
Why Vocabulary Mismatch In Ecommerce Site Search Happens
At a high level, E-commerce Search faces two fundamental challenges. The first is the recall challenge: ensuring that all products potentially engaging to a given search intent are retrieved. The second is the precision challenge: ranking and organizing these products in a way that maximizes user engagement. This blog post will focus exclusively on the first challenge, a core problem in ecommerce site search optimization, which we refer to as the vocabulary mismatch.
When shoppers search for “sneakers” but your catalog only lists “athletic shoes”, or when they type “shirt dress” and instead get “dress shirts”, or when they look for “red valentino dress” but only find “valentino red dresses”, search often fails to meet their expectations.
These are just a few examples of one of the most persistent challenges in information retrieval: the language gap (also called vocabulary mismatch), the difference between how customers describe products and how sellers catalog them. It’s a longstanding problem in search, but in e-commerce its consequences are especially tangible:
- Shoppers leave when they see a zero results page.
- Sales are lost when relevant products remain hidden.
- Trust erodes when the site search solution “doesn’t understand” the shopper.
Bridging this gap is therefore a critical opportunity to improve both customer experience and business performance in modern e-commerce platforms.
Vocabulary mismatch in e-commerce has many, often overlapping, causes. Some are obvious, others more subtle, but all contribute to the gap between how shoppers express their intent and product descriptions when it comes to exact matching of words or tokens. A more technical explanation follows.
One of the fundamental technical challenges is token mismatch, where morphological, syntactic, and lexical differences across languages prevent direct alignment between query and document terms. This problem is further compounded by inconsistencies in tokenization schemes, variations in transliteration practices, and the scarcity of high-quality parallel corpora particularly for low-resource languages.
| Morphological differences: | Compound Words Different forms of product-specific compounds: “headphones” vs. “head phones”. Inflections & Lemmas Misspellings & Typos |
| Syntactic differences: | Conceptual Confusions Improving query understanding is key, as queries may express concepts rather than single terms, where word order matters: “shirt dress” vs. “dress shirt”, “table grill” vs. “grill table”. |
| Lexical gaps: | Synonyms & Variants Classic cases like “sofa” vs. “couch” or “TV” vs. “television”. Without handling, these fragment search results. Jargon vs. Everyday Language Regional & Multilingual Differences Evolving Language |
Current State of Vocabulary Mismatch in Ecommerce
We found a considerable amount of literature addressing vocabulary mismatch in e-commerce. However, most of it concentrates on complementary strategies for mitigating the problem rather than on measuring it. Still, the most common approaches are worth noting: query-side, document-side, and semantic search techniques generally provide more precision. Embedding- and vector-based retrieval methods on the other hand, are typically looser and less exact, favoring broader coverage over strict matching.
Query-side Optimization Techniques
- Query Rewriting & Expansion: transform queries into more effective versions. Example: “pregnancy dress” → “maternity dress.”
- Conceptual Search / Semantic Search: Our approach to implementing semantic search interprets the underlying user intent to map queries to the product space.
- Spell Correction: crucial since typos amplify mismatch.
Document-side Optimization Techniques
Document Expansion: enrich product metadata with predicted synonyms or missing tokens. Walmart’s Doc2Token (2024) helped reduce null search results in production.
Attribute Normalization: standardize terms like “XL” vs. “extra large” vs. “plus size.”
Embedding & Vector Search Optimization Techniques
- Vector Search for ecommerce: embeddings (Word2Vec, FastText, transformers) capture semantic similarity beyond surface terms.
- Hybrid Retrieval: combine BM25 (exact matches) with ANN (semantic matches) for balanced recall and precision.
