searchHub partners with unconventional ecommerce consultants foryouandyourcustomers
foryouandyourcustomers is a unique commerce consultancy, placing art at the foundation of business change, and the ensuing technological innovation.
Their unconventional methods bring renewed, artistic, emphasis to change management, grounded in a holistic methodology they call the “Exploded View”. This model forms the groundwork for consultation, design, implementation and support of businesses large and small.
Jonathan Möller – illustrating the Exploded View
foryouandyourcustomers view the human experience, whether as customer, channel owner and operator, part of an organization, part of a process, system, or data ingester as paramount for brands’ fiscal success. This twist in focus, challenges our modern business landscape, which is predominantly known for quick wins, and following the next best technological breakthrough. In short: it’s nothing less than revolutionary (Latin: revolvere “turn, roll back”).
searchHub, is both excited and challenged as we take a moment to celebrate our recent partnership with foryouandyourcustomers.
Together, we look forward to impacting a wider audience with:
Strategies and solutions that seek to reduce human error, operational complexity, and erroneous cost in our area of onsite search optimization.
Facilitating space within mundane tasks, for humans to shape their business environment as artisans, and not mere operators.
A more honest interaction with customers, leading to higher purchase levels and increasing customer lifetime value.
In the words of foryouandyourcustomers
“searchHub provides tools that solve how to increase onsite search efficiencies, at lower costs, while making happier end customers.”
– Jens Plattfaut – CEO – FYAYC Munich
“searchHub complements our business approach on a practical level: they provide tools that solve how to increase onsite search efficiencies, at lower costs, while making happier end customers. Through automated processes within searchHub, they’re able to minimize learning curves and cost. This means, additional creative space for both employees and customers.” – Jens Plattfaut – CEO – foryouandyourcustomers Munich
In the words of searchHub:
“FYAYC ensures the highest value of onsite search for their customers, no matter the vendor. That’s our business model, and foryouandyourcustomers transport this value, elegantly.”
– Mathias Duda – Co-Founder & CSO – searchHub
“foryouandyourcustomers, understand onsite search and how finicky optimization can be. They understand that changing search vendors is not an economical solution. They want to ensure the highest value of their customer’s onsite search, no matter the vendor. That’s our business model, and foryouandyourcustomers transport this value, elegantly.” – Mathias Duda – Co-Founder & CSO – searchHub
At foryouandyourcustomers, we support businesses with expertise in all matters of digital change.
We create excellent customer experiences. With proven methodologies, we support organizations in strengthening their customer-centric mindset and realizing customer experiences that work. We understand customer and business needs, design digital experiences and accompany the technical realization of digital channels.
Customer Centricity / Customer Experience Design / Digital Channels / Strategy / User Research / UX/UI / Organizational Development / Implementation Companionship
Berlin, 20. Juni 2023 – Die CXP Commerce Experts GmbH, ein aufstrebendes Pforzheimer IT Start-up, hat mit ihrem innovativen Produkt searchHub.io auf dem diesjährigen K5 Event in Berlin den Commerce Award im Bereich Search & Marketing gewonnen.
Die K5 E-Commerce Veranstaltung, eine der bedeutendsten Konferenzen in der digitalen Handelsbranche, versammelte führende Experten, Investoren und Unternehmen aus der ganzen Welt. In diesem Rahmen gewann die CXP Commerce Experts GmbH mit ihrer Lösung, searchHub.io, eine Revolution im Bereich der Suche und des Marketings im E-Commerce.
searchHub.io, das Add-on für jede Site-Search Lösung von CXP Commerce Experts GmbH, zeichnet sich durch eine herausragende automatisierte Optimierung einer jeden Suchtechnologie aus. Dieses ermöglicht es Online-Händlern, die Kundenerfahrung zu optimieren und gleichzeitig ihre Umsätze zu steigern, ohne ihre gegenwärtige Site-Search Lösung ersetzen zu müssen.
Die searchHub.io Algorithmen analysieren das Benutzerverhalten, die Produktdaten und die Trends eines E-Commerce-Shops, um hochrelevante Suchkorrekturen in Echtzeit zu machen. Dadurch werden Kunden bei ihrer Produktsuche mit präzisen und personalisierten Ergebnissen unterstützt, was zu einer erhöhten Kundenzufriedenheit und einer verbesserten Konversionsrate führt.
Die Auszeichnung mit dem K5 Award für Search & Marketing bestätigt das enorme Potenzial von searchHub.io, das von der hochkarätigen Jury als wegweisende Lösung im E-Commerce anerkannt wurde.
Die Jury besteht aus angesehenen Branchenexperten, Technologieinnovatoren und erfolgreichen Unternehmern, die die vielversprechendsten Produkte und Dienstleistungen im Bereich E-Commerce bewerten.
Foto: Erich Althaus – Siegfried Schüle (CEO) und Markus Kehrer (Head of Sales) von searchHub.io nehmen die K5 Auszeichnung entgegen.
“Wir sind überwältigt und stolz darauf, den renommierten K5 Award für Search & Marketing gewonnen zu haben”, sagte Siegfried Schüle, CEO von CXP Commerce Experts GmbH. “Diese Auszeichnung ist eine Bestätigung unserer harten Arbeit und unseres Engagements, bahnbrechende Lösungen für die Herausforderungen im E-Commerce zu entwickeln. Wir sind fest davon überzeugt, dass searchHub.io den Online-Händlern dabei hilft, ihre Such- und Marketingstrategien auf ein neues Level zu heben und ihren Kunden ein erstklassiges Einkaufserlebnis zu bieten.”
CXP Commerce Experts GmbH hoffe mithilfe der Auszeichnung für Search & Marketing auf der K5 E-Commerce Veranstaltung neue Geschäftsmöglichkeiten und Partnerschaften zu erschließen. Darüber hinaus ihre Position als führender Anbieter von E-Commerce-Lösungen weiter auszubauen.
Über CXP Commerce Experts GmbH:
Datengetrieben und hoch-automatisiert das Kunden-Sucherlebnis und die Suchqualität verbessern – dafür steht CXP. Die langjährige E-Commerce-Erfahrung im Bereich der Suchtechnologien (u.a. bei FactFinder, Fredhopper, Attraqt, Elasticsearch, SolR) macht CXP zu Ihrem idealen Partner für eine effektive On-Site Suchstrategie.
In the world of online shopping, customers often start their search with a product’s brand name. For ecommerce retailers, it is essential to lead this “brand search” traffic to a dedicated landing page that highlights the associated products and provides a seamless user experience.
Site search is an essential aspect of ecommerce, especially on mobile devices, where customers may prefer to search for products rather than browsing through multiple pages. But retailers, and their ecommerce directors, are strapped for time and resources. It’s no wonder that Baymard Institute, found 70% of ecommerce sites fail to provide a satisfactory search experience. So if you’re looking for just one thing to change about your site search, how about optimizing brand searches? Imagine the customer experience improvement and increased likelihood of conversions simply by optimizing brand searches within your site search. Baymard goes on to discuss the importance of testing and measuring the effectiveness of site search to continuously improve it. We may all have heard it a thousand times over, after all, site search optimization is not a new topic. And, even still, shops are failing at this elusive task. Thankfully, Baymard continues to beat the drum, driving us all to a more focussed and mature understanding of what brings the greatest gains in online retail optimization.
It’s safe to say that the road to measurable customer journey optimization and employee resource allocation is achieved by clearly understanding both how customers use your webshop, and secondly, how to improve their journey, today.
Site Search – Understand How Customers Interact with Your Shop
How do you efficiently get a better picture of site search resources (tech and employee time spent) to make better decisions regarding which optimizations need to be prioritized and identify any missing functionality
Site Search Performance Measurement
Number one: Can you accurately measure your site search performance? Onsite search is notoriously broken. Retailers continuously optimize site search issues that don’t bring the expected return. This is largely due to the proliferation of Google Analytics. A cheap tracking and analytics solution that comes at the cost of accurate insight. This is no fault of its own. GA does not purport to be the ideal solution for onsite search tracking and analytics. But that doesn’t keep retailers from treating it that way.
Imagine a way to track onsite search customer journeys without sessions being lost or unable to rationalize search revenues as a result of filters being set, customers using the browser “back” button, or an onsite campaign being triggered. This type of solid, no-nonsense site search tracking technology is the backbone behind searchHub’s search optimization success. This search tracking solution is one-of-a-kind and allows us to track customer search journeys throughout sessions and no matter the underlying site search technology being used.
Site Search – Improve the Customer Journey!
Number two: can you pinpoint what needs to be optimized in your customer’s site search journey and improve it now?
Ecommerce retailers are prepared to optimize anything they can measure. This makes it easy to articulate a business case. But cleanly tracking search, throughout the customer journey, has always been an issue. This increases the challenge of creating a seamless and efficient search experience for customers.
So, now imagine you have a system in place that makes it easy to identify which site search optimizations will provide the greatest uplift in customer satisfaction, based upon how they interact with your webshop. A solution that tells you what to optimize next, no matter the underlying site search technology you use, and provides the tools you need to make the necessary changes now!
That’s searchHub.
Thinking Outside the Search Box
So, let’s assume you’re using searchHub. What types of KPIs would you begin optimizing straight out of the gate? You might be surprised: there are a few aspects of the customer journey which are directly influenced by site search, but not often associated with it.
The following is a short list of where to begin creating a better customer journey by leveraging searchHub to optimize your existing site search.
1. Optimize your site search for brand terms
To ensure that your brand search traffic leads to specifically curated landing pages, you first need to ensure that your site search can handle different variations (e.g. adidas, adadis, addidas, addias, adiddas etc.) of brand names, including misspellings, abbreviations, and different word orders. Additionally, consider adding predictive search suggestions and autocomplete functionality to make it easier for customers to find the brands they’re looking for.
2. Create dedicated landing pages for brand searches
This second point builds on the previous one. Your search can handle any misspelling or variation of the brands in your catalog? Now, the hard work of ensuring a seamless user experience, by creating a dedicated landing page for brand searches, ensues. Landing pages showcase a brand’s products and provide customers with an easy-to-use filtering system that allows them to narrow down their search results. Make sure to include relevant information such as product reviews, ratings, and pricing to help customers make informed purchase decisions.
