Farewell to 2020! As exciting as it was game-changing, this year too now draws to an end. Like many of us – we at CXP searchHub.io had to adjust to the extraordinary situation. More than one vacation, to faraway lands, boasting paradisiacal beaches, had to be postponed. We found local alternatives instead. Gardens were tended to, apartments and homes painted, or, simply more time spent with family than usual. So what’s next in 2021?
To be true, this Corona Year has galvanized the vocational day-to-day with the historically private family life more than ever. However, what took some getting used to the beginning of March, has revealed new and exciting possibilities.
Nevertheless, the sun is slowly rising on the horizon.
Notable Achievements in This Corona Year 2020
In addition to revenue growth, customer acquisition, and technology development, it’s also important for an E-Commerce Start-Up to attend to remedial tasks like cleaning out the basement; minding the costs; and time for investing in each other. That goes for both inward and outward relationship building.
This was an impressively, successful year for CXP SearchHub. And I’m quite proud of that. Thanks to our team, our customers, and partners.
My Personal Goal Accomplished in 2020
Every year my long-time friends and I meet and hike for a week. This year, due to the Corona situation, we stayed in our local area and walked from Freiburg to Lake Constance. A wild and fun hike for almost 180 km. And we never once got lost. In fact, the only thing I lost was a few kilos. 

180 km hike with my best mates.
SearchHub Software Expansion
We reached our goals alright. Yeah, we clearly surpassed them. As an E-Commerce SaaS (Software as a Service) provider, our most decisive KPI (key performance indicator) is ARR (annual recurring revenue). With growth over 50%, we were able to confirm our business focus set, last year, at the end of 2019. As a result, searchHub.io has played a central role in our business strategy for 2020 and will be expanded upon in the coming year 2021.
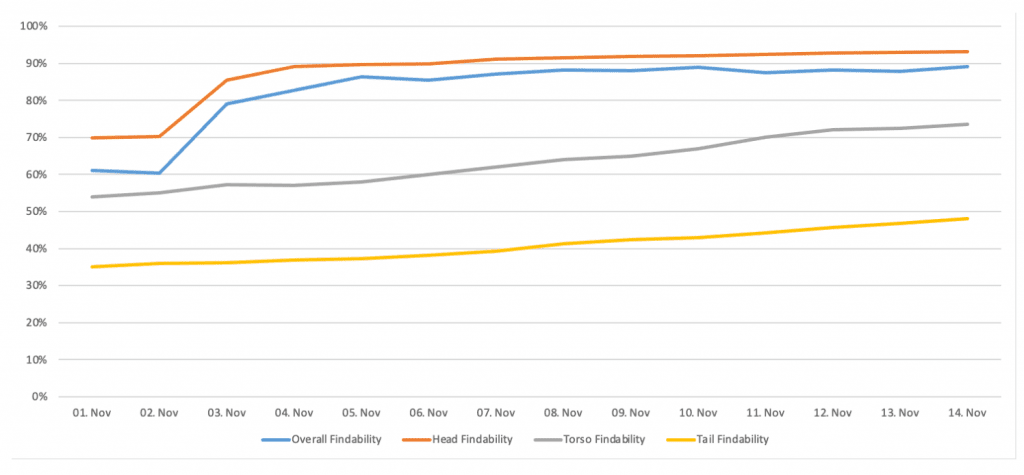
Additionally, as part of searchHub, we also launched our searchInsights tool. This is an overview of all relevant Search KPIs with a first of its kind Findability Score (find out more about this KPI and why it’s important for sustainable search optimization in our blog post here) for daily optimizations and reporting.
New Business Expansion
I’m overjoyed about the many customers who chose to place their trust in our business this year. They play a definitive role in the ongoing success of CXP SearchHub.io. Alongside new customers like Cyberport.de, Steg-Electronics.ch, and INTERSPORT.de, our journey continued with ALL our long-standing customers as well. In addition to all the growth, it’s these of which I’m especially proud. Our long-term, trusted customer relationships are the fuel behind the motivation, innovation, and continued development at CXP. Thank you, for the valuable feedback and insightful ideas.
New Customers in Their Words
searchHub.io enables us to develop our own eCommerce search solution based on Elasticsearch with a data-driven approach. The search experience we deliver to our clients is important for us, and searchHub supports us with their unique expertise in this area.
Malte Polzin, CEO – STEG Electronics AG
In CXP, we have not only found a technological vendor, but we also gained a partner who actively participates in our daily on-site search optimizations with an incredible depth of experience. The speed at which we connected to searchHub was a sprint, not a marathon, going from 0 to 100 in nothing flat. A short time later, increased revenue was proof of success.
Carsten Schmitz, Chief Digital Officer – INTERSPORT Deutschland e.G.
With CXP searchHub.io, we can guide our customers even more effectively into our product assortment. The intelligent clustering of long-tail search traffic enables us to control our search solution even better. The maintenance effort for search merchandising campaigns has been reduced, and search analytics are even more transparent. With searchHub, we have been able to increase the value per session ad-hoc by more than 20%
Dominik Brackmann, Managing Director – Ecommerce at POCO.de
What’s in Development
With searchHub.io, we were able to release new features every month. In addition to the myriad technological developments within our Clustering-Algorithm, and new integrations (e.g., for Spryker), we have also added redirects, mapping-statistics, search-insights, as well as, an Online-Chat and On-Boarding Videos, to both improve usability and make ramping up with our software easier.
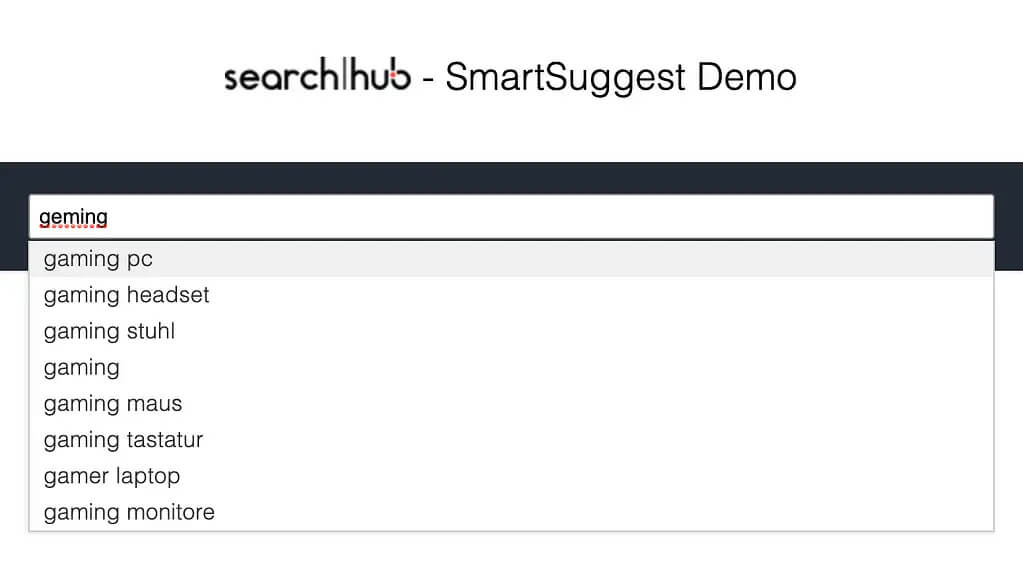
In 2020 SmartSuggest became part of our standard offering
Jonathan Ross, joined our CXP Team this last summer
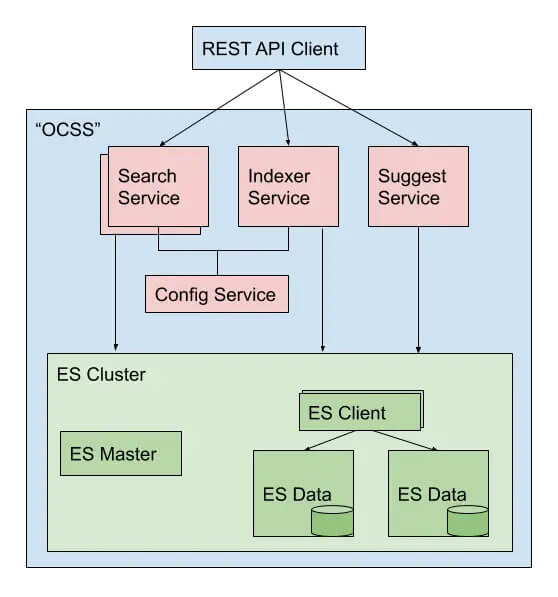
Along with the continued development of our OCSS – “Open Commerce Search Stack” – a special highlight has to be our SmartSuggest. This new technology runs on the same SearchHub knowledge base and is available to every customer as part of our standard offering.
CXP Family Business
There isn’t just one highlight this year. In sum, the entire TEAM is the highlight. But I know you won’t let me off that easy, so…
This year presented us, once again, with the opportunity to take our place at the MICES 2020 – in connection with the Berlin BUZZWORDS AND HAYSTACK! Here’s a link to the lecture from our Andreas Wagner on the topic “Diversification of Search”.
This year also heralded the arrival of Jonathan Ross, whom we gladly welcomed to our team. Jon will continue supporting us in 2021 with his experience of many years.

