query types is shown below.
Query Type Dispersion
For each participating customer, we selected the top 100 queries and additionally sampled (random weighted sampling) 100 more from the mid- and long-tail for each query type and customer to evaluate competitive retrieval strategies.
For evaluation, we opted for a straightforward approach using precision@k. Each selected query was compared against the results from different retrieval strategies by counting the number of “relevant,” “strongly related,” and “irrelevant” items in the top 12 positions. For each “relevant” item in the top 12 results, we assign a score of 2, for each “strongly related” item a score of 0.5, and for each “irrelevant” item a score of 0. We then use simple addition to aggregate these scores, which we refer to as “relevance points.” The more relevance points accumulated per query type, the better the performance of the specific retrieval strategy for that type.
We acknowledge that this evaluation method may not align with industry or research standards, but we prioritized feedback, clarity, and ease of debugging for our customers over adherence to strict, unhelpful standards. More importantly, we were able to prove that optimizing according to precision@k had a significant positive impact on the relevant business KPIs CTR, A2B, CR, AOV and ARPU while other standard evaluation methods like NDCG failed to do so.
Recall@12 vs. Precision@12
Recall@12 Analysis
Precision@12 Analysis
For BM25 we used standard Elasticsearch, ES OCSS and CLIP retrieval was done via marqo.ai
The possibility to distinguish different query-types gave us a lot more insight into the pros and cons of hybrid search, as it clearly demonstrated the true potential compared to a global view.
The first table shows that the vector retrieval component of hybrid search excels at enhancing recall when using a multimodal model like CLIP (which can leverage text and image information). This is especially true for query types where recall is typically a challenge (such as type-1, type-2, type-7, and type-8), resulting in significant recall improvements. The table also shows that, even in the ecommerce domain, traditional keyword retrieval can achieve substantial gains in recall compared to the standard BM25 algorithm — from 70.5% to 81.57% with ES OCSS.
The Precision@12 analysis indicates that hybrid systems are not fully achieving their potential. While they improve precision@12 significantly for queries where recall is the main issue (about 15% of queries), they also cause substantial drops in precision@12 (in 12-28% of cases) for many scenarios where keyword-based search alone performs exceptionally well. Hybrid systems may achieve considerable improvements for certain query types, but they often rely on local rather than global optimization. In the end, even the newest technology needs to balance recall and accuracy. There is no one-size-fits-all solution.
Even approaches that combine high-recall vector retrieval with fine-tuned re-ranking often struggle to select or emphasize the most relevant parts when the initial set of retrieved results becomes more ambiguous.
Summary
We learned that a hybrid retrieval system alone cannot determine where or whether a specific query’s performance is improved. With this new information, it is clear that choosing the best retrieval strategy (keyword-only, vector-only, or blended hybrid) for each query should lead to big improvements in overall performance.
Despite the expected improvements in recall, we have also shown that improving precision or even maintaining it is much more challenging. Unfortunately, most marketing and sales efforts tend to focus on recall only when trying to sell you their vector search solution, while our data clearly indicates that precision correlates much more with sales and conversion than pure recall.
Taking all these insights and the other identified areas of improvement into account, we developed a radically different new approach called NeuralInfusion™ to address these gaps. This new approach will hopefully fully harness the potential of hybrid search, while being significantly more efficient. Stay tuned for part 2, where we will explain this new idea in more detail and compare it to other ideas we looked at before.
Enhancing efficiency, accuracy, and customer satisfaction are foundational optimization factors both when managing vast product inventories offline or optimizing onsite-search with redirects. Just as a well-organized inventory ensures quick and precise product retrieval, search redirects streamline the user’s journey by guiding them directly to relevant content. This digital parallel highlights the importance of strategic organization and management in both physical and digital spaces to improve overall user experience and business outcomes.
Are librarians the real pioneers of ecommerce site-search?
Do you remember librarians?
The word, librarian, always reminds me of that one Michael Jackson song, “Liberian Girl”. As a kid, I thought he was saying: “librarian girl” 🤦 😁.
I digress …
At the library, Librarians had an almost mythical status. Acting as a shortcut right through the heart of the Dewey Decimal Classification. Of course, if you had the time, there were other options for finding a book. There was the card-catalog, and if you just wanted to meander, there were signs guiding you to different areas of interest. But areas of interest overlap. And the card-catalog required you to know at least a book title or author to get any further. A book about climbing, for example, could just as easily be in either the sports or health categories. Before too long, you could easily find yourself running all over the library on a wild-goose-chase looking for that perfect book.
For the most part, when I went to the library, however, I had a good idea of what I was looking for. I knew the subject, or maybe the author, so I would frequently head straight to the card-catalog. On more than one occasion, though, I would stand in line at the librarian’s desk to tap into the secret power that was The Library Gods. Of course, you’d have to have a bit of luck. There was never a guarantee that the librarian would be at her desk. And, what’s more, she’d have to be willing to help you, and not just direct you to the catalog-cards. So, you’d flash your charming eyes and ask if she could help you find your book. If all went well, she’d look at you over her glasses, stand up, and walk across this tremendous room with vaulted ceilings, to the exact location of your book, pull it out, hand it to you, and then begin providing suggestions for further reading on the topic but in a different part of the library. It was pure, sorcery.
Now, that we’ve evolved away from library use, I’m wondering … where’d the magic go? Remember the last time you navigated to your favorite ecommerce website, using the latest in cutting-edge site search technology, typed in your search term and, like witnessing the all powerful sorcery of a well-versed librarian, you immediately got the result you were looking for
Nah … didn’t happen.
Or at least not consistently.
To top it off, there’s no way to quickly speak with a search engine. It’s like a librarian, who’s not interested in what you’re looking for at all. Imagine getting a response like: “this is your book, babe. Take it or leave it!”.