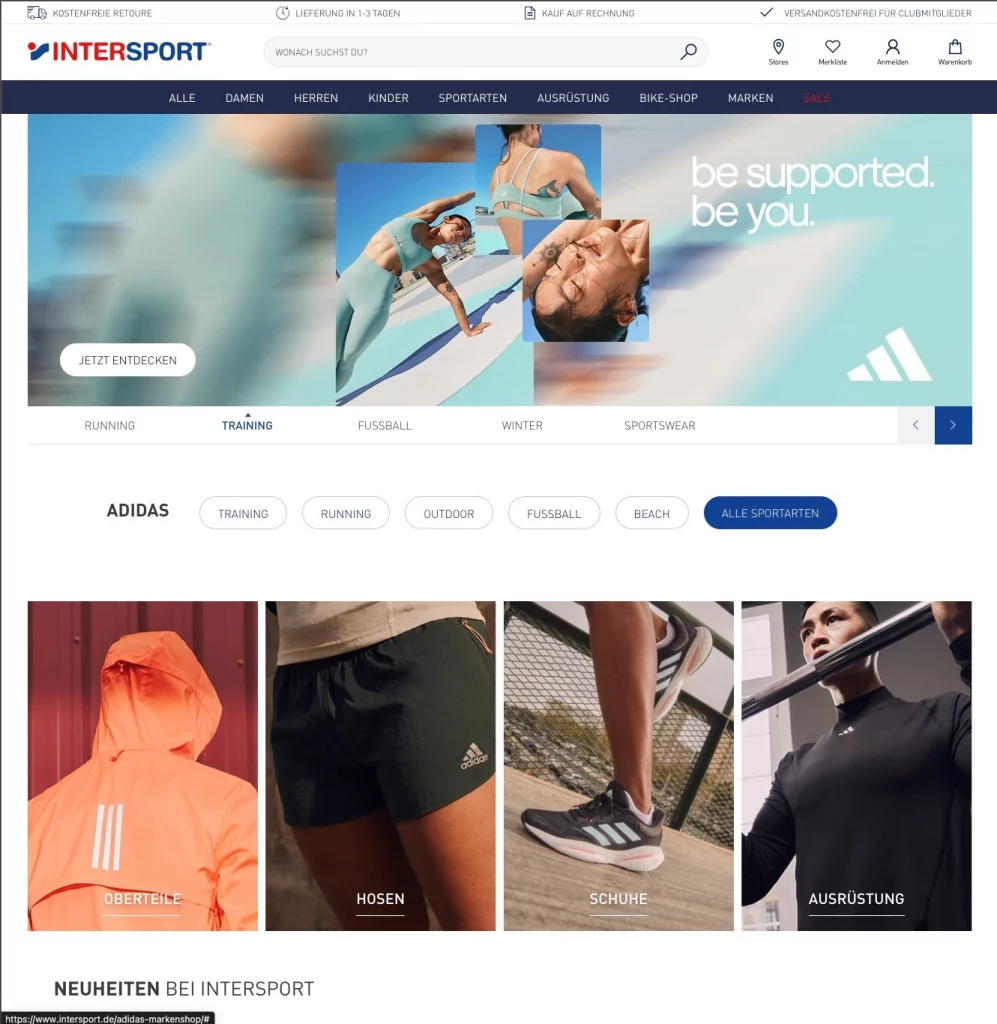
Intersport Adidas Brand Landing Page
3. Optimize Suggest for Brand Searches
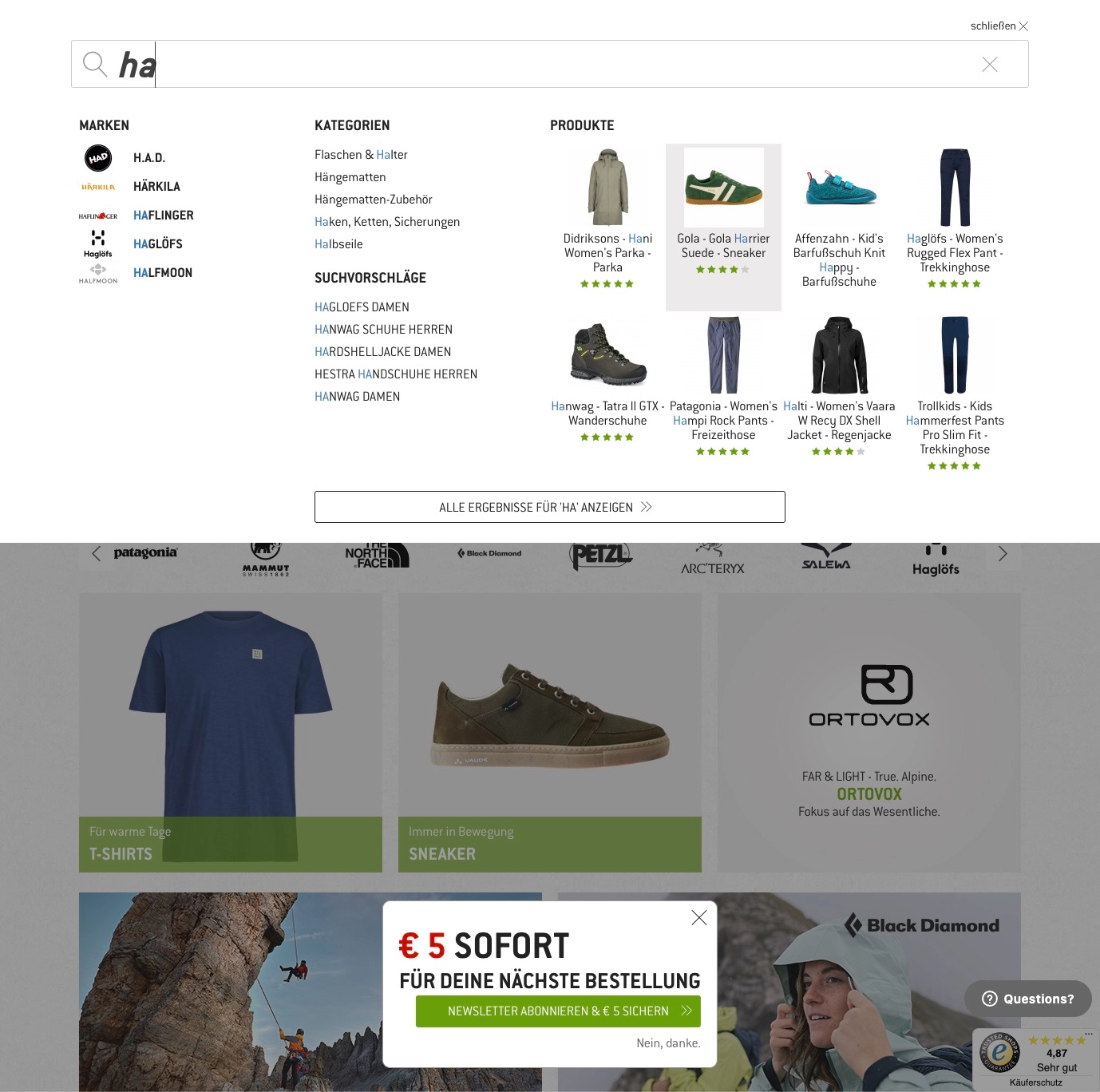
The autocomplete functionality your search engine provides, is often the first interaction customers have with the brands in your shop. Making these visible as early as possible in the customer journey increases the overall shop usability. Retailers can use smartSuggest to train the search algorithm to prioritize brand-related search terms and suggest relevant products. This can be achieved by tagging and categorizing products by brand, and using this information to inform the smartSuggest algorithm. Additionally, retailers can monitor the performance of the smartSuggest feature, using searchInsights, and over time and make adjustments to optimize its performance.
Bergfreunde – Brand placement in smartSuggest.
4. Use retail media ads in site search
Retail media is a form of advertising that allows brands to promote their products on the websites of retailers or marketplaces. By using retail media ads in site search, brands can increase their visibility and drive more conversions. Target the right audience, use relevant keywords, and track the performance of retail media ads to optimize them over time.
Criteo – correct Retail Media placement in a webshop.
5. Use data to personalize the user experience
searchHub’s searchCollector provides a host of search behavior data, giving granular insight into how customers interact with search throughout their journey. What has been placed into, and then removed from, the basket? Which products have been seen but not clicked? Which products bring the most revenue, compared to those with the greatest profit? This anonymous information, tracked no matter the underlying site search technology, provides the ability to personalize search results and suggest relevant products that match customer interests. Not only will this improve the user experience, but also increase the likelihood of conversions.
Conclusion
Unlocking site search potential requires a strategic approach that focuses on customer needs and behavior. Begin by optimizing site search for brand terms, create a dedicated landing page, optimize smartSuggest, use retail media ads in site search, and personalize the user experience using data. By implementing these strategies, ecommerce sites can create a personalized brand experience for their customers, showcase their products effectively, and ultimately drive revenue.
Site Search Transformation through Efficiency, flexibility, and transparency!
Have you ever been overwhelmed by the amount of effort it takes to optimize your ecommerce site search? What if your business could improve its site search with an AI built to optimize it, not replace what you already have? Imagine a tool that can enhance the user experience by providing an efficient and user-friendly search. This is where searchHub.io comes in.
Efficient
With searchHub’s AI-driven approach, businesses can improve their site search regardless of their existing solution. searchHub’s AI-powered algorithms translate user phrases into the best possible search query, leading to higher conversion rates and a better user experience. Additionally, the tool provides an in-depth representation of all search activities, helping businesses efficiently improve their search experience.
Flexible
Flexibility is another critical aspect of searchHub.io. It can be integrated with any site search solution, saving time and resources while allowing businesses to customize their search experience according to their specific needs.