Empirical Measurements & Metrics
| Study | What They Measured | Key Numbers / Findings |
|---|---|---|
| PSimBERT (Flipkart, 2022) | Null-search rate (queries with few or zero results) and recall for “low-recall / short” queries + query expansion with BERT-based methods. sigir-ecom.github.io | Null searches were reduced by ~3.7% after applying PSimBERT query expansion. Recall@30 improved by ~11% over baseline for low-recall queries. sigir-ecom.github.io |
| Addressing Vocabulary Gap (Flipkart / IIT Kharagpur, 2019) | Fraction of queries suffering from vocabulary gap; experiments on rewriting. cse.iitkgp.ac.in | They observe that “a significant fraction of queries” suffer from low overlap between query terms and product catalog specifications. While they don’t always put a precise “% of queries” number for all datasets, they show substantial performance degradation for these queries, and that rewriting helps. cse.iitkgp.ac.in |
| Doc2Token (Walmart, 2024) | How many “missing” tokens are needed in product metadata; what fraction of queries target tokens not present in descriptions. arXiv | The paper describes “novel tokens” (i.e. tokens in queries that aren’t in the product document metadata). They found that document expansion paying attention to those “novel” terms improves search recall & reduces zero-result searches. The exact fraction of missing tokens varies by category, but it’s large enough that, in production A/B tests, the change was statistically significant. arXiv |
| Graph-based Multilingual Retrieval (Lu et al., 2021) | Multilingual and cross-locale query vs product description mismatch; measure improvement by injecting neighbor queries into product representations. ACL Anthology | They report: “outperforms state-of-the-art baselines by more than 25%” in certain multilingual retrieval tasks (across heavy-tail / rare queries) when using their graph convolution networks. This indicates that the vocabulary gap (especially across languages or speech/colloquial vs. catalog language) is large enough that richer models give big gains. ACL Anthology |
But how big is the vocabulary gap?
While many efforts focus on bridging the vocabulary gap with the latest technologies, we found that actually quantifying vocabulary mismatch is far from simple. Its magnitude varies significantly depending on factors such as the domain, catalog size, language, and metadata quality. In fact, we identified only a few studies (cited above) that report meaningful metrics or proxy KPIs. These can indeed serve as useful signals for diagnosing the severity of the problem and for prioritizing improvements. However, they still fall short of capturing the full scale and subtle nuances of the mismatch.
To make well-founded and impactful product development decisions, we need a deep understanding of the vocabulary mismatch problem, its scale as well as its nuances. This is why we invested significant time and resources into conducting a large-scale study on vocabulary mismatch in e-commerce.
Large-Scale Study of Vocabulary Mismatch in E-commerce
Since vocabulary mismatch arises from many sources, our first step was to isolate and measure the individual impact of these causes. We analyzed more than 70M unique products and more than 500M unique queries, filtered according to our top 10 languages (EN,DE,FR,IT,ES,NL,PT,DA,CS,SV).
We initially planned a cross-language meta-analysis, but the analysis phase showed substantial inter-language differences and effect sizes, making pooling inappropriate. We’re therefore analyzing each language separately. We’ll begin with German, since it’s our largest dataset, and integrate the other languages in a later phase. The German dataset consists of 110 million unique queries and 28 million unique products with associated metadata. After tokenizing by spaces and hyphens (where the split yields valid, known tokens), we obtain 132,031,563 unique query tokens and 10,742,336 unique product tokens to work with.
Impact of Misspellings:
Since the primary goal of this analysis is to measure vocabulary mismatch, it is essential to begin by defining what we mean by vocabulary. In this context, vocabulary refers to the set of valid and actually used words or tokens across different languages.
Because auto-correction, the accurate handling of misspelled tokens and phrases, is one of the most frequently applied (and most sophisticated) strategies in searchHub, it is important to first assess the extent of misspellings and exclude them. According to our definition, misspelled terms do not belong to the vocabulary and should therefore be filtered out while quantifying the vocabulary mismatch problem.