But, like masochists, we take it on the daily, from site-search engines the world over. Sometimes, you don’t even find anything related that would help guide you in your search process. Instead, you get a list of results that make you question, whether you may have clicked into the wrong shop altogether.
One might be tempted to begrudge ecommerce site-search vendors, or the ecommerce industry as a whole. Especially, when considering the history (from 7th century B.C.) of product catalogization. But alas, product data retrieval has not evolved linearly. Its haphazard, almost accidental improvement over the last 30+ years, has not infrequently been the bane of many an ecommerce manager’s existence.
Only recently, with the advent of Large Language Models, increased computational power, and sinking hardware costs, has product search began to nudge its way back into the sphere of magical sorcery. Even so, for the vast majority of ecommerce shops, it remains a black art to this day. No matter their level of product search mastery.
It behooves us, in light of the above, to briefly pause and pay homage to the dark art of librarian sorcery, and its nexus … the human brain. I mean, Christ, it’s been holding the keys to product discovery, like it ain’t no one’s business, going on 6,000+ years.
And for all ecommerce search’s shortcomings, we must consider the grandness of our task these last decades: to reproduce a neural cataloging structure that mimics the very powers of our favorite librarian. Breaking this code, and laying it free for all humanity to benefit from, is something comparable to supplanting said librarian, and expecting her to perform feats of magic irrespective of the library, the language, or the subject she’s confronted with.
It will simply fail.
So where do we begin?
Mimicking human classification methods
Building on the idea of the library, how do we go about searching specifically enough, to lead customers to their intended product as efficiently as possible, while simultaneously making them aware of related or similar products, with different names, in different categories, but directly related in scope or kind?
This type of product display (or information delivery) is necessary because it mimics the way the human brain catalogs information.
So how do I do it, how do I mimic the ingenuity of human information retrieval?
Before we get ahead of ourselves, let’s take a moment to acknowledge the technologies and strategies that have gotten us to where we are.
Search filters
Curated landing pages
Product finders
These tools are helpful and necessary. However, they all assume the customer knows precisely how to find their product. Product finders, are often hidden within category landing pages, or appear after a related search (all spelling mistakes aside). Curated landing pages, again, are triggered only if a certain keyword is entered. Search filters are only then relevant if the customer has managed to land in the general location of their product of interest.
This leads to unnecessary frustration, for the uninitiated first-time-visitor to your shop. And what’s more, the strategies, aren’t increasing search conversions like you think they are. Even for the visitors using them. They simply provide another point of entry for those visitors who already have a good idea of what they want.
This is not a trivial problem, and one for which AI was predestined.
So what’s the alternative to current site-search-journey optimization?
Consider a smarter alternative to the above. Imagine consolidating all keyword variations that verifiably lead to the purchase of the same article. Then, in a feat of sheer brilliance, funnel all traffic generated by this keyword-cluster, to a dynamically populated landing page.
It’s at this point that we return to the above-mentioned search optimization strategies. Because, now, you’ve ensured that a broader audience of highly targeted consumers reach the right page. As a result, your product finder reaches the appropriate people with a relevant product suggestions for an audience in market. What’s more, context-driven search filters are considered helpful by your audience because they match expectations. Expectations that were gathered at the point the keyword was entered into the search box, allowing you to create a CONTEXT, not simply from a single keyword, but a whole cloud of keywords related to the customer’s topic of interest.
So, now, not only do you return spot-on search results, but simultaneously whet the appetite of your customers for more, based on a highly relevant result context.
All of this can’t be cumbersome or overly engineered, requiring scientific rule-sets. And … it has to be possible without changing search vendors because that’s a shit-show of epic proportions. Nah, it’s gotta be an intelligent AI perfectly mimicking the magical associative sorcery of a librarian.
searchHub AI Search Redirects
This is where AI-Search-Redirects comes in.
Like a librarian leading visitors to their precise book, customers are led directly to their product. What’s more, AI allows categorical connections between products. This is like the librarian leading you to different sections of the library, making you aware of related content and media. Whether a book, magazine, video, or that 35mm archiving machine that saved everything onto film.
This is a monumental step forward for site search. The last decades have focussed on lexical similarities. Think fuzzy logic, phonetics, synonyms/antonyms, and the like. AI-Search-Redirects considers all these lexical properties, but now as a piece in the puzzle that is the shopper’s context. We consider things such as categorical proximity, and go as far as evaluating visual likeness between products. This translates to maximum efficiency, while maintaining ultimate flexibility.
Maximum Efficiency, ultimate flexibility
Off-loading bulkier search management tasks to AI increases efficiency. Think about the ability of artificial intelligence to identify contextually related lexical, orthographical, and visual signals to deliver an optimized user-experience for each possible query.
This in no way undermines ultimate flexibility when managing search manually. Integrating AI assistance into your search optimization is not an “either, or” decision. Good use of technology, always presents the best possible mix of all existing options. In this way, AI-Search-Redirects is a “yes, and” addition to your current search optimization workflow. Like an autopilot, guiding a plane or automobile to its destination, there is always the flexibility to take control and edit customer search journeys manually.
Like signs that guide us through a library, a card-catalog, or the librarian at the front desk, AI assistance works in the background so that customers always receive the most optimized product listings, ensuring the highest shop revenues.
How Can I Trust the Accuracy of the Results?
You might be weary of optimizing your site-search by machine. With over 25 years of site-search-optimization experience, we were too. That’s why we backed-in continuous A/B-Query-Testing from the start.
searchHub runs continuous a/b query tests against all query edits, even after they’ve been optimized. No matter if AI, or manual human intervention. Continuous A/B Query Testing ensures the most accurate, optimized search result for the consumer experience in question. If at any point a better performing query variation should emerge, it is flagged and awaits human confirmation.