Transparent
Transparency is also a key feature of searchHub. The tool provides businesses with a unique view of their search data, allowing them to identify trends and understand customer behavior. Businesses that understand their customers’ needs and preferences are more likely to succeed in today’s competitive e-commerce market.
Furthermore, searchHub is the only add-on-solution on the market that can be appended to your current site search in a short amount of time, making it an excellent choice for large-scale e-commerce sites. Speed and agility are critical for large-scale e-commerce sites to stay competitive.
“Our site search is built on Elasticsearch. B2B is known for its challenges, for which there are no standard vendor solutions. searchHub delivers the desired added value to our setup using transparently delivered data.”
Michael Kriz
Automated
This type of automation is key for a modern site search strategy, and here’s why: Imagine the volume of search data generated by online shopping, which is increasing rapidly. It can be challenging for site search teams to analyze and interpret all the information efficiently. By implementing automation within their site search environment, businesses can streamline their operations and reduce the workload on human teams. This frees up time for innovation and experimentation, allowing businesses to focus on more strategic tasks.
“searchHub makes it easier for us to guide customers through our assortment. We control our search solution even better because of intelligent long-tail clustering. We now have less effort to maintain our merchandising campaigns, and the search analytics are more transparent. The value per session increased, ad-hoc, by more than 20%.”
Dominik Brackmann
Conclusion
In conclusion, searchHub.io is a unique tool that helps businesses enhance their site search experience independently of their existing solution. Its focus on efficiency, flexibility, and transparency makes it a valuable addition to any e-commerce business looking to increase conversion rates and improve the user experience. Its AI-powered algorithms and data-driven approach provide businesses with unique insights into their search data, helping them to optimize their site search and keep up with customer preferences. By investing in searchHub, e-commerce businesses can stay flexible and innovative, making it a must-have for any modern e-commerce strategy.
The trend towards automation and AI-powered tools in site search is likely to continue, as businesses seek to streamline their operations and focus on more strategic tasks.
wir freuen uns sehr, Dir die Einführung einer revolutionären neuen Methode zur Ermittlung des besten Suchbegriffs ankündigen zu können. In dieser Post möchten wir Dir die neuen Funktionen vorstellen und zeigen, wie sie Dein tägliches Arbeiten noch zielführender machen.
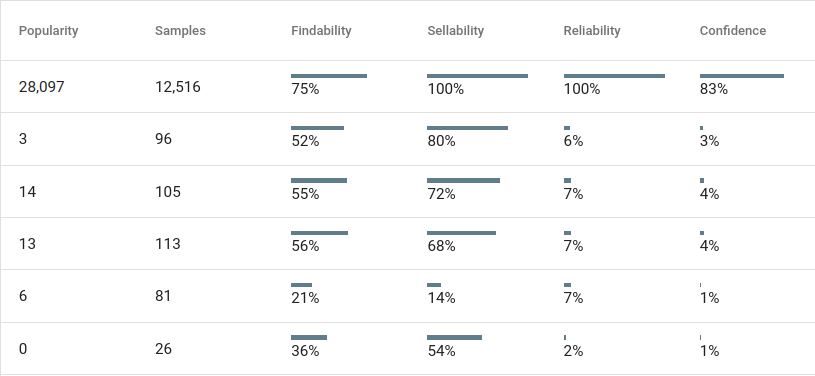
Bisher wurde der repräsentativste Suchbegriff innerhalb eines Varianten-Clusters vor allem anhand der KPIs CTR (Klickrate) und CR (Kaufrate) ermittelt. Mit unserer neuen „Best Query Picking-Technology“, haben unsere Kunden die searchCollector integriert haben zwei neue KPIs, über die sie sich freuen dürfen: Findability und Sellability.
„Findability“ ist ein KPI, der positives und negatives Nutzerfeedback, wie Klicks und Views, aber auch zusätzliche Informationen wie nicht geklickte Produkte, zu viele Filter, und Seitenausstiege berücksichtigt. „Sellability“ hingegen misst alle angeklickten Produkte, die in den Warenkorb gelegt oder gekauft worden sind. Diese einzigartige Kombination von KPIs stellt sicher, dass für jedes Suchbegriffscluster die leistungsfähigste, beste Schreibweise ausgewählt wird. Auf dieser Weise wird transparent, welchen Einfluss die Relevanz eines Suchergebnisses auf das Kaufverhalten der Nutzer hat.
Maximale Transparenz ist uns wichtig. Deswegen haben wir die KPI „Reliability” eingeführt. Diese misst, wie zuverlässig die KPIs der Vergangenheit für eine bestimmte Suchbegriffs-Variante sind. Dies geschieht, indem wir Varianten mit aktuelleren Daten höher gewichten als Varianten, zu denen es ggf. schon seit längerer Zeit keine neuen Daten gibt.
Zwei weitere neue KPIs in der Benutzeroberfläche werden Dir sicher auch noch auffallen: “Popularity” und „Sample Size“. Die Popularity misst, wie oft in den vergangenen 28 Tagen ein Suchbegriff gesucht wurde. Die Sample Size ist die Häufigkeit der ungemappten Suchen, die wir aus verschiedenen Zeiträumen erfasst haben. Alle restlichen KPIs beziehen sich auf diese Häufigkeit.
Diese Änderungen werden sich auf die Cluster-Ansicht auswirken, die genau angibt, welche Cluster und Varianten zusammengehören und warum. Es ist wichtig zu beachten, dass die Cluster-Ansicht keine Analyse ist, sondern vielmehr eine Steuerungszentrale, um die Qualität der Suchergebnisse zu beeinflussen. searchHub gibt Dir hier volle Kontrolle über Suchbegriffsbeziehungen.
Für Kunden, die unsere searchInsights abonnieren, geht eine detaillierte Analyse der Suchmaschinen-Performance leicht von der Hand. Hast Du schon den neuen Date-Picker oder die Vergleichsmöglichkeit entdeckt?
Hast Du noch keine searchInsights und bist auf der Suche nach einer detaillierteren Analyse der Suchmaschinen-Performance, mit granularem, beispiellosem Suchmaschinen-Tracking, solltest Du Dir unser Modul searchInsights anschauen. Dies ist das optimale Vorgehen, um Deine Suchmaschine in ein Business-Tool zu verwandeln.
Wir hoffen, Du bist von diesen Änderungen genauso begeistert wie wir. Diese werden am 15. März im searchHub UI sichtbar sein. Vielen Dank für Dein Vertrauen in searchHub!
Beste Grüße Dein searchHub Team
English Version
The New Standard for Search Optimization
We are thrilled to announce the launch of our revolutionary new way to identify the most representative search term for a given query cluster. Today, we’re sharing these exciting new features and how they benefit your business.
Traditionally, identifying the most representative query within a query cluster was done using the KPIs CTR and CR. Now, we’re doing something different. For our customers using our searchCollector, our Query Picking Technology, introduces two new KPIs: Findability and Sellability.
“Findability” is a KPI that measures positive and negative user feedback, such as clicks and views, but also considers products that aren’t clicked. “Sellability”, on the other hand, measures all clicked products, which are either added to the basket or purchased. This unique combination, ensures the highest performing, best query, is picked for each query cluster.
Additionally, we are introducing a new KPI called “Reliability”, which measures how representative past KPIs are for a given keyword variant, within a cluster. This ensures the best performing query is always chosen over any period. We do this by weighting recent keyword data (interactions) higher than older keyword data. Surely, you won’t miss two additional new KPIs in the UI: “Popularity” and “Sample Size”. Popularity measures how often a query was searched in the last 28 days. The “Sample Size” is the frequency of the unmapped queries, which we gathered across different time periods. All other KPIs build on the search term frequency that comes from “Sample Size”. These changes will affect the query cluster view, and more precisely communicate which clusters and variants belong together and why. It’s important to note that the Query Cluster view is not an analysis, but rather a command center to influence the search result quality. searchHub allows you the complete control.
For our customers, already subscribing to our searchInsights module: you already have the most detailed analysis possible of search engine performance. Have you discovered the Date-Picker and comparison functions yet?
If you’re not yet using searchInsights, but you’re looking for a more detailed analysis of your search engine performance, with granular, unparalleled search engine tracking, please consider adding our searchInsights to your current searchHub subscription. This is the way to go if you’re looking for a way to turn your search engine into a business tool.
We hope you’re as excited about these changes as we are. They’ll be live in the searchHub UI on March 15th. Thank you for your trust in searchHub. Best regards,
In 2017 we officially launched searchhub.io. Now 5 years later, it’s time for a recap and some updates regarding our goals, strategy, and product.
Has the Search Game Changed?
Maybe in scale, but certainly not in terms of goals and purpose. Search Engines still act as filters for the wealth of information available on the Internet. They allow users to quickly and easily find information that is of genuine interest or value to them, without the need to wade through numerous irrelevant web pages. However, they are built based on concepts that store words or vectors and not their meaning. Screen real estate is going to zero, and the way people can interact with digital systems has evolved from keyboard only to keyboard, voice, images, and gestures. All of these input types are error-prone and don’t include context. A well done site search, however, should cater to these errors and automatically add available context to come up with relevant answers.
Therefore, our motivation hasn’t changed. In fact, we are now even more convinced that there is an almost endless need and opportunity for Fast & Relevant search.
Our motivation “FAST & RELEVANT SEARCH” helps to craft meaningful search experiences for the people around us, this mission inspires us to jump out of bed each day and guides every aspect of what we do.
Was Our Entirely New Approach with searchHub.io a Success?
1. It Works Site Search Platform Independent…
…definitely yes. We still see a growing set of different search engines out there, and all of them have their pros and cons. Often the reason a specific search engine was chosen has nothing to do with the ability to successfully fulfill the basic use case of search. In more complex scenarios, there could even be a set of different search engines in production, each fulfilling a different use case. That’s why we designed searchHub as a platform independent proxy that automatically enhances existing site search engines by autocorrecting, aligning human input and building context around every search query in a way your search engine understands.