shared-token-ratio between search queries and product data across with and without misspellings
Filtering out misspellings reduces the amount of unique query & product-data tokens significantly (almost 7x). After excluding them, we first started with some simple statistics taking our Taxonomy-Nodes into account that revealed that the user query corpus contains on average 4.8x more unique valid tokens than the product corpus. As an important sidenote we should point out that the token imbalance ratio significantly varies across the taxonomy nodes.
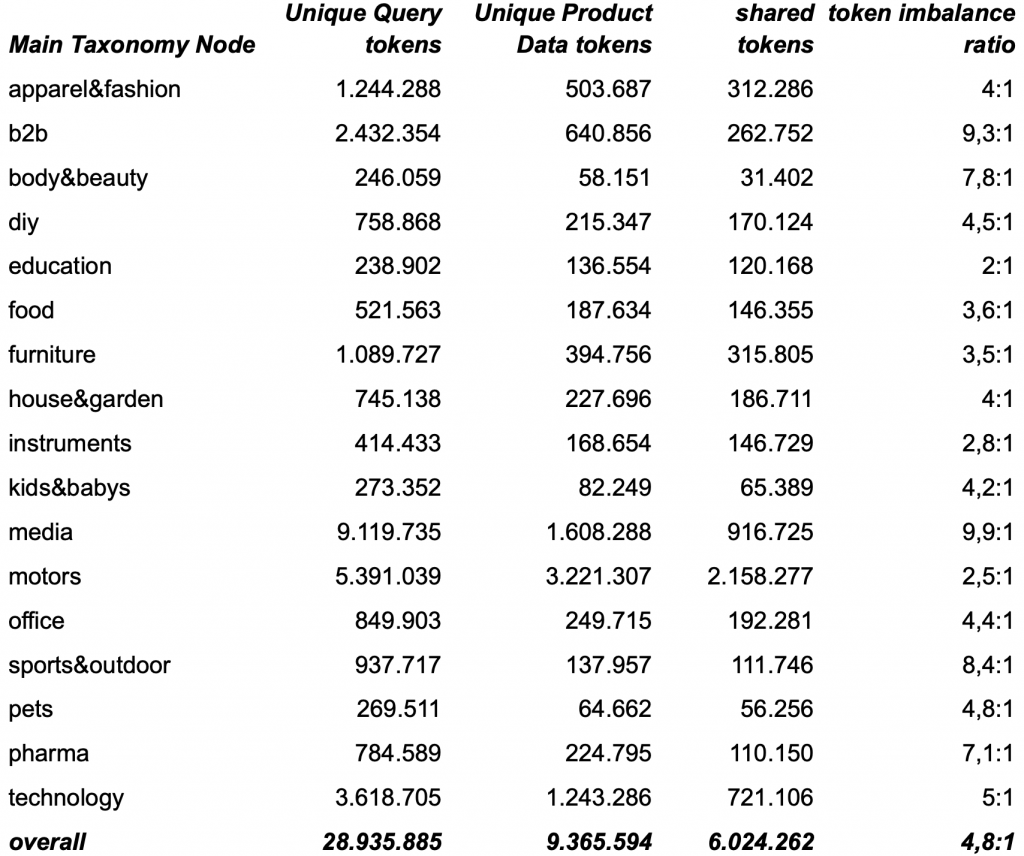
shared-tokens and token imbalance-ratio between search queries and product data across our main taxonomy nodes
It’s important to note that both raw data sets (search queries and product-data) are messy, created mostly through manual input by people with often different domain expertise, and therefore some data cleansing practices like normalization & harmonization have been applied to see if this changes the picture.
Impact of Normalization & Harmonization on morphological differences
At searchHub, our AI-driven site search optimization excels at data normalization and harmonization, which are core strengths alongside spelling-correction. We therefore applied our probabilistic tokenization, word-segmentation, our morphological normalization for inflections and lemmas and our quantities and dimensions normalization for common attributes such as sizes and dimensions, quantities and others. After updating the analysis, the picture already shifted significantly:
Inconsistencies occur on both sides, about ~15% in product data and ~60% in queries. But their nature differs: queries suffer mostly from word segmentation issues, messy numeric normalization, foreign language vocab, and inflections, while product data issues stem mainly from compound words and inconsistent formatting normalization (dimensions, colors, sizes, etc.).