Customer satisfaction
Customer satisfaction is paramount to search optimization. 15% of customers are using search terms, you’ve never encountered before. It goes without saying that customers who are unhappy with the search results, won’t purchase from you. Because of this, we’ve taken great pains to integrate customer sentiment into our AI. We’ve even gone as far as creating two new KPIs, just to be sure, because we weren’t happy with the way site-search journeys are currently measured.
Findability
Sellability
Product findability evaluates how easily products were found after entering a keyword into the search box. Based upon this information, we create either a positive or a negative association between the keyword and the related product result set.
Product Sellability, measures to which degree products are added to the basket for a given keyword cluster. searchHub then records positive (a product was added to the basket), and negative associations (no product was added to the basket) respectively.
As you can imagine, there are myriad ways to combine these two KPIs. Just to give you an idea of the complexity, we evaluate all associated keywords (variations, typos, misspellings, synonyms, etc.), and all products within the result-set viewed by the customer.
In the end, searchHub provides your existing site-search with something no one has ever seen before: clarity. Clarity of customer context. And clarity about what it means to have an optimized customer search journey.
True site-search personalization is a conversation
AI-Search-Redirects, allows you to communicate clearly back to the customer. And why shouldn’t you? The site-search is the only place on your website, where customers condense their intentions into a limited number of keywords, telling you what they want from you. Nowhere else, on your website, do you have the opportunity to be this personalized with your customers.
AI-Search-Redirects leads highly qualified traffic to curated landing pages
The last piece of AI-Search-Redirects, is the redirect. Once the AI has analyzed your shoppers’ purchase behavior, and clustered all variations of keywords leading to purchases of the same product, it’s time to test which keyword within a cluster will be the one to receive all the cluster traffic. Once that’s in place, it’s time to create the store window those customers will see when they land on the result set. It’s no different from what you’ve been doing the last 20 years in ecommerce. Only now, these strategies yield the returns you’ve been looking for:
Product Placement Which products and categories will appear most prominently.
Signage Category Banners, offers, partners
Advertisements Highly qualified search traffic is more easily monetized programmatically.
AI-site-search redirects, are the foundation for highly optimized, high-return, dynamic landing pages for each customer query.
It’s remarkable to think this is all possible without changing your site-search vendor. Maybe we have created the perfect modern librarian: one that functions equally well, no matter the “library” (shop, or search technology). In that case, I take back what I said earlier: I am hopeful about the state of site search. And you should be too! 😀
If you’re not already working with searchHub, reach out to us! We’d love to hear the pains and woes of your journey, designing context-driven customer site-search journeys.
We’re committed to fostering a culture at searchHub that prioritizes continuous learning and rapid innovation. It’s super important to us that the development and use of new products and features by our teams enhances the search and recommendation algorithms of our customers. These things have to have a quantifiable positive impact on their business objectives and success metrics. For this reason, no small part of our decision-making process involves meticulous data analysis through well-designed experiments, commonly referred to as A/B tests.
A/B Testing for Search is Different
Conducting A/B testing for search involves various considerations, as there is no one-size-fits-all approach. (we have already covered this topic on several occasions, both here and here).
Choosing a specific metric to evaluate is important, such as click-through rate (CTR), mean reciprocal rank (MRR), conversion rate (CR), revenue, or other relevant search success indicators. From there, determining the optimal duration for each test is critical. This is necessary to achieve any statistical significance & weight, considering the potential impact of a novelty effect. Contrary to what we’d all like to believe, A/B testing for search is not a simple switch or additional add-on. It’s a scientific process that requires thoughtful planning and analysis.
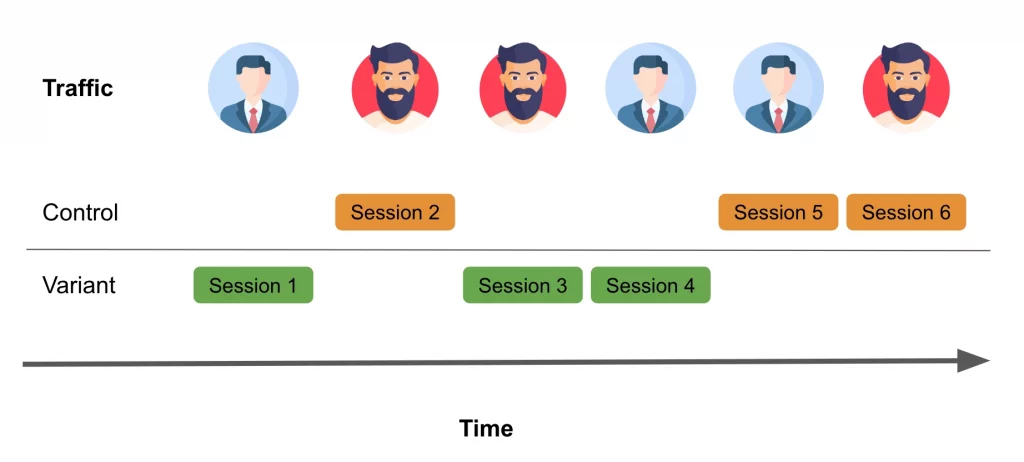
From Sessions to Search-Trails as randomization unit
When scoping a search A/B test, it is advisable to consider search-trails. Here are some reasons why:
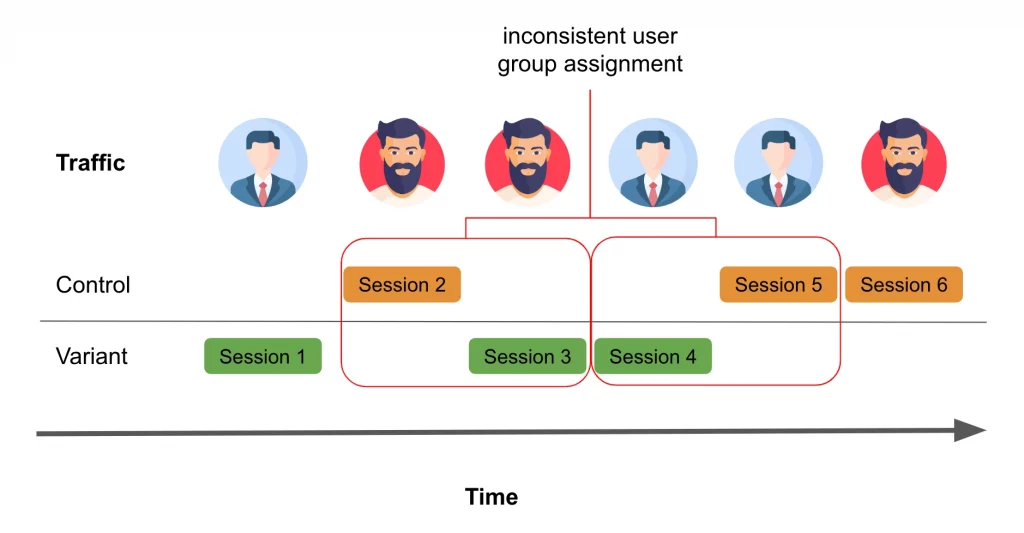
Too strong a focus on user sessions can sometimes disconnect cause and effect in eCommerce. User sessions often involve various actions that may be unrelated, potentially resulting in the identification of differences irrelevant to the search experience. Additionally, search queries are far from normally distributed over your user base – consequently, user-splitting dramatically reduces the number of tests you can do in parallel.
