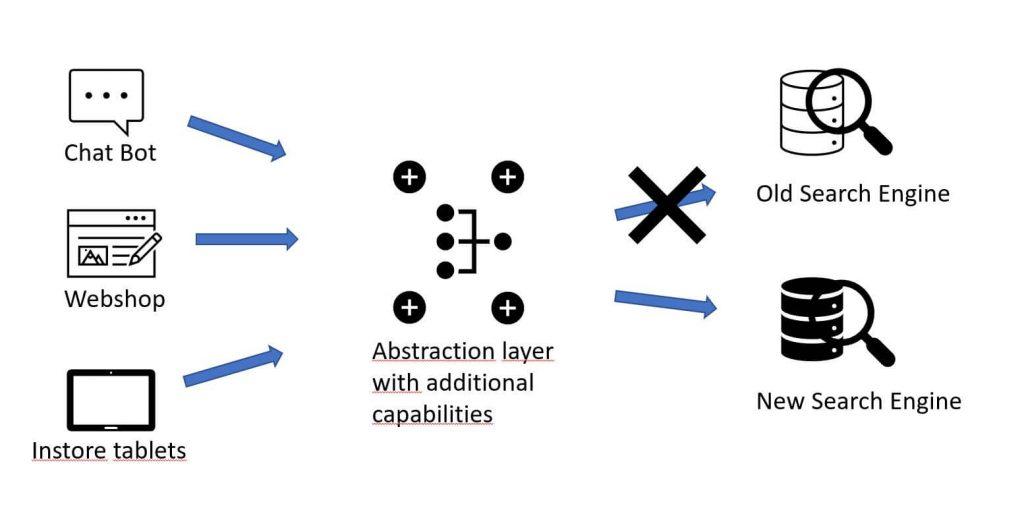
It’s not just politics that will be exciting this year. Changes are also on the horizon for e-commerce. The evaluation of an optimal e-commerce site search overhaul – make or buy a solution is quickly becoming a TOP trend in 2021.
But how thorough to prepare an e-commerce search solution overhaul?
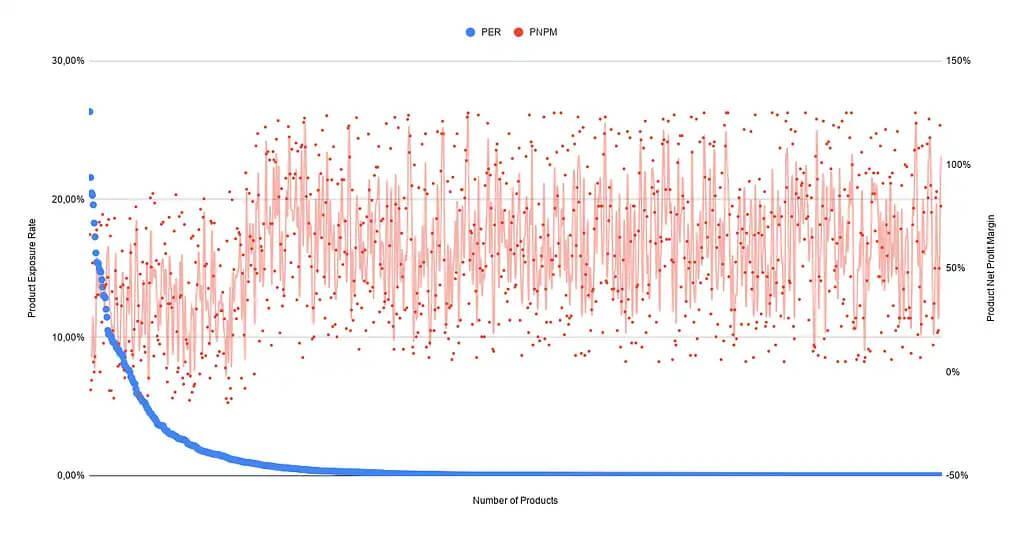
Increasing the economic performance (e.g., CTR, CR) and improving the user experience (e.g., faster loading times, discovery features, and content integration.) Both are issues that undoubtedly concern all e-commerce retailers and will need to be dealt with to prevail against the competition.
Reducing the manual effort required to maintain and control on-site search is an essential task in this regard.
Beyond that, however, some other important questions need to be answered in advance within the organization.
The following is a summary of the most critical points.
E-Commerce Search Overhaul — Make or Buy?

Algorithmic:
How good is the search relevance model in full-text search, semantic correlations, long-tail keywords, languages?
Discovery Features:
How well are topics like complex price & availability dependencies, as well as guided selling and recommendations covered?
Content Integration:
What opportunities exist in terms of the controllable blending of products and promotional content?
Merchandising Features & Analytics:
How well can different sales-promoting strategies (including ranking) be combined with business KPIs and evaluated?
Customization:
How easily are individual requirements implemented?
Intellectual Property:
How can it be ensured that contributed domain knowledge and other forms of intellectual property remain in house?
Deployment Model & Architecture:
How flexible are the deployment model and system architecture?
Integration & Ease of Use:
How apt is the system integration, use, and operation?
Which solution is the right one? Whether a commercial solution (such as Algolia, Attraqt, FACT-Finder, Findologic) or an open-source framework (such as OCSS https://blog.searchhub.io/introducing-open-commerce-search-stack-ocss) — the decision must be well-prepared.