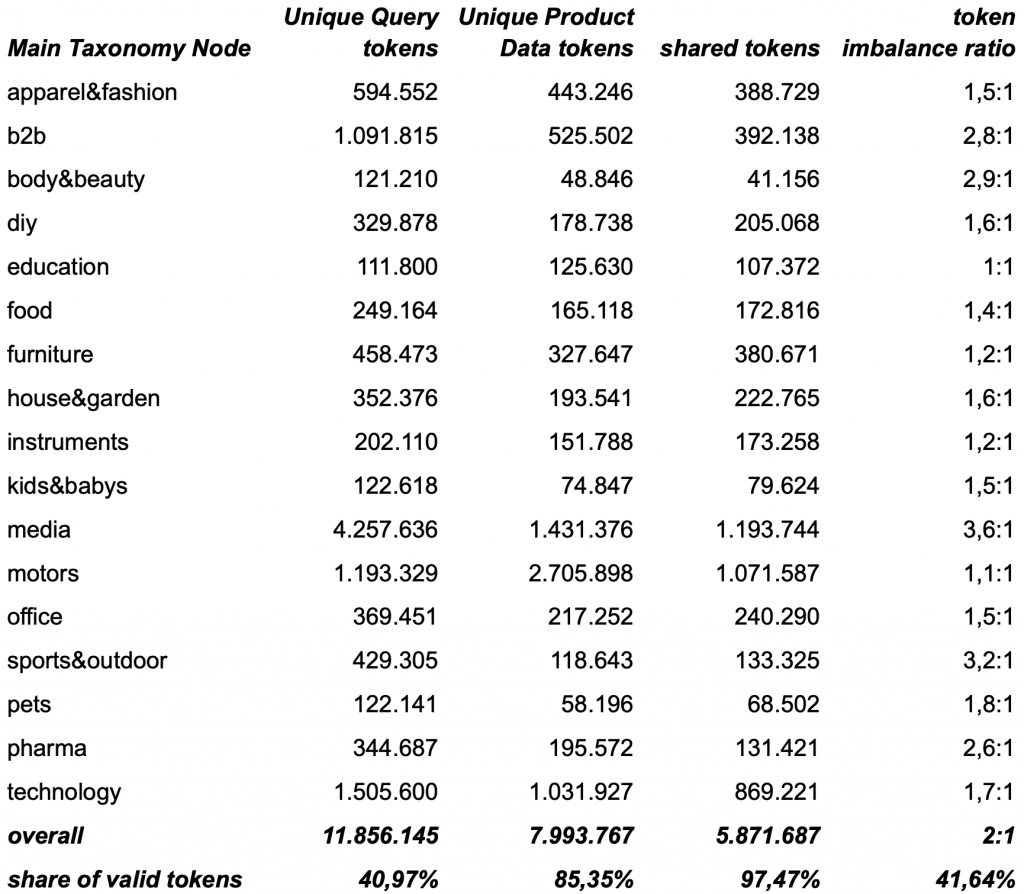
shared-tokens and token imbalance-ratio between search queries and product data across our main taxonomy nodes after normalization and harmonization
After normalization and harmonization the language corpus of queries has been reduced by ~59% while the product data corpus has been reduced by ~15%. It seems that normalization and harmonization reduce the language gap by roughly ~60%, as we have reduced the token imbalance ratio from 4.8:1 to 1.9:1. However looking closely at the table above reveals something interesting. While most taxonomy nodes now have an imbalance ratio of ≤ 2:1, but a subset remains markably skewed. A closer review points to two main drivers:
- foreign-language vocabulary concentrated in Apparel & Fashion, Sports & Outdoors, and Pharma
- rare identifier-like tokens occurring across B2B and Pharma.