2. Enhance, Not Replace
…absolutely yes. Search Engines are becoming an even more integral part of modern system backbones and are in most cases very hard to replace. But “search” as we know it is already changing because modern technology has set today’s customers very high expectations; they know what they want, and they want it now. More and more retailers have started investing in their own, business-case adapted, Search & Discovery Platforms. And they continue to add new in-house features like LTR (Learning-to-Rank), personalization, and searchandising more frequently than ever before.
Therefore, we decided early on that we are not aiming to replace these platforms and instead focus on how we can enable our customers to achieve even better results with what they have now or in the future at scale. That’s precisely why the technology behind searchHub was specifically designed to enhance our customers’ existing site search, not replace it. The primary component is still our Lambda-Architecture that enables us and our customers to separate model training from model serving.
3. The Lambda-Architecture Choice
This architecture gives our customers the freedom to deploy our smartQuery Serving-Layer wherever they want, reducing latencies to the bare minimum (<1ms 99.5 conf interval) as there is no additional internet-latency. While it gives us the freedom to entirely focus on efficiently building & training the best available ML-Models consumed by the Serving-layers asynchronously. This freedom to deploy and operate such a thin client is one of the most appreciated features of searchHub and one key reason for our short integration times.
This architecture also enables our users to modify these models and deploy them to production without any IT-involvement on their end. Giving Relevance-Engineers, Data-Scientists and Search-Managers almost instant influence and optimization capabilities for their search & discovery platform.
4. AI-Powered Search Query Rewriting Is The Best Starting Point…
Again yes. Of course, at first glance we could have focused on more “fancy” areas of search, but the initial focus on thoroughly understanding the user-query was one of the best decisions we made. Why? Because you can’t control your users’ queries – they express their intent in their terms – and there is nothing you can do about it. Matching users’ intent to your document inventory is the key part of every search process. Therefore, it just felt natural to start here, even though it’s the most challenging part.
Once we had a solution to this problem in place, we were shocked at the additional benefits and opportunities that surfaced. The sparsity in behavioral data is automatically reduced, it removes 1000s of hours of manual curation and optimization whilst enabling more stable and consistent results. That’s why we are still investing significant effort into furthering this part of the platform, as every minor improvement here compounds up to the different down-stream tasks.
This year we will have processed over 25 billion searches resulting in almost 750 Million unique search phrases across 13 languages, empowering our customers to generate well over 5 billion € in GMV (Gross Merchandise Volume). All of that with a purposefully, minimal, highly skilled Dev and Dev-ops Team.
Time To Update You On Our Journey So Far
1. From Ok Data To Great Data
Since we work mainly with behavioral data, we depend heavily on the quality of their sources. Whilst almost everybody out there thinks that systems like Google Analytics, Adobe Analytics and others should be perfect sources, we learned the hard way that this is absolutely not the case. Therefore, we had no other choice as to build our own Analytics Stack (a combination of our searchCollector and searchInsights). At the beginning it was tough to convince our customers or potential customers that they needed it, but as soon as we were able to show them the difference, they directly fell in love. Being able to accurately track your search & discovery features, and getting direct feedback for potential improvements in consolidated views, not only gave our customers a 3-fold increase in operational efficiency but also dramatically improved the results delivered by searchHub.
2. Reducing The Noise From Search-Suggestions
Another area where we had to act were search-suggestions. We again assumed that state-of-the-art systems should have already solved the search-suggestions use case, but it turned out they did not. To correctly understand user intent, you first have to intercept it. However, a lot of search-suggestion systems negatively influenced user search behavior and there was nothing we could do about it. That’s why we built smartSuggest, and again it turned out to be a massive success. Not only does it handle the usual use case in a more efficient, consistent and less error-prone way, it also enables our searchHub users to instantly influence suggest behavior in terms of results and ranking again without any internal IT involvement.
3. The Bumpy Road To Transparency And Simplicity
Although our intent-clustering is very, very precise, it was always a black-box for customers and searchHub-users. For one, they wanted to, at least, get an idea about what’s going on under the hood. And secondly, they wanted to directly incorporate their expertise into the system. Everybody involved in ML (Machine Learning) is aware of how complex it is to explain why the systems do what they do. But we found a way by creating what we call “meta-patterns”. Things like this change was done because the engine has certain knowledge about the case, vs. this change was implicitly learned by observing this particular behavior. We now tag every change in the clustering pipeline with one or multiple of these patterns, giving our customers maximum transparency.
Additionally, we found a very efficient way for our customers to add their domain knowledge to the system without them having to take care of the little ugly details and pitfalls. We officially call this feature AI-Training, while our customers call it “Search-Tinder”. Because it follows the same basic UX principle of is there a match or not.
4. Encode It If You Can
Another colossal pile of work which was mostly done under the radar is represented by our newly introduced smartSearchData-Service, which is still in beta-status. If you frequently follow us, you might already be aware that searchHub was always limited by the quality of the underlying search platform. This means that for a given Intent-cluster we were only able to automatically pick the best available query, but we were unable to further improve the result for this query. Of course, we could have gone all-in on query-parsing (automatically building more complex search-platform dependent queries) but this would only have been possible with massive downsides for our customers and us. Chiefly among them: the implementation-effort would have exploded. But not only that, we would have limited the freedom of our users to improve their Search & Discovery platforms on their own.
That’s why we again decided for a radically different approach. While query processing is different for almost any site search platform, their underlying structure of indexable objects is not so different. So, what if we could somehow encode the needed additional information (to get better results for a given query) directly into the indexable objects without the need to dramatically change the query processing? That’s precisely what we do right now. It might not be a complete feature yet, and we may still face some real challenging problems in these areas, but the results so far are very encouraging.
Closing Comments
We as a team are really proud of what we have achieved, and we know it’s just the beginning. All of us are genuinely grateful and thankful for all our fantastic customers, users, partners, and fans out there which made all of this possible. It’s their feedback, and patronage, that keeps the wheel spinning and the lights on. Therefore, we hope that all of you are as eagerly looking forward to the next 5 years as we are.
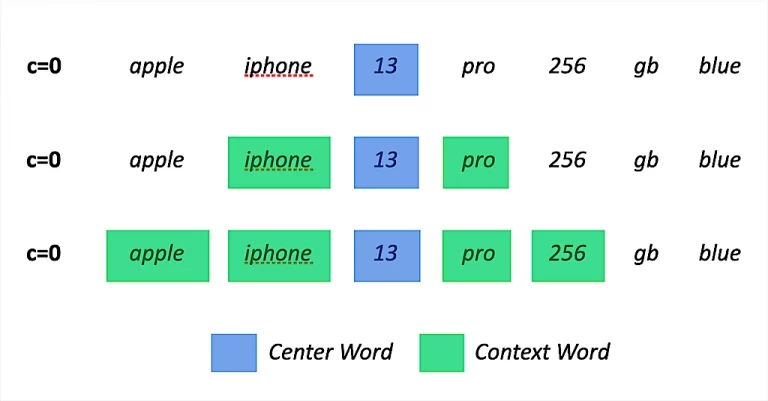
How can language models be used efficiently to scale?
Context and distance determine relevanceLanguage Models (LMs) already have quite some history, however, especially recently, a lot of effort and new approaches have flooded the “dance-floor”. While LMs have successfully been adopted to a variety of different areas and tasks the main purpose of an LM, at least in my understanding remains the same:
“Language Models are simply models that assign probabilities to a sequence of words or tokens”
Even if modern LMs can offer way more than that, let’s use the above definition or description as a foundation for the rest of this blog post.
Language Models – Some background
For quite some time N-Gram Language models dominated the research field (roughly from 1940-1980) before RNNs followed by LSTMs (around 1990) until the first Neural Language Model in 2003 received more and more hype. Then in 2013 Word2Vec, and 2014 Glove introduced “more Context” to the game. In 2015 the Attention Model became popular and finally in 2017, Transformer, which mainly built on the idea of Attention, ultimately became the de facto standard.
Today Transformers in combination with pre-trained Language Models dominate the research field and deliver groundbreaking results from time to time. Especially, when considering multi-modal modeling – (combination of text, images, videos and speech). Transformer models get most of their generalization power from these pre-trained LMs, meaning their expected quality heavily depends on them.
The technical details of these approaches are clearly out of scope for this post. However, I encourage you to take some time to familiarize yourself with the basic concepts found here.
For us as a company the most important question we try to answer when reviewing new approaches or technologies is not just if the new stuff is better, in some sort of metric or maybe completely. We’ll always try to focus on the “why” (why is there a difference) and what part of the new approach or technology is the reason for this significant difference. Ultimately, we want to pick the right tool for the given task.
The Why
When we did this internal review we tried to climb up the ladder starting with the older but most understood, highly efficient N-Gram models and nail-down the main differences (boost factors) of the newer approaches.
Type
Key Differentiator
Explanation
Word2Vec
Context
Context encoded into a vector
Transformer
Self Attention
As the model processes each word (each position in the input sequence) self attention allows it to look at other positions in the input sequence for clues that can help lead to a better encoding for this word.
Concluding the review we were quite surprised to only have spotted two real differentiators, despite the amount of training data they were trained on: Context and Attention.
Efficiency of Language Models
Undeniably, the new kids on the block have some very impressive uplifts in terms of the evaluation metrics. However, the approaches that make use of the Context and Attention concepts, have seen even greater impacts on the computational efficiency of their models, due to the dramatic increase of the amount and complexity of computations.
Granted, business cases conceivably do exist, where the uplift outweighs the computational loss in efficiency, however, none of our customers presented such a case. Even using the most distilled new generation Model we were unable to cut the cost per query to less than 100x times the current cost.
And here are the main reasons why:
Short text. We specialize in search queries. The majority of which are still quite short – 57% of all queries in our dataset are single-word queries, > 72% are two words or less. Therefore, the advantage of contextualized embeddings may be limited.
Low-resource languages. Even shops receiving the majority of their traffic on English domains, typically have smaller shops in low resource languages which also must be handled.
Data sparsity. Search sparsity, coupled with vertical specific jargons and the usual long tail of search queries, makes data-hungry models unlikely to succeed for most shops.