Conversely, relying on individual search queries may lead to scenarios where improvements made to targeted queries adversely impact other queries’ performance within the same search sessions.
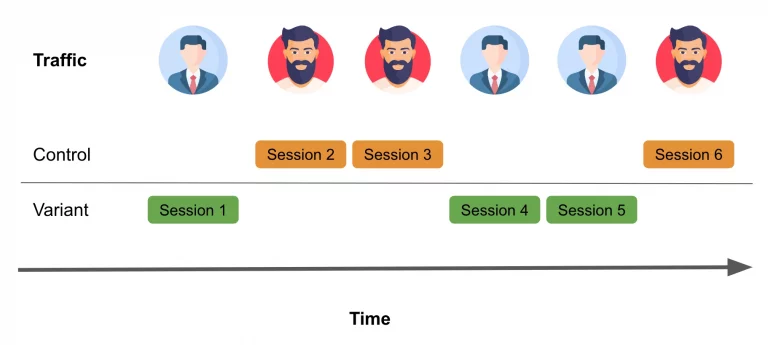
This is why, once we began getting into the weeds, our initial step was to shift the randomization unit from users to query-search-trails. A query-search-trail is like a micro-session beginning with an intent (query) and ending with actions/events that change the intent (more details can be found here). This adjustment allows us to make the most of the available traffic for each query, utilizing every search query from every user. With user sessions typically encompassing various search paths, we can now harness this wealth of information to enhance the robustness of our experiments.
Along the way, we were surprised to discover, compared to traditional user-based randomization, how the number of query experiments with valid results are significantly boosted by our decision to focus on query-search-tails. We’re talking almost about an increase in order of magnitude. However, it does introduce certain challenges. Most notably, we need to come up with a different way to handle late interaction events, like checkouts. These have the potential to compromise the independence assumption.
Automatically detecting and creating Query Experiments
Considering that the majority of our customers deal with hundreds of thousands or even millions of diverse search queries, and still aspire to enhance their north-star search Key Performance Indicators (KPIs) at scale, it is evident that solely relying on users to manually create experiments is impractical.
So, we designed a pipeline capable of automatically identifying query pairs. These query pairs have to, on the one hand, provide enough value to warrant comparison in the first place (that means show enough difference), while also providing evidence that they will produce valid results based on predefined experimentation parameters. The current pipeline is capable of generating and running thousands of query experiments simultaneously across our user base. On top of that, it has proven to be a valuable resource for conducting efficient experiments that contribute to search optimization.
Tackling imbalanced and sparse Search Experimentation data
Above, I mentioned our decision to employ Search-Trails as a randomization unit. Despite the discussed advantages and disadvantages, the reality is that a significant portion of search-related events are both sparse and imbalanced. To illustrate what I mean: There are instances where merely 10% of the queries receive 90% of the traffic. For the longtail, this means relatively few interactions, such as clicks or adding items to carts. Although our intent-clustering approach effectively mitigates data sparsity in interaction data to a considerable extent, our primary focus remains centered on addressing the imbalance of the experimental data.
An example of an experiment with imbalanced data:
Managing imbalanced data in experiments is challenging – (also referred to as SRM). It also has the side effect of significantly impacting the statistical power of your experiments. To maintain the desired power level, a larger minimum sample size is necessary. Naturally, acquiring larger sample sizes becomes problematic when dealing with imbalanced data.
We adopted two strategies to address this challenge:
Maximize efficiency by minimizing the required minimum sample size or run-time. To achieve this, we employ techniques such as CUPED and GST while maintaining power levels. Particularly in the context of an automated experiment creation system, accurately identifying efficiency and futility boundaries is crucial for driving incremental improvements through experimentation.
Surprisingly, we discovered ways to substantially diminish this imbalance. How?
Well, it turns out that within a session, we can influence the likelihood of a user triggering a specific query through auxiliary systems designed to assist users in formulating their queries (such as suggestions, query recommendations, etc.). This approach significantly reduces the imbalance in the majority of cases we encountered.
TESUTO – Granular Search Experimentation @scale
Over the past few months, we’ve gradually introduced our “Query Testing” capability, powered by TESUTO, to our customer base. The advantages of granular experimentation at scale are increasingly apparent. Simple modifications in search functionality, such as incorporating synonyms, adjusting field-boosts, or modifying the product assortment, are now evaluated based on real data rather than relying solely on intuition.