Impact of foreign vocab on mismatches in ecommerce search
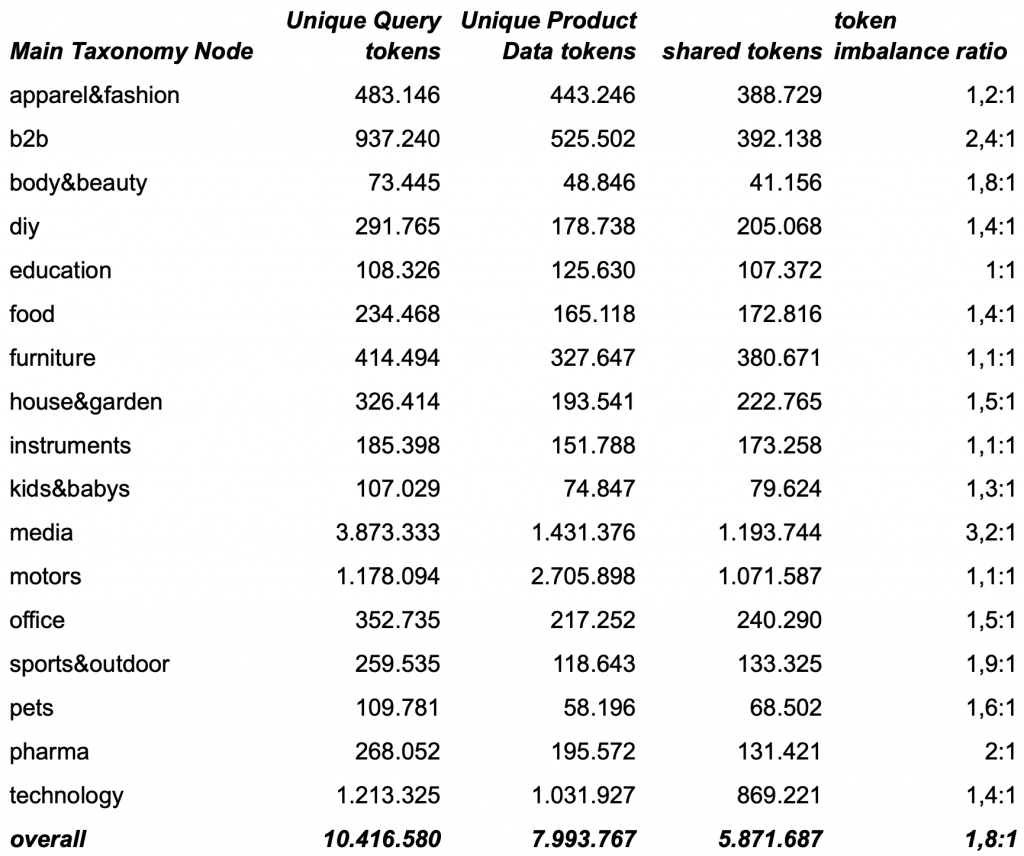
shared-tokens and token imbalance-ratio between search queries and product data across our main taxonomy nodes after removing foreign vocab
Removing the foreign, but known vocabulary reduces the imbalance ratio by roughly another 10%, which is more than we anticipated. But it seems that marketing related vocab like brand names, specific productLine names and product-type jargon play a significant role in some taxonomy nodes (zip-up, base-layer, eau de toilette, ….).
Impact of evolving language and infrequent vocabulary
As a next step we are going to try to quantify the impact of evolving language (vocabulary), focusing on the impact of both newly emerging tokens and very infrequent ones (frequency <2 over one year of data). This step is challenging because it requires distinguishing between genuine new vocabulary and simple misspellings of existing terms which might be the reason why we couldn’t find any generally available numbers about it.