Covid wasn’t gettin’ us down!

Team Event was moved to September
Gabriel Bauer became our youngest shareholder
A new Shareholder was born. Yet another member of our staff became part-owner of the business. A core tenant of our company philosophy is built on the premise of employee ownership. Since 2014, long-standing employees participate in the success of CXP. This year, we were happy to welcome Gabriel Bauer as the newest shareholder. Discovering our knack for canoeing. It’s on our list for next year. Team Event was moved to September.
A further highlight was most definitively our global Team-Meeting. Time to get to know knew colleagues and old friends. COVID-19 wasn’t gettin’ us down!
Due to Corona, we were forced to reschedule to September, and find a Team-Meeting worthy event, while conforming to all necessary restrictions. What began as kind of a downer for the staff, quickly turned into a sunny, and athletic Team-Event, which strengthened our solidarity for one another. It goes without saying, that we will be repeating this type of event the next chance we get.
What’s On the Horizon?
First off, I hope that everyone makes it, healthily and comfortably into the new year, enjoying time together with their families. Once the lockdown is over, we’ll be starting the year 2021 with a few well-known new customers – more about this later on LinkedIn and here on our blog, just as soon as we can officially say more.
Notwithstanding Brexit, or maybe even as a result of, we are taking our first dip across the pond to set foot on the island this coming year. Together with our new UK consultants, UK customers will soon be able to take advantage of searchHub.
In that vein: our partner ecosystem continues to expand. We’re excited to tell you more about stronger relationships with leading E-Commerce agencies, as well as, 3rd Party Systems. With the development of necessary system interfaces, we are building strong synergies.
And… what kind of SaaS company would we be without technological innovations? We are continuing development on things like “Kihon” – a relevant milestone in our Clustering-Algorithmic or “Structured Queries”. Truly, search has never been more simple.
Stay-Tuned – 2021 will be suspenseful.

Sunsets, like these, are beautiful endings
Last but not least – I’m still hoping to see such a sunset in the year to come 🙂
Merry Christmas, Happy Holidays, and see you soon. Stay positive – test negative 🙏
Sincerely, Mathias & Team CXP searchHub