If you’re interested in leveraging the benefits of Query Testing, please don’t hesitate to click on the button and reach out to us.
For those curious about how we developed TESUTO, including GST, CUPED, and more, stay tuned for upcoming blog posts where we delve into these topics in more detail.
In one of our latest blog posts, my colleague Andreas highlighted how session-based segmentation in A/B-tests might lead to wrong conclusions. I highly recommend you read his post before continuing. In this blog post, I’ll show how session-based analysis in A/B-tests will destroy your precious work when optimizing site search.
tl;dr: If your business case involves only single-item baskets and 90% of your orders consist of only one article, you can skip this post.
All others: welcome to another trap in search experimentation!
Measuring the Unmeasurable
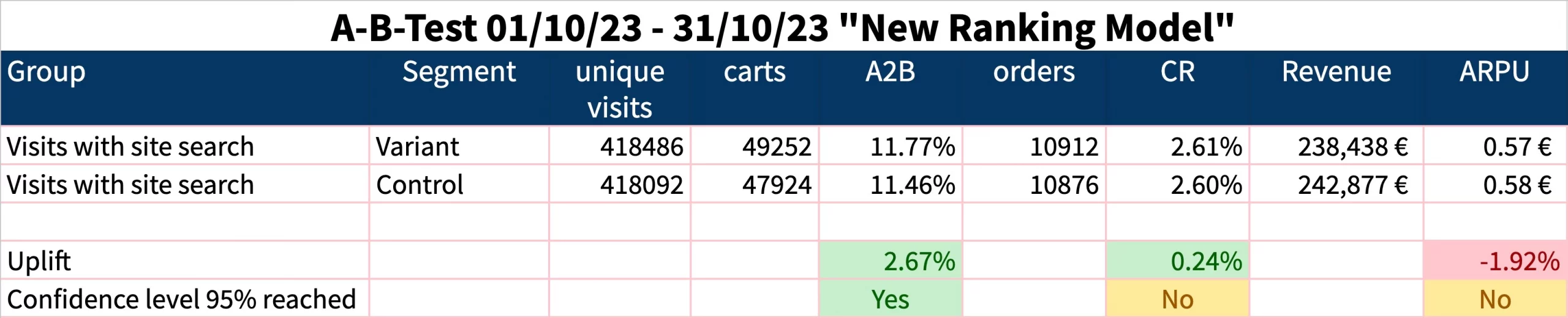
Let’s say you and your team put significant effort into optimizing your product rankings for search result pages (SERP). Most of the formerly problematic SERPs now look much better and seem to reflect the requirements of your business more than before. However, if your key performance indicator for success is “increase shop revenue through onsite search”, you’d be short-changing yourself and jeopardizing your business’s bottom-line. Let me explain.
First of all, it’s a good thing that you understand how crucial it is, to test changes in the fundamentals of your onsite search algorithm. I mean, it’s clear that these changes influence lots of search results, which you would never even think about. Let alone be able to judge personally. And proving the quality of your work might also influence your personal bonus. That’s why you do an A/B-test before rolling out such changes to your whole audience. You do that, right? Right???
Well, after a while, you check the results in your A/B-test or analytics tool. Following standard best practices not only of Google Analytics but also many (if not all) web analytics tools, the result might look like this:
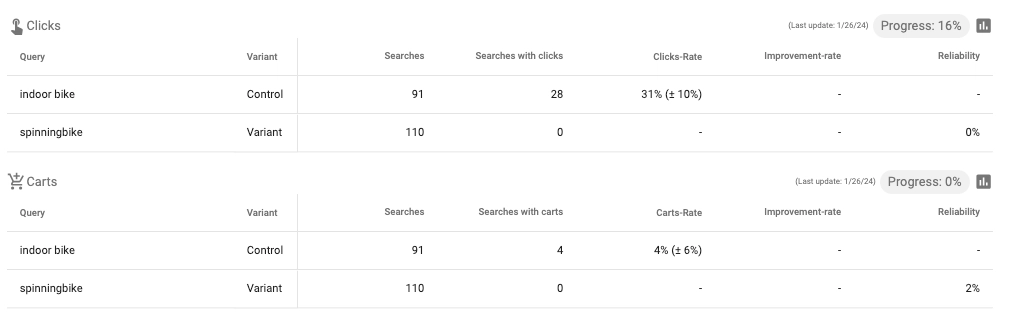
(report showing ambiguous results: Although AddToBasket-ratio increased significantly, no significant increase in overall conversion rate was measured, while revenue decreased slightly).
What will your management’s decision be based on this result? Will they crack open a bottle of champagne in your honor, as you obviously have found a great option to increase revenue? Will they grant you a long – promised bonus? Most likely not, unfortunately. A glass of water will suffice, and you should be thankful for not being fired. After all, you shrank the revenue.
The problem: You didn’t test what you intended to test.
What you wanted to test: how each search result page performs with your new ranking algorithm compared to previous rankings.
What you actually tested: All carts and orders of all users who happened to perform at least one site search during their visit.