Another strength of our stack is its ability to learn & update vocabularies across languages, customers and segments. That said, like any ML-based approach, it is not flawless. To ensure reliability, we follow a precision-first strategy: for this analysis, we only include cases where the system is ≥99% confident that a token represents valid new vocabulary over a time period of one year, excluding all others.
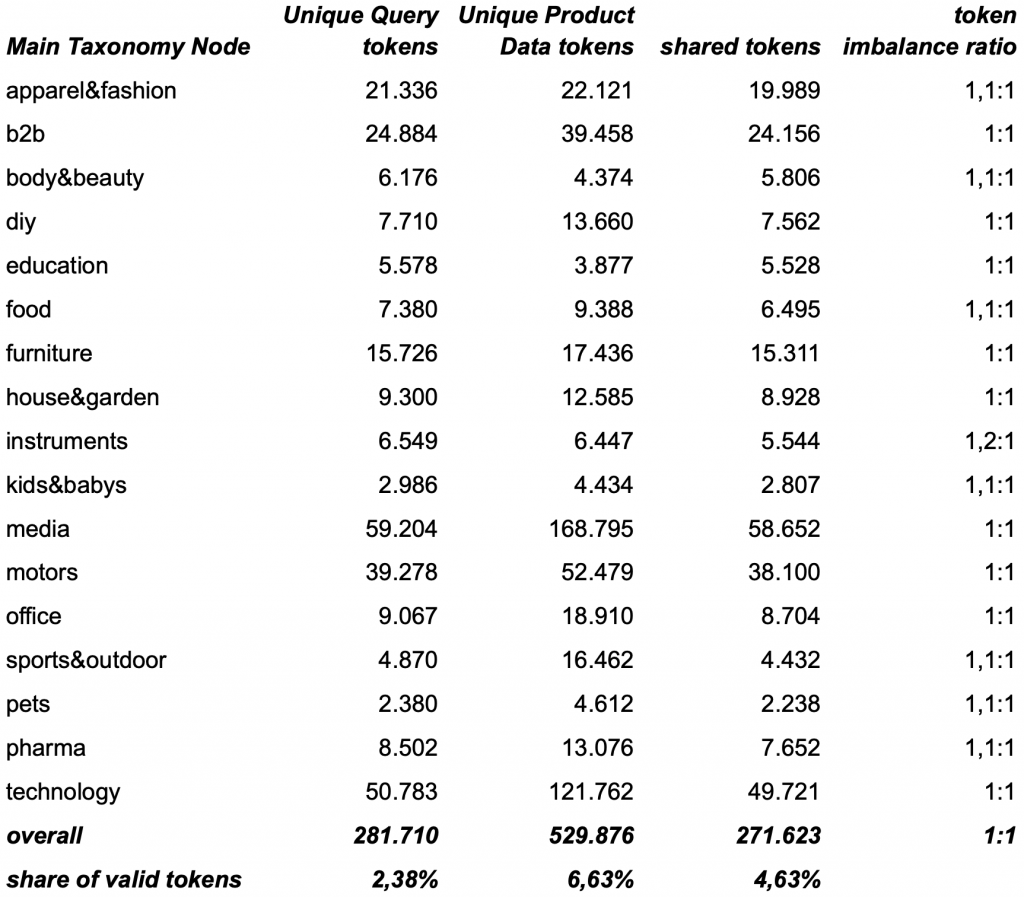
shared-tokens and token imbalance-ratio for new vocabulary between search queries and product data across our main taxonomy nodes
As expected, both sides show a steady influx of new vocabulary. However, the magnitude of change strongly depends on the product type / product segment, represented by the taxonomy node. Some segments exhibit relatively stable vocabularies over time, while others experience frequent shifts and updates. Mentionable types are productLine names, brand names, new trademarks and productModel names, materials, as well as somehow a never ending flow of newly created fashion color names.
Interestingly, nearly 50% of the new vocabulary introduced into the product data over time does not appear to be adopted by users.