For a Startup like ours, efficiency and customer adoption-rate remain the central aspects when it comes to technical decisions. That’s why we came to the following conclusion:
For all of our high throughput use-cases, like sequence validation, and Information Entropy optimization, we needed significantly more efficient LMs (than the current state-of-the-art models) that still offer some sort of context and attention.
For our low throughput use-cases with high potential impact we might use the Transformer based approaches.
Sequence Validation and Information Entropy Optimization
If you work in Information Retrieval (IR) you are aware of what is called “the vocabulary mismatch problem”. Essentially, this means that the queries your users search for are not necessarily contained within your document index. We have covered this problem several times in our blog as it’s by far the most challenging IR topic of which we are aware. In the context of LMs, however, the main question is how they can help reduce “vocabulary mismatch” in a scalable and efficient way.
We structure our stack in such a way that the intent clustering stage already handles things like tokenization, misspellings, token relaxation, word segmentation and morphological transformations. This is where we try to cluster together as candidates, all user queries that essentially have the same meaning or intent. Thereafter, a lot of downstream tasks are executed like the NER-Service, SmartSuggest, Search Insights, etc.
One of the most important aspects of this part of the stack is what we call sequence validation, and information entropy optimization.
Sequence validation. The main job of our Sequence validation is to assign a likelihood to a given query, phrase or word. Where a sequence with a likelihood of 0 would represent an invalid sequence even if its sub-tokens are valid on their own.Example: While all tokens/words of this query (samsung iphone 21s) might be valid on their own, the whole phrase is definitely not.
Information entropy optimization, however, has a different goal. Imagine you have a bag of queries with the same intent. This set of queries will include some more useful than others. Therefore the job of information entropy optimization is to weight queries containing more useful information higher than queries with less useful information. Example: Imagine a cluster with the following two queries “iphone 13 128” and “apple iphone 13 128gb”. It should be clear that the second query contains much more identifiable information, like the brand and the storage capacity.
Towards an Efficient Language Model for Sequence Validation and Information Entropy Optimization
Coming back to the WHY. During the evaluation we discovered that Context and Attention are the main concepts responsible for the improved metrics between language models. Therefore, we set out to understand in more detail how these concepts have been implemented, and if we might be able to add their conceptual ideas more efficiently, albeit less exactly, to a classical N-Gram Model.
If you are not aware of how N-Gram Language models work, I encourage you to educate yourself here in detail. From a high level, building an N-Gram LM requires parsing a text corpus into equal amounts of tokens (N-Grams) and counting them. These counts are then used to calculate the conditional probabilities of subsequential tokens and/or N-grams. This chaining of conditional probabilities enables you to compute further probabilities for longer token chains like phrases or passages.
Despite the ability of an N-Gram model to use limited context it is, unfortunately, unable to apply the contextual information contained in the tokens, which make up the n-grams, to a larger contextual framework. This limitation led to our first area of focus. We set out to define a way to improve the N-Gram model by being able to add this kind of additional contextual information to it. There are two different approaches to achieve this:
Increase corpus size or
Try to extract more information from the given corpus
Increasing the corpus size in an unbiased way is complicated and also less effective computationally. As a result, we tried the second approach by adding one of the core ideas of Word2Vec – the skipGrams – taking into account a larger contextual window. From a computational perspective the main operation for an N-Gram-model is counting tokens or n-Grams. Counting objects is one of the most efficient operations you can think of.
However, trying to get decent results makes it obvious that simply counting the additionally generated skipGrams as is, does not work. We needed to find some sort of weighted counting scheme. The problem of counting these skipGrams in the right way, or more specifically assigning the right weightings, is somehow related to the Attention mechanism in Transformers.
In the end we came up with a pretty radical idea, unsure of whether it would work or not, but the implied boost in computational efficiency and the superior interpretability of the model gave us enough courage to nevertheless try.
Additionally, we should mention that all of our core services are written purely in java. This mainly has efficiency and adoption reasons. We were unable to find any efficient Transformer based native java implementation enabling our use cases. This was another reason for us to try other approaches to solve our use-case rather than just plugging in additional external libraries and technologies.
Introducing the Pruned Weighted Contextual N-Gram Model
The main idea behind the pruned, weighted, contextual N-Gram Model is that we expand the functionality of the model to weight co-occurring n-Grams respective of context and type and, in the final stage, prune the N-Gram’s counts.
Weighted Contextual N-Gram Counting
To visualize the idea and approach let’s use a typical ecommerce example. Imagine you have a corpus containing the following passage. “bra no wire with cotton cup b 100”.
N-Gram Generation
From here we would create the following unigrams, bigrams and skipGrams. (Where the skipGrams get deduplicated with the bigrams and we’ll use a context window of 5).
Set of uniGrams
[bra, no, wire, with, cotton, cup, b, 100]
Set of biGrams
[bra no, no wire, wire with, with cotton, cotton cup, cup b, b 100]
Set of skipGrams
[bra wire, bra with, bra cotton, bra cup, no with, no cotton, no cup, no b, wire cotton, wire cup, wire b, wire 100, with cup, with b, with 100, cotton b, cotton 100, cup 100]
As you can see by using SkipGrams with a defined context window we dramatically increased the number of usable biGrams for our LM. However when it comes to counting them not all of these bigrams from this passage should be considered with the same relevancy.
Weighted Contextual skipGram Generation
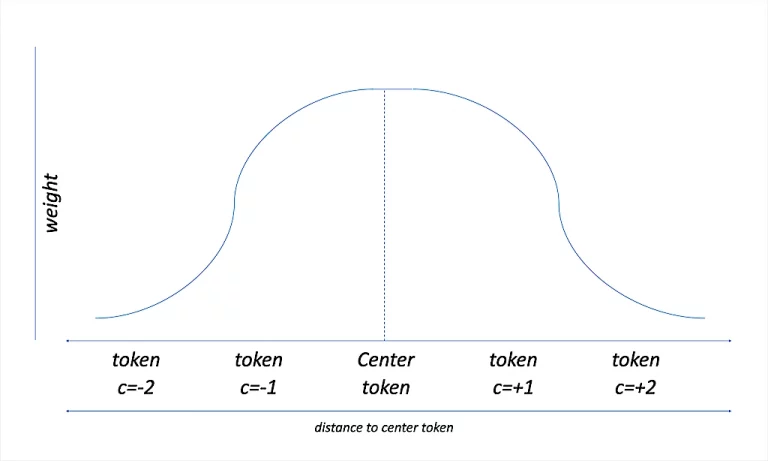
To somehow overcome this issue we introduce what we call contextual proximity weighting. During the skipGram creation we penalize the created skipGrams depending on the positional distance to the current context. An example could be that “bra wire” gets a weight of 0.75 while “bra with” gets 0.4 and “bra cotton” gets 0.2 and so on. (the more positions the skipGram skips the less weight it gets). Now instead of purely counting the occurrences we count occurrences and weights of their positional encodings.
Intermediate Result
By adding this contextual proximity weighting we were able to improve the basic n-Gram Model recall by almost 48% with only a slight 7% decrease in precision.
Conceptual Tokenization
But we wanted to go a step further and encode even more information during this stage. Language contains a lot of logic & structure. For example, in the English language the terms “no/without” and “with” are special terms. Additionally “cup b 100” is a pretty special pattern. A lot of this structure and logic is lost by tokenization most of the time, and modern systems have to learn this sort of structure again from scratch during the training process. So what if we could somehow embed this logic & structure right from the beginning in order to further improve our fine grained weighting depending on context. To verify our intuition we extracted around 100 structural or logical concepts to cope with signal-words, and numerical patterns. We apply these concepts during tokenization and flag detected concepts before they enter the N-Gram generation stage where we finally get: “bra no-wire with-cotton cup-b-100”
Set of uniGrams
[bra, no, wire, no wire, with, cotton, with cotton, cup, b, 100, cup b 100]
Set of biGrams
[bra no, no wire, wire no wire, no wire with, with cotton, cotton with cotton, with cotton cup, cup b, b 100, 100 cup b 100]
Set of skipGrams
[bra wire, bra without wire, bra with, bra cotton, without wire, without with, no cotton, no with cotton, wire with, wire cotton, wire with cotton, wire cup, without wire cotton, without wire with cotton, without wire cup, without wire b, with cotton, with cup, with b, with 100, cotton cup, cotton b, cotton 100, cotton cup b 100, with cotton b, with cotton 100, with cotton cup b 100, cup 100, cup cup b 100, b cup b 100]
From here it’s possible to further manipulate the weighting function we introduced. For example words that follow signal words get less of a weight penalty, while the words with higher positional indexes receive a greater penalty. For subsequent numeric grams, we may consider increasing the weight penalty.
Intermediate Results
By adding the contextual tokenization we were able to further reduce the decrease in precision from 7% to less than 3%. As you may have noticed, we have yet to talk about pruning. With the massive increase in the number of N-Grams to our model, we simultaneously increased the noise. It turns out we almost completely solved this problem, simply by using a simple pruning, based on the combined weighted counts, which is also very efficient in terms of computation. You could, for example, filter out all grams with a combined weighted count of less than 0.8. By adding the pruning we were able to further reduce the decrease in precision to less than 0.2%.
We also have yet to touch the Perplexity metric. Quite a lot of people are convinced that a lower perplexity will lead to better language models — the notion of “better” as measured by perplexity is itself suspect due to the questionable nature of perplexity as a metric in general. It’s important, however, to note that improvements in perplexity don’t always mean improvements in the upstream task, especially when considering small improvements. Big improvements in perplexity, however, should be taken seriously (as a rule of thumb, for language modeling, consider “small” as < 5 and “big” as > 10 points). Our pruned weighted contextual N-Gram model outperformed the standard interpolated Kneser-Ney 3-gram model by 37 points.
Training and Model building
Like many of our other approaches or attempts, this one just seemed way too simple to actually work. This simplicity makes it all the more desirable, not to mention the orders of magnitude better than anything else we could find when it comes to efficiency.