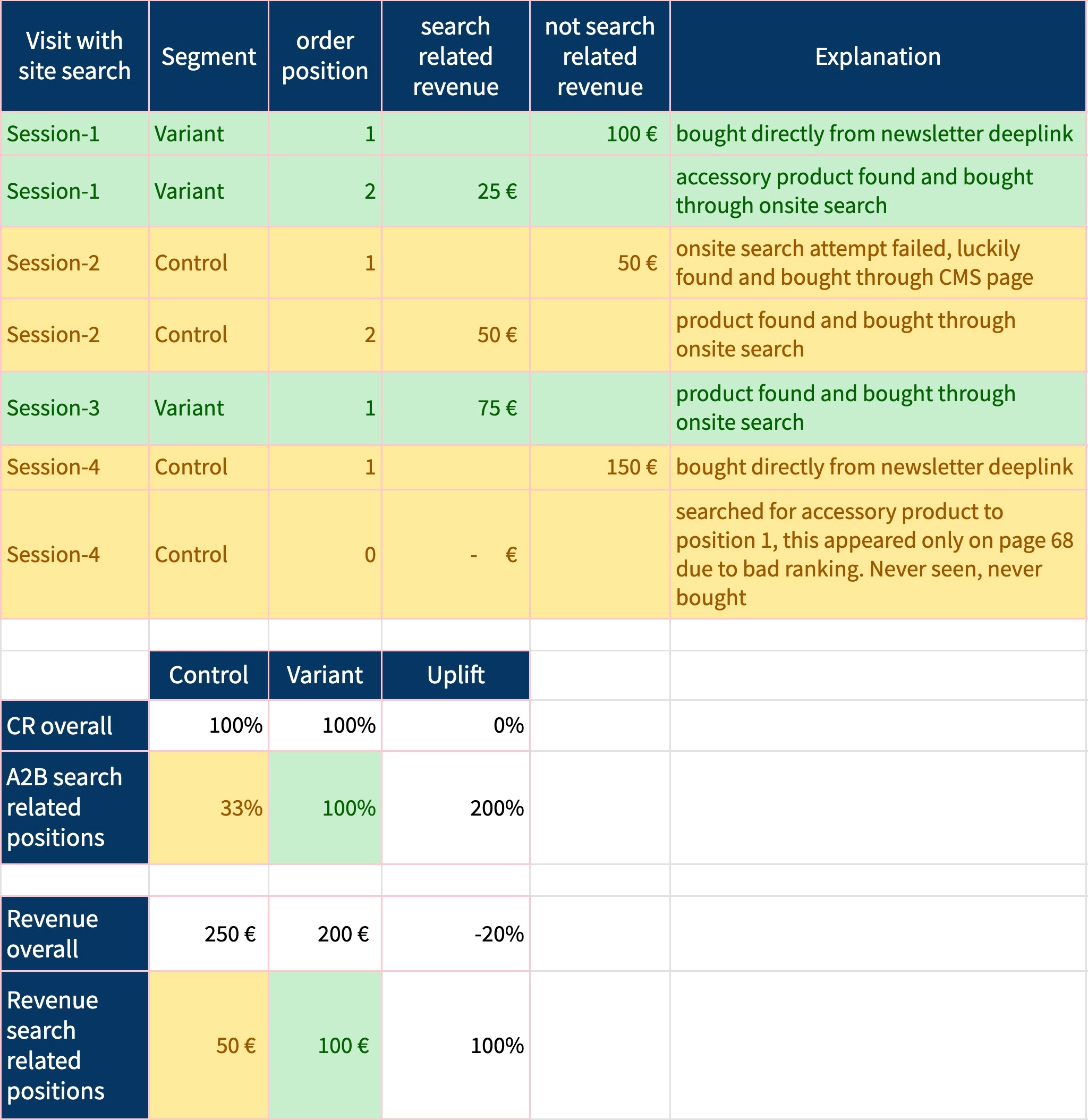
Imagine you were able to show your management a detailed view of all search-related sessions, with specific explanations of each position in the basket that was really driven by search requests. Which products were not bought because they could not be found? Which other products were bought but not search related?
Maybe similar to this example here:
(detailed view of search related sessions showing improved search performance when measured directly)
Chances are high that someone will tap on your shoulder stating: “We see very nice improvements to our customer journeys where search is involved. You did an awesome job optimizing the search.”
So what happened here?
A vast majority of visits will not start with a customer thinking: “Such a nice day. I’d finally like to use the search box in myfavoriteshop.com”. Instead, they will reach your site via organic or paid links or click on a link in your newsletter promoting some interesting stuff – well, you know all the sources where they come from, that’s potatoes for your analytics tool.
In many cases, the first product to be put into the basket is more or less easy going. But now they start to think: “I’ll have to pay €5 for shipping, what else could I order to make it worth it?” Not only does search become interesting at this point, but your business begins creating opportunities. Larger order – higher margin, as your transaction costs sink. A well-running search engine might make the key difference here. But, do not attribute the revenue of the first cart position to the search engine, as it had nothing to do with it!
If your analytics or A/B-testing tool shows some report starting with “visits with site search”, a red alert should go off in your head. This is a clear indication that the report mixes up a lot of stuff unrelated to your changes.
Why is this a problem?
Search is important for your e-commerce site’s success. Because statistics love large numbers. It’s true, search provides large numbers, but order numbers are much smaller. Let me give you a simplified, but nevertheless valid example: Let’s assume your search has improved by 10%. Naturally, this should also be visible as a 10% increase in orders overall:
Now we can ask statistic tools if this is significant. (You might want to start with here). The result may come as a surprise.
(While CTR increased significantly, the increase is not strong enough for a significant increase in CR)
What? It affects my orders the same as my search overall (10% or 45 more orders), but it’s not significant? That’s because statistics want to provide a rather failsafe result. The lower the numbers and the smaller the relation between success (an order) and trials (each user), the harder the proof for an increase.
So chances are high that your A/B-test tool will consider the result as “insignificant” when trying to find the signal in the generic data. If you are Amazon or Google, this is not a problem you need to bother with – your numbers are large enough. Everyone else is obliged to dive deeper into the data.
How do we do this at searchHub?
Over the past years, we have built a powerful framework to track search related events. Our searchCollector can be easily integrated into any e-commerce site. Without tracking any personal data, but very high consent ratios, we can collect traffic from most of your customers. We precisely track the customer journey from the search bar to the basket, also identifying when this journey is interrupted and a new, non-search-related micro-journey begins:
This allows us to capture search-related KPIs in the most precise way. Not only can this be used for your daily search management work, but also for fine-grain A/B testing. By eliminating erroneous effects like non-search-related basket positions, we show exactly and with high statistical accuracy, how changes in your search algorithm, search engine or even search configuration perform.