Conditions for the selection of an E-Com on-site search
Before making an informed decision about selecting a new on-site solution/technology, it is vital to understand the implications, dependencies, and scope of such a decision.
The deployment of such a solution quite often influences future business functions and strategic decisions without this being directly apparent in advance. Therefore, I examine the three most important influencing factors in more detail below.
The Influence on corporate strategy:
The core functions responsible for the broader business strategy’s economic success are a natural product of the medium- to long-term corporate strategy.
The answers to the following questions about corporate strategy are particularly relevant when preparing for a vendor selection:
- Is a marketplace game plan a part of the corporate strategy in the next 2-5 years?
- To what extent do diversified local prices and corresponding availability need to be mapped via the on-site search solution?
- How will you divide your focus across customer channels in the mid-term? How will the ratios look?
- Which unique selling points/functionalities provide an anchor for your corporate strategy? Content leadership, expansion of digital advisor functionalities.
- What are midterm geographic growth markets already known?
- Is strategic ownership of core technological competencies and technologies part of the corporate strategy?
- Are there strategic requirements in terms of technological infrastructure (on-premise, private cloud, open cloud)?
- How large is the internal team (professional and technical) available to operate the on-site search?
Influence of the IT architecture
On-site search has to support many core functionalities of a digital enterprise. E-Commerce Search consumes, processes, or makes available for further processing, various data streams. As a result, an agile integration into existing IT-enterprise architecture is elementary for success.
Suppose there is no acknowledgment of these foundational provisions. In that case, marred by lengthy, risky, and costly follow-up projects, subsequent adjustments, or even fundamental changes to the system landscape are often DOA (Dead on Arrival).
In terms of the IT-organization, the answers to the following questions are particularly relevant when preparing a vendor selection:
- Which source and target systems integrations with on-site search currently exist, and which will be considered within the midterm?
- What are the data-security requirements? How often does this data need to be updated?
- Are there defined requirements concerning service-level agreements?
- Are there defined requirements in terms of deployment and infrastructure?
- Should the on-site search system-integration reside exclusively at the data level (headless architecture), or are rendering functionalities must-have requirements?
- From a technical perspective, should the on-site search system also be used as a product API?
- Are there complementary functionalities? For example, recommendation engines, personalization, or guided selling systems that need to be functionally linked or even combined with on-site search?

Influence of operational resources and organization
On-Site Search requires constant maintenance and must react to internal and external factors agily. For this reason, the selection, implementation, and operation of an on-site search is always only part of the solution. On the one hand, the system must be continuously managed and maintained by data-driven external systems (e.g., SearchHub.io) and operational staff with the appropriate domain knowledge.
For the planning of operational resources and team organization, the following questions are essential for the professional selection of an on-site search solution:
- Does a dedicated team of employees already exist to maintain the on-site search manually? If so, how many?
- Does the team have developers, testers, and analysts? If not, is there a plan to expand the team’s skill set in these areas?
- Is the On-Site Search Team organized as a vertical business function in itself? I.e., does the team have all the necessary resources and skills to develop the On-Site Search business function on its own?
Conclusion – E-Commerce Site Search Overhaul:
Strategic internal deliberations significantly influence the evaluation of a new on-site search solution (make or buy). Answering these questions reveals their far-reaching and strategic nature. Naturally, thorough preparation will take time, and all necessary stakeholders will need to arrive at a consensus about the objective. This process leads to greater clarity regarding the next steps. Even if that means the best approach may be to keep the current, well-integrated platform and instead work on mitigating its weaknesses.
There’s More than One Way to Skin a Cat
There are often several ways to fix an on-site search-related deficiency. Resorting to blind action for the hell of it should never be one of them. Regardless of the euphoric high associated with onboarding a new complex piece of kit, if you haven’t done your homework, you’ll inevitably be trading fruit-flies for maggots. Like hoping to exchange your partner for a younger, less judgmental model, if you haven’t come to grips with your own shortcomings, you’re damned to take them with you to the next relationship.

Know When to Hold ‘em, Know When to Fold ‘em
I get it. Every so often, there’s nothing left to salvage. It’s best to cut ties and move on. However, between you and me, there are massive benefits in using software like searchHub to boost an existing system quickly. Furthermore, setting up searchHub affords more forward flexibility. This kind of software runs independently of any search solution. Meaning, you can use the logic you built with us and take it to any other search provider you migrate to in the future.
- Best-case scenario: you turn your current solution into a searchandizing powerhouse.
- Worst-case scenario: you now clearly understand what type of e-commerce search solution your business requires. And because your search-engine logic is not married to your on-site search, you’re able to migrate to a new solution with next to zero downtime.
searchHub.io offers data-driven support and helps optimize existing search applications without making a corresponding system change.