Our largest corpus currently is a German one, comprising over 43-million unique product entries, which contain about 0.5 Billion tokens. After our tokenization, ngram generation, weighted counting and pruning we ended up with 32-million unique grams with assigned probabilities which we store in the model. The whole process takes just a little under 9 minutes using a single-threaded standard Macbook pro, 2,3 GHz 8-Core Intel Core i9, without further optimizations. This means that we are able to add new elements to our corpus, add or edit conceptual tokens and/or change the weighting scheme, and work with an updated model in less than 10 minutes.
Retrieval
Building the LM-Model is just one part of the equation. Efficiently serving the model at scale is just as crucial. Since each of our currently 700-million unique search queries needs to be regularly piped through the LMs, the retrieval performance and efficiency are crucial for our business too. Due to very fast build times of the model we decided to index the LM for fast retrieval in a succinct, immutable data-structure using minimal perfect hashing for storing all the grams and their corresponding probabilities. Perfect hash is a hash which guarantees no collisions. Without collisions it’s possible to store only values (count frequencies) and not the original n-grams. Also we can use a nonlinear quantization to pack the probabilities into some lower bit representation. This does not affect the final metrics but greatly reduces memory usage.
The indexation takes around 2 minutes with the model using just a little bit more than 500mb in memory. There is still significant potential to further reduce memory footprint. For now though, we are more than happy with the memory consumption and are not looking to go the route of premature optimization.
In terms of retrieval times the Minimal Perfect Hash data structure which offers O(1) is just incredible. Even though we need several queries against the data structure to value a given phrase we can serve over 20.000 concurrent queries single-threaded on a single standard Macbook pro 2,3 GHz 8-Core Intel Core i9.
Results
All models including the 3-gram Kneser-Ney model are trained on the same corpus, a sample of our german corpus containing 50-million words for comparison. We tried BERT with the provided pretrained models but the quality was not comparable at all. Therefore we trained it from scratch in order to get a fair comparison.
Model
Accuracy
PPL
Trained On
Memory Usage
Training Time
95% / req time
Efficiency
Kneser-Ney-3-Gram
62.3%
163.0
CPU
385 mb
7 min
0.34 ms
47-Watt
Transformer
75.8%
110.5
CPU
3.7 gb
172 min
4.87 ms
3.6-kWatt
pruned weighted contextual 3-Gram Kneser-Ney
91.2%
125.7
CPU
498 mb
9 min
0.0023 ms
60-Watt
+20%
-12%
-87%
-95%
-99%
-98%
In summary we are very pleased with the results and achieved all our goals. We dramatically increased the computational efficiency whilst still not losing much in terms of quality metrics and maintaining maximum compatibility with our current tech stack.
What’s next…?
First of all we are working on documenting and open-sourcing our pruned weighted contextual N-Gram model together with some freely available corpus under our searchHub github account.
For now our proposed LM lacks one important aspect compared to current state of the art models in terms of the vocabulary mismatch problem – word semantics. While most neural models are able to capture some sort of semantics our model is not directly able to expose this type of inference in order to, for example, also properly weight synonymous tokens/terms. We are still in the process of sketching potential solutions to close this gap whilst maintaining our superior computational efficiency.
We are delighted to announce our partnership with Y1. This team of talented strategists, creators and developers has been a constant staple in the ecommerce community in Europe for over 20 years.
Working together gives us the opportunity to inject our expertise into projects where it’s most valuable – in the context of the customer journey. We look forward to expanding our range of experience as we collaborate with Y1 on projects ranging from online retail to b2b projects taking us closer to industrial manufacturing.
Y1’s expertise sits poised at the juncture where customers seek a partner at eye level, able to deliver future oriented digital solutions with innovative power and high business value. Who wouldn’t want to be a part of that? 😄
In the words of Y1
“Together with our customers, we want to be proud of all our projects.” – Y1
In our words:
We are confident in the expertise and craftsmanship of this team, and look forward to many projects we can be proud of, together! – Markus Kehrer – searchHub.io
About Y1
The agency for valuable and sustainable digital commerce projects. We are an established team of over 100 digital natives, strategists, conceptualists, creatives, and developers that all have one thing in common: we love what we do. Over 20 years. Together One. Y1.
We continually measure ourselves anew, and always strive to be a bit better by elevating our customer’s needs above our own. From the very beginning, we work to collaborate with our customers at eye-level to identify future oriented digital solutions with innovative power and a high business value. The B2C (including D2C) and B2B worlds are balanced in our portfolio of expertise, which allows us to identify and capitalize on the total market potential. Together with our customers, we want to be proud of all our projects.
How to approach search problems with Querqy and searchHub
Limits of rule based query optimization
Some time ago, I wrote how searchHub boosts onsite search query parsing with Querqy. Now, with this blog post I want to go into much more detail by introducing new problems and how to address them. To this end, I will also consider the different rewriters that come with Querqy. However, I won’t cover details already well described in the Querqy documentation. Additionally, I will illustrate where our product searchHub fits into the picture and which tools are most suited for problem solving.
First: Understanding Term-Matching
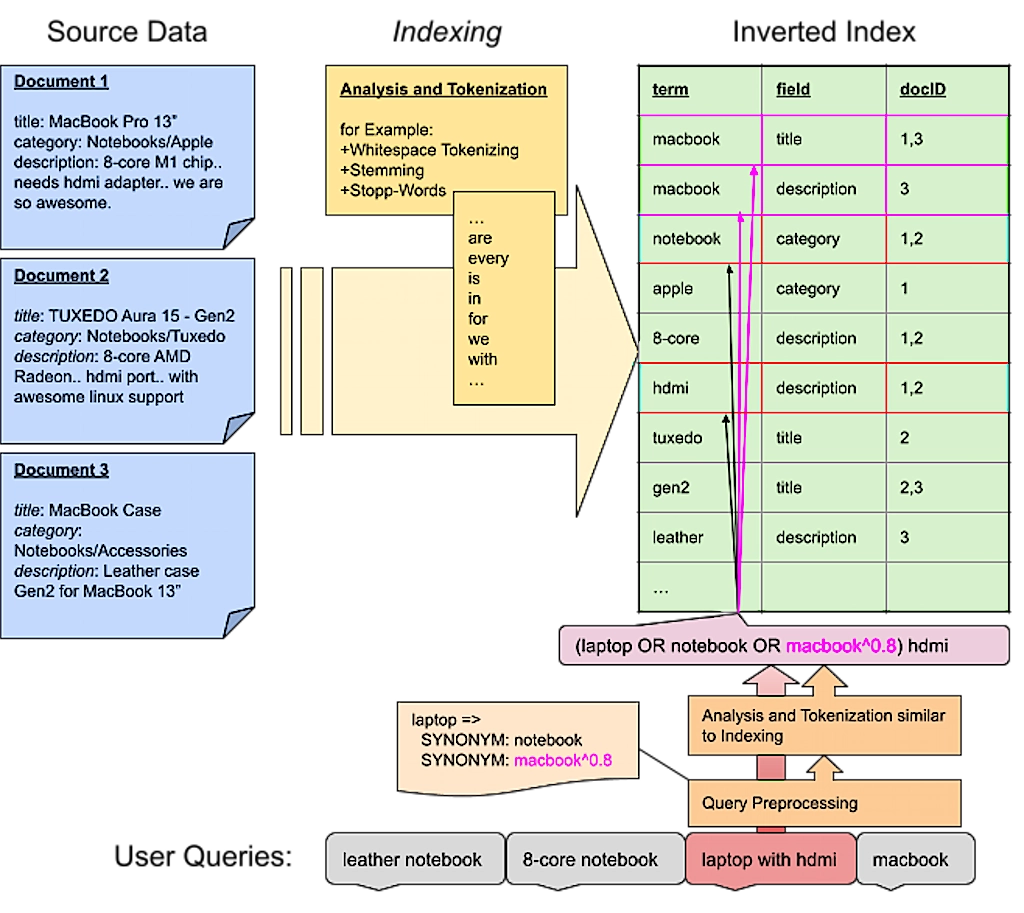
In a nutshell the big challenge with site search, or the area of Information Retrieval more generally, is mapping user input to existing data.
The most common approach is term matching. The basic idea is to split text into small, easy-to-manage pieces or “terms”. This process is called “tokenization”. Eventually these terms are transformed using “analyzers” and “filters”, in a process known as “analyzing”. Finally, this process is applied to the source data during “indexing” and the results are stored in an “inverted index”. This index stores the relationship of the newly produced terms to the fields and the documents they appear in.
This same processing is done for every incoming user query. Newly produced terms are looked up in an inverted index and the corresponding document ids become the queries’ result set. Of course this is a simplified picture, but it helps to understand the basic idea. Under the hood, considerably more effort is necessary in order to support partial matches, get proper relevance calculation etc.
Be aware that, in addition to everything described above, rules too must be applied during query preprocessing. The following visualization illustrates the relationship and impact of synonyms on query matching.
Term matching is also the approach of Lucene – the core used inside Elasticsearch and Solr. On that note: most search-engines work this way, though many new approaches are gaining acceptance across the market.
A Rough Outline of Site Search Problems
Term matching seems rather trivial if the terms match exactly: The user searches for “notebook” and gets all products that contain the term “notebook”. If you’re lucky, all these products are relevant for the user.
However, in most cases, the user – or rather we, as the ones who built search and are interested in providing excellent user experiences – is not so lucky. Let’s classify some problems that arise with that approach and how to fix them.
Unmitigated order turns to chaos
What is Term Mismatch?
In my opinion, this is the most common problem: One or more terms the user entered aren’t used in the data. For example the user searches for “laptop” but the relevant products within the data are titled “notebook”.
This is solved easily by creating a “synonym” rewrite rule. This is how that rule looks in Querqy:
laptop =>
SYNONYM: notebook
With that rule in place, each search for “laptop” will also search for “notebook”. Additionally, a search for “laptop case” is handled accordingly so the search will also find “notebook case”. You can also apply a weight to your synonym. This is useful when other terms are also found and you want to rank them lower:
laptop =>
SYNONYM: notebook
SYNONYM: macbook^0.8
Another special case of term mismatching are numeric attributes: users search for ‘13 inch notebook’ but some of the relevant products, for example, might have the attribute set to a value of ‘13.5’. Querqy helps with rules that make it easy to apply filter ranges and even normalize numeric attributes. For example, by recalculating inches into centimeters, in case there are product attributes that are searched in both units. Check out the documentation of the “Number Unit Rewriter” for detailed and good examples.