OK, understood – what can I do?
First: Make sure you’re precisely measuring the stuff you want to be measured.
Second: Don’t rely on summarized numbers, when you know that they include customer decisions that you cannot influence.
Third: Remember that in a random setup, 5% of all A/B tests will prove a significant difference. That’s what alpha=0.05 in your testing tool or A/B-test report means.
Experimentation plays a pivotal role in search systems. It has the capability to improve performance, relevance, and user satisfaction. An effective search system is a must in this dynamic digital landscape. It needs to continuously adapt to meet the evolving needs and preferences of users. Experimentation provides a structured approach for testing and refining various components. Some common examples are algorithms, ranking methods, and user interfaces. Methods like controlled trials, A/B testing, and iterative enhancements, make search systems robust. In this way, search parameters are fine-tuned, innovative approaches assessed, and search result presentation optimized. Not only does experimentation enhance the precision and recall of search results. Using the correct experimentation method enables adaptation to emerging trends and user behaviors. As a result, embracing experimentation as a fundamental practice empowers search systems to deliver accurate, timely, and contextually relevant results. This enhances the general user experience. It’s no wonder that A/B tests are the gold standard for determining the true effect of a change. Even so, many statistical traps & biases can spring up when tests are not set up correctly. Not to mention that the approach to A/B testing for search is not one-size-fits-all. It’s rather a science that requires careful consideration. In the following text, I will highlight some of the most common A/B test pitfalls we’ve encountered in the past decade in connection with onsite search.
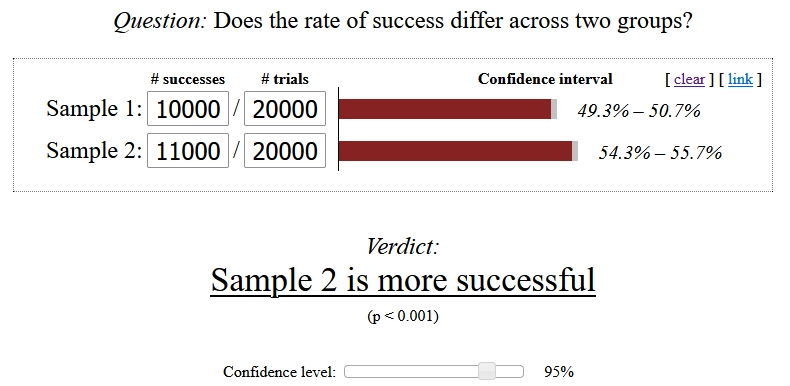
Your Test Is Too Broad, Pitfall.
Small changes to your search configuration won’t impact the majority of your search traffic. Validation of these changes turns into a challenge. Especially when taking all traffic into account. To address this issue, segment your search traffic based on the affected queries. Then evaluate them selectively. Failing to do so may dilute the effects of the changes when averaged across all queries. As an example, there’s a growing trend to confirm the positive impact of vector search on key performance indicators (KPIs). If we focus solely on Variant A (without vector search) and Variant B (with vector search), nearly 90% of the tests showed no significant differences. However, when we segmented the tests based on specific criteria, such as queries containing more than five words, the differences were statistically significant. This underscores the importance of analyzing subsets of your search traffic. In this way, you capture meaningful insights when assessing the impact of configuration changes. So to gain more useful insights, you need to report results across all segments. It’s important to remember that we’re talking about averages. Positive in sum doesn’t mean positive for everyone, and vice versa. Always slice your data across key segments and look at the results.
Focusing exclusively on late-stage Purchase Funnel KPIs – introducing a Carry-Over Effect, Pitfall
In challenging economic climates, businesses prioritize revenue and profitability to ensure sustainability. This is also our observation. A growing number of clients focus on experimentation. They rely on Average Revenue Per User (ARPU) as their primary success metric. As a result, recognizing some fundamental challenges with ARPU attribution bear mention. For example, ARPU has a direct impact on causality, affecting result accuracy.
Some Background on A/B Testing and Randomization:
A/B tests, or experiments, test several variants to determine the best performer. One audience group receives the original variant. This is the “control”. At the same time, another group receives a new variant that differs in some way from the control. This group is the “treatment”. An essential aspect of conducting an A/B test is determining how to define these two groups. Picture comparing two website versions to determine which benefits your business more. You would, first, split your target audience into two equal parts at random. Then, give each group a different experience by selecting the appropriate randomization method. The three most common methods are:
Page Views: select either version A or version B at random for each displayed page.
Sessions: are a series of page views grouped by user over a specific time-frame. Session-level randomization shows either version A or B during a session.
Users: Users represent individuals or close approximations. Logging in provides clear identification with a userID. Cookies work for sites without logins, but you lose them if cleared, devices switch, or the browser is changed. That’s why they remain an approximation. In user-level randomization, users view either version A or B consistently.
Defining variant groups requires careful consideration of the independence of your randomization units. When selecting decision criteria or KPIs like ARPU, there’s a hidden risk of carry-over effects. Let’s delve into this, as it plays a pivotal role in choosing between session and user-level randomization.
Independence Assumption of randomization units
Session-level randomization is an approach frequently employed, especially in the context of e-commerce websites. It can be combined with easily accessible metrics such as session conversion rate, which measures the percentage of sessions that result in a purchase. When implementing session-level randomization for your experiment on an e-commerce site, the process might resemble the following:
Consider the following scenario: Aaron visits a website and initiates a session randomly assigned to the control group, experiencing version A throughout that session. Meanwhile, Bill visits the same site but is exposed to version B during his session.