However there are several cases where such rules won’t fix the problem:
In the event the user makes a typo: the rule no longer matches.
In the event the user searches for the plural spelling “notebooks”: the rule no longer applies, unless an additional stemming filter is used prior to matching.
The terms might match irrelevant products, like accessories or even other products using those same terms (e.g. the “paper notebook” or “macbook case”)
With searchHub preprocessing, we ensure user input is corrected before applying Querqy matching rules. At least this way the first two problems are mitigated.
How to Deal with Non-Specific Product Data?
The “term mismatch problem” is worse, if the products have no explicit name. Assume all notebooks are classified only by their brand and model names. For example: “Surface Go 12”, and put together with accessories and other product-types into a “computers & notebooks” category.
First of all some analysis needs to stem the plural term “notebooks” to “notebook” in the data and also in potential queries. This is something your search engine has to support. An alternative approach is to just search fuzzily through all the data, making it easier to match such minor differences. However, this may lead to other problems, for example not all stems have a low edit distance (e.g. cacti/cactus). Or yet another issue: other similar but unrelated words might match (shirts/shorts). More about that below, when I talk about typos.
Nevertheless, a considerable amount of irrelevant products will still match. Even ranking can’t help you here. You see, with ranking you’re not just concerned with relevance, but mostly looking for the greatest possible impact of your business rules. The only solution within Querqy is to add granular filters for that specific query:
First of all this “rule set” only applies to the exact query “notebook”. That’s what the quotes signify.
The synonym rules also include matches for “macbook” and “surface” in descending order.
Then we use filters to ensure only mid to high price products are shown excluding those with “pc” in the title field.
Noticeably, such rules get really complicated. Oftentimes there are products that can’t be matched at all. And what’s more: rules only fix the search for a specific query. Even if searchHub could handle all the typos etc. a shop with such bad data quality will never escape manual rule hell.
This makes the solution obvious: fix your data quality! Categories and product names are the most important data for term-matching search:
Categories should not contain combinations of words. Or if they do, don’t use such categories for searching. Also at least the final category level should name the “things” it contains (use “Microsoft Notebooks” instead of a category hierarchy “Notebook” > “Microsoft”) Also be as specific as possible (use “computer accessories” instead of “accessories”, or even “mice” and “keyboards”).
Similar for product names: they should contain the most specific product type possible and attributes that only matter for that product.
searchHub’s analysis tool “SearchInsights” helps by analyzing which terms are searched most often and which attributes are relevant for associated product types.
How to Deal with Typos
The problem is obvious: User queries with typos need a more tenable solution. Correcting them all with rules would actually be insane. However, handling prominent typos or “alternative spellings” using Querqy’s “Replace Rewriter” still might make sense. Querqy has a minimalistic syntax easily allowing the configuration of lots of rules. It also allows substring correction using a simple wildcard syntax.
Example rule file:
leggins; legins; legings => leggings
tshirt; t shirt => t-shirt
Luckily, all search engines support some sort of fuzzy matching as well. Most of them use a variation of the “Edit Distance” algorithm that accepts a match of another term if only one or two characters differ. Nevertheless fuzzy matching is also mismatch prone. Even more so if used for every incoming term. For example, depending on the algorithm used, “shirts” and “shorts” have a low edit distance to each other but mean different things.
For this reason Elasticsearch offers the option to limit the maximum edit distance based on query length. This means, no fuzzy search will be initiated for short terms due to their propensity for fuzzy mismatches. Our project OCSS (Open Commerce Search Stack) moves fuzzy search to a later stage during query relaxation. This means we first try exact and stemmed terms, and only if there are no matches do we use fuzzy search. Also running spell-correction in parallel fixes typos in single words of a multi-term query. (some details are described in this post)
With searchHub we use extensive algorithms to achieve greater precision for potential misspellings. We calculate them once, then store the results for significantly faster real-time correction.
Unfortunately, if there are typos in the product data the problem gets awkward. In these cases, the correctly spelled queries won’t find potentially relevant products. Even if such typos can consistently be fixed, the hardest part is detecting which products weren’t found. Feel free to contact us if you need help with this!
Cross-field Matches
Best case scenario: users search for “things”. These are terms that name the searched items, for example “backpack” instead of “outdoor supplies”. Such specific terms are mostly found in the product title. If the data is formatted well, most queries can be matched to the product’s titles. But if the user searches more generic terms or adds more context to the query, things might get difficult.
Normally, a search index is set up to search in all available data fields, e.g. titles, categories, attributes and even long descriptions – which often have quite noisy data. Of course matches in those fields must be scored differently, nevertheless it happens that terms do get matched in the descriptions of irrelevant products. For example, the term “dress” can be part of many description texts for accessory products, that describe how good they might be combined with your next “dress”.
With Querqy you can set up rules for single terms and restrict them to a certain data field. That way you can avoid such matches:
Example rule file:
dress =>
FILTER: * title:dress
But you should also be careful with such rules, since they would also match for multi-term queries like “shoes for my dress”. Here query understanding is key to mapping queries to the proper data terms. More about this below under “Terms in Context”.
Structures require supreme organization
Decomposition
This problem arises mostly for several European languages, like Dutch, Swedish, Norwegian, German etc. where words can be combined for new, mostly more specific words. For example the German word “federkernmatratze” (box spring mattress) is a composite of the words “feder” (spring), “kern” (core/inner) and “matratze” (mattress).
First problem with compound words: There are no specific rules about how words can be combined and what that means for semantics, only that the last word in a series determines the “subject” classification. Is a compound word made of many words, then each word in the series needs to be placed before the “subject” which always has to appear at the end.
The following German example makes this clear: “rinderschnitzel” is a “schnitzel” made of beef (Rinder=Beef – meaning that it’s a beef schnitzel) but a “putenschnitzel” is a schnitzel made of turkey (puten=turkeys). Here the semantics come from the implicit context. And you can even say “rinderputenschnitzel” meaning a turkey schnitzel with beef. But you wouldn’t say “putenrinderschnitzel” because the partial compound word “putenrinder” would mean “beef of a turkey” – no one says that. 🙂
By the way, that concept or even some of those words have swapped over into English. For example: “kindergarden” or “basketball”, however in German, for many generic compound words, it’s possible to also use the words separately: “Damenkleid” (women’s dress) can also be named “Kleid für Damen” (dress for women).
The impending problem with these types of words is bidirectional though: these cases exist both inside the data, and come from users searching for them. Let’s distinguish between the two cases:
The Problem When Users Enter Compound Words
The problem occurs when the user searches for the compound word but the relevant products contain the single words. In English that doesn’t make sense (e.g. no product title would have “basket-ball” written separately. In German however the query “damenschuhe” (women’s shoes) must also match “schuhe” (“shoes”) in the category “damen” (“women”) or “schuhe für damen” (shoes for women).
Querqy’s “Word Break Rewriter” is good for such cases. It uses your indexed data as a dictionary to split up compound words. You can even control it by defining a specific data field as a dictionary. This can either be a field with known precise and good data or a field that you artificially fill with proper data.
In the slightly different case where the user searches for the decompounded version (“comfort mattress”) and the data contains the compound word (“comfortmattress”) Querqy helps with the “Shingle Rewriter”. It simply takes adjacent words and combines the terms. These are called “shingles”. It’s then possible to match them optionally in the data as well. A query could look like this:
If decompounding with tools like Wordbreak fails, you’re left with only one option: rewrite such queries. For this use case Querqy’s “Replace Rewriter” was developed. However, because searchHub picks the spelling with the better KPIs: like queries with low exitRates or high clickRates, we solve such problems automatically.
Dealing with Compound Words within the Data
Assume “basketball” is the term of the indexed products. Now if a user searches for “ball” he would most likely see the basketball inside the result as well. In this case the decomposition has to take place during indexing in order to have the term “ball” indexed for all the basketball products. This is where neither Querqy nor searchHub can help you (yet). Instead you have to use a decompounder during indexing and make sure to index all decompounded terms with those documents as well.
In both cases however, typos and partial singular/plural words might lead to undesirable results. This is handled automatically with searchHub’s query analysis.
How to Handle Significant Semantic Terms
Terms like “cheap”, “small”, and “bright” most likely won’t match any useful product related terms inside the data. Of course they also have different meanings depending on their context. A “small notebook” means a display size of 10 to 13 inches, while a small shirt means size S.
With Querqy you can specify rules that apply filters depending on the context of such semantic terms.
small notebook =>
FILTER: * screen_size:[10 TO 14]
small shirt =>
FILTER: * size:S
But as you might guess, such rules easily become unmanageable due to thousands of edge cases. As a result, you’ll most likely only run these kinds of rules for your top queries.
Solutions like Semknox try to solve this problem by using a highly complex ontology that understands query context and builds such filters or sortings automatically based on attributes that are indexed within your data.
With searchHub we recommend redirecting users to curated search result pages, where you filter on the relevant facets and even change the sorting. For example: order by price if someone searches for “cheap notebook”.
Terms in Context
A lot of terms have different meanings depending on their context. Like a notebook could be an electronic device or a paper device to take notes. A similar case for the word “mobile”: on its own the user is most likely searching for a smartphone. But in the context of the words “disk”, “notebook” or “home” , completely different things are meant.
Also brands tend to use common words for special products, like the label “orange” from “Hugo Boss”. In a fashion store this might become problematic if someone actually searches for the color “orange” in combination with other terms.
Next, broad queries like “dress” need more context to get more fitting results. For example a search for “standard women’s dresses” should not deliver the same types of results as a search for “dress suit”.
There is no specific problem about it and thus also no specific way to solve it. Just keep it in mind when writing rules. With Querqy you can use quotes on the input query to restrict it to be only for term beginnings, endings or full query matches.
With quotes around the input, the rule only matches the exact query ‘dress’:
"dress" =>
FILTER: * title:dress
With a quote at the beginning of the input, the rule only matches queries starting with ‘dress’:
"dress =>
FILTER: * title:dress
With a quote at the end of the input, the rule only matches queries ending with ‘dress’:
dress" =>
FILTER: * title:dress
Of course this may lead to even more rules, as you strive for more precision to ensure you’re not muddying or restricting your result set. But there’s really no way to prevent it, we’ve seen it in almost every project we’ve been involved: sooner or later the rules get out of control. At some point, there are so many queries with bad results that it makes more sense to delete rules rather than add new ones. The best option is to start fixing the underlying data to avoid “workaround rules” as much as possible.
Gears improperly placed limit motion.
Conclusion
At first glance, term matching is easy. But language is difficult. And this post merely scratches the surface of it. Querqy, with all the different rule possibilities, helps you handle special cases. searchHub locates the most important issues with “SearchInsights”. It also helps reduce the amount of rules and increase the impact of the few rules you do build.
tl;dr – Increasing search revenue by +10% from day one!*
If you are responsible for site search, you understand the strategic significance of this “small” yet important element for your online store. No place is this more visible than in bottom line conversion statistics. It would be remiss to disregard the disproportionately high rate of conversion from users who have in some way interacted with the site search. Conversion rates three to five times higher than sales via site navigation are not trivial. However, maintaining the search, monitoring the top search terms and zero hits is a Sisyphean task.
A “Longtail”
What Are Longtail Queries?
These types of queries sit somewhere between the top100 search terms and the zero result queries.
It’s no surprise that most search managers are happy when at least their top100 searches perform optimally. The unfathomable scale of site search longtail, dissuades even the most hardened ecommerce professional from touching it with a 10 foot pole.
However, the search terms that make up ecommerce longtail, account for the motherload of all search queries. Yep… over 90% of all queries entered on ecommerce retail sites fall into this longtail category. Understandably, they usually don’t get any attention. And that’s no fault of the search managers. It’s already damned near impossible to ever feel like you’ve adequately optimized your top100. But it’s bloody mind-boggling to even glance at the list of longtail keywords. Let alone consider optimizing them. There’s simply that many.
Human and AI Collaboration
Manual Site Search Optimization is Impractical
It goes without saying that in everyday life, no human has the time to deal with all search queries. Oftentimes, the day has barely enough hours to do little more than a quick “once over” the zero results. If all goes well, you might be awarded the luxury of squeezing in the top50 to top200, give them a high-level analysis, check whether the results are, relatively, good and proof the KPIs.
This modus operandi has a catch: you never can, confidently, say that the search is optimized. Especially, considering the vastness of the longtail! We have customers with searchhub clusters exceeding 1,000 different spellings for a single search term! Manually attempting to manage scale of these proportions is clearly unthinkable.
That’s where searchhub plays a critical role.
We created a one-of-a-kind AI to analyze the search history stuff referenced above. Now, we can easily answer common questions that we encounter among customers across every flavor of site search:
Which terms are being searched, in all their conceivable, and inconceivable variations? To get this, we had to measure the importance of each minute KPI that in some way has to do with site search.
How do shop visitors behave after searching for a particular keyword or any of its variants – tracking of anonymous customer behavior?
What would it look like if I had a knowledge base with clusters of similar search terms that I could enrich with external data sources (e.g. product data).
How Is Searchhub Different From a Site Search Vendor?
The struggle to answer these questions led us to a unique solution. searchhub’s AI takes queries that lead to similar product purchases, and merges them together into clusters. For each cluster a so-called Master Query is defined. We get this by analyzing the KPIs of the individual search terms within a cluster further.
How Does Searchhub Pick a Master Query?
KPIs important for Master Query selection include:
were there results?
how many results were shown?
was there interaction with the search result?
what was the quality of the interaction?
was something added to the cart post interaction?
was something purchased?
Once a Master Query is defined, all other query variations within a cluster are excluded from the search and instead substituted by the master query!
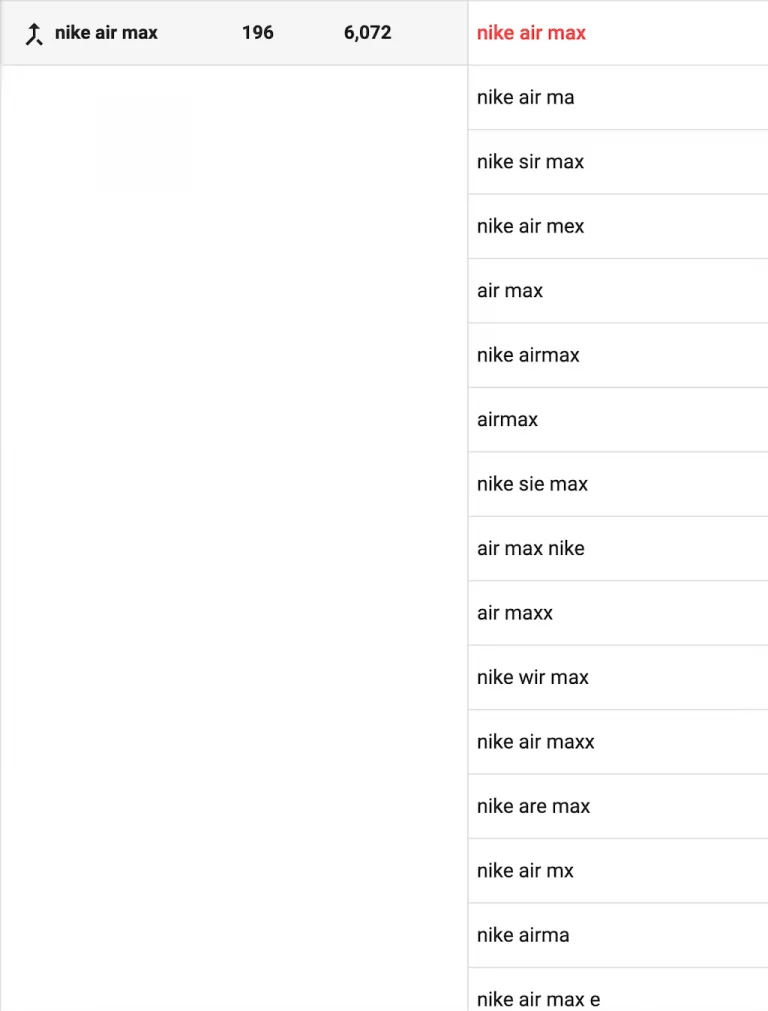
The following is an excerpt from the cluster “nike air max” with 196 different spellings. We would replace all of these with “nike air max”.
Master Query Selection
Not only does this ease the strain of search management by decreasing time spent on search maintenance, but marketing and purchasing also benefit from this clustering!
How Do Marketing And Purchasing Departments Benefit From Search Query Clustering?
Marketing departments invest significant resources into enriching frequent and relevant search terms with redirects, curated results, marketing campaigns, product promotions and product advisors.
To this end, searchhub makes it easy to access rich search journey insights that can be used for targeted SEO actions. searchhub generally increases traffic to these keywords upwards of 20-30%. This is a consequence of more customers being funneled to master query landing pages. This translates into additional value for the colleagues in server side advertising!
Additionally, onsite search suggestions also benefit from query clustering!
Our proprietary tracking not only measures search frequency, but also transparently quantifies any other search KPI and trend. This means we know exactly which products to display from the very first letter your customers type. Naturally, these suggestions are based on our learnings drawn from master query performance.
Our SmartSuggest makes search suggestions more relevant, significantly varying the result-set in the process. This means we are able to put into practice what many search technologies only give lip service to:
“We deliver a window into the product assortment!” — Andreas Wagner (CTO searchHub.io)
Positive Effects of Query Clustering
Substituting search terms with the best performing Master Query has several positive effects depending on the site search you use. Below are some examples.
“My shop uses SolR / Elastic – what advantages do we have by using searchhub?”
Site search Maintenance interface for non-IT people
UI for configuring the Suggest feature
Create and maintain synonyms through the UI
Use Full Potential of Search Analytics
“We use Attraqt, Algolia, FACT-Finder, Findologic, etc. – what advantages do we have by using searchhub?”
significantly less maintenance effort
better overview of queries, search quality and KPIs
new and existing campaigns, landing pages, curations and advisors receive more traffic.
Irrespective of your site search engine the following points are globally relevant.
SIGNIFICANTLY better error tolerance with higher precision
Cost reduction due to superior and faster maintenance
More and flexible reporting functions
Patented findability score that determines to which degree customers are able to use on site search to find and purchase products easily on your website.
Search analytics that filters queries made by bots vs. humans!
Product data quality optimization through transparent analyses of search intent.
searchhub Business FAQs
Does the above sound exciting? Then let’s dive into the really important questions:
What does searchhub cost?
How long does searchhub integration take?
What do I gain from searchhub?
What does searchhub cost?
Unlike many solutions, our pricing is not based on page impressions, search queries or similar traffic indicators.
searchhub pricing follows these two guidelines:
Which business KPIs (e.g. revenue, CR, CTR, value per search) are crucial for our customer in evaluating the success of search?
and
How high is the potential impact of searchhub?
During the sales process, we create an analysis of a shop’s individual uplift potential with searchhub. This analysis uses your site search data, to illustrate the expected added value based on the clusters searchhub will generate.
This allows us to create an equitable value-added offer for all our customers. The monthly fee is then fixed, with no risk of increase over 12, 24, or 36 months.
What do I gain from searchHub?
“With searchhub, we increased the value per session ad-hoc by more than 20%.”
searchhub improves business KPIs of your entire search longtail.
Higher ClickThroughRatios
fewer zero result hits and
higher conversion rates are the result.
This is why all our customers have a speedy return on investment!
Interested? Contact us at hello@searchhub.io we’ll set you up with your own demo!
*A/B-Tests have shown that CXP searchhub significantly increased our search driven revenue by more than 10% from day one.” Bernd Koch, Baldur Garten
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.