Later, Bill returns to the site on a different day, starting a new session that, by chance, is assigned to the version A experience. At first glance, this may appear to be a reasonable approach. However, what if Bill’s decision to return to the website was influenced by the version B experience from their previous session?
In the realm of online shopping, it’s not unusual for users to visit a website multiple times before making a purchase decision. Here lies the challenge with session-level randomization: it assumes that each session is entirely independent. This assumption can be problematic because the driving force behind these sessions is people, and people have memories.
To illustrate this issue further, let’s consider an example where we conduct an A/B test on a new product recommendation algorithm. If the treatment group experiences the new algorithm and receives a recommendation they really like, it’s probable that their likelihood of making a purchase will increase. However, in subsequent sessions when the user returns to make that purchase, there is no guarantee that they will fall into the treatment group again. This discrepancy can lead to a misattribution of the positive effect of the new algorithm.
Randomization at the session level, where each session is treated independently.
Let’s construct a simple simulation to explore scenarios like these. We’ll work with a hypothetical scenario involving 10,000 users, each of whom averages about two sessions. Initially, we’ll assume a baseline session conversion rate of approximately 10%. For sessions falling into the treatment group (version B experience), we’ll assume an uplift of around 2%, resulting in an average conversion rate of approximately 12%. For simplicity, we’ll make the initial assumption that the number of sessions per user and the session conversion rate are independent. In other words, a user with five sessions has the same baseline session conversion rate as someone with just one.
To begin, let’s assume that sessions are entirely independent. If a user like Bill experiences version B (treatment) in one session, their probability of converting during that session will be around 12%. However, if they return for another session that is assigned to the original version A experience (control), the session conversion rate reverts to the baseline 10%. In this scenario, the experience from the first session has no impact on the outcome of the next session.
Please refer to the appendix for the code used to simulate the experiment and the corresponding Bayesian implementation of the A/B test. After conducting this experiment multiple times, we observed the following results:
The A/B test correctly identifies a positive effect 100.0% of the time (with a 95% “confidence” level).
The A/B test detects an average effect size of 203 basis points (approximately 2%).
When sessions are genuinely independent, everything aligns with our expectations.
Randomization at the session level, considering non-independent sessions.
However, as previously mentioned, it’s highly improbable that sessions are entirely independent. Consider the product recommendation experiment example mentioned earlier. Suppose that once a user experiences a session in the treatment group, their session conversion rate permanently increases. In other words, the first session assigned to the treatment group and all subsequent sessions, regardless of assignment, now convert at 12%. Please review the implementation details in the appendix. In this modified scenario, we made the following observations:
The A/B test correctly identifies a positive effect 90.0% of the time (with a 95% “confidence” level).
The A/B test detects an average effect size of 137 basis points (approximately 1.4%).
With this “carryover effect” now in place, we find that we underestimate the true effect and detect a positive impact less frequently. This might not seem too concerning, as we still correctly identify positive effects. However, when handling smaller effect sizes, situations arise where this carryover effect leads to a permanent change in the user’s conversion. This causes us to completely miss detecting any effect. It’s essential to emphasize that this analysis explores the most extreme scenario: 100% of the effect (the 2% increase) carries over indefinitely.
Randomization at the user level
Opting for user-level randomization instead of session-level randomization can address the challenges posed by non-independent sessions. To circumvent the issues encountered with session-level randomization, we must make the assumption that the users themselves are independent and do not influence each other’s decision to convert. Let’s consider our loyal shoppers, Aaron and Bill, as an example of how user-level randomization would function:
In user-level randomization, each user consistently receives the same experience across all their sessions. After rerunning our simulation with user-level randomization and maintaining the same “carryover effects” as before, we observe the anticipated results:
The A/B test correctly identifies a positive effect 100.0% of the time (with a 95% “confidence” level).
The A/B test detects an average effect size of 199 basis points (approximately 2%).
With user-level randomization, we regain the expected outcomes, ensuring that users’ experiences remain consistent and independent across their sessions.
Recommendations…
If you suspect that your sessions may lack independence and could exhibit some carryover effects, it’s advisable to consider randomizing at the user level. Failing to do so may lead to an inaccurate estimation of the genuine impact of a particular change, or worse, result in the inability to detect any effect at all.
The magnitude of this issue will largely hinge on the specific domain you’re operating in. You’ll need to critically assess how substantial the carryover effects could be. Furthermore, the impact level will be influenced by the distribution of sessions within your user base. If the majority of your users visit your platform infrequently, on average, then this concern is less pronounced.
It’s important to note that user-level randomization typically involves the use of cookies to identify users. However, it’s worth acknowledging that this approach does not guarantee unit independence. Cookies serve as an imperfect representation of individuals because a single person may be associated with multiple “user cookies” if they switch browsers, devices, or clear their cookies. This should not deter you from implementing user-level randomization, as it remains the best method for mitigating non-independence and ensuring a consistent user experience.
Tip: Apply Guardrail Metrics Given that these challenges described are prevalent in the majority of experiments and are challenging to eliminate, we have discovered an effective ensemble approach to minimize erroneous decisions. Rather than concentrate solely on late-stage purchase funnel Key Performance Indicators (KPIs), it is advisable to augment them with earlier stage guard-rail KPIs. For instance, in addition to Average Revenue Per User (ARPU), it is recommended to incorporate Average Added Basket Value Per User (AABVPU). When conducting an experiment, if you observe a substantial disparity between these two KPIs, it may indicate an issue with assignment persistence. In such cases, making decisions solely based on the ARPU metric should be avoided without further investigation.
In closing, it’s important to emphasize that, in light of the potentially devastating consequences if rash business decisions are made on the back of faulty A/B testing, we concede that this approach doesn’t offer a foolproof solution to our challenges as well. We must navigate within the constraints of our imperfect world.
Apendix
All code needed to reproduce the simulations used can be found in this gist.
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.