The impact of this type of vocabulary gap is not immediately obvious but becomes clearer when viewed longer term. Users often start adopting and using new product vocabulary popularized through marketing campaigns before the corresponding product content is indexed in eCommerce search engines, often due to stock or availability constraints. In many cases, this gap closes naturally once the relevant content is indexed.
Having quantified the effect of new tokens, we can now refine the analysis further by examining the share of infrequent tokens within query logs, where “infrequent” is defined as appearing in fewer than two unique searches over the span of one year.
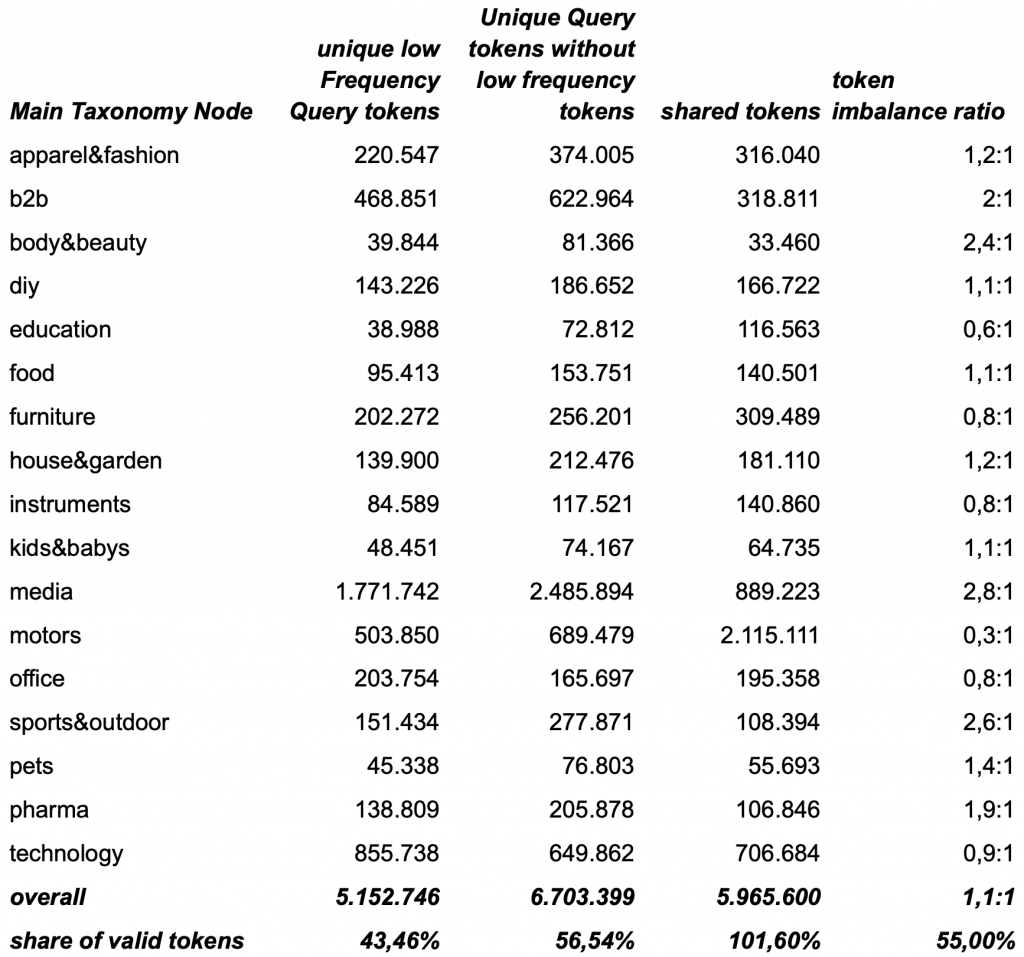
shared-tokens and token imbalance-ratio for search queries with low frequency across our main taxonomy nodes
Surprisingly, a substantial share of valid words or tokens occur very infrequently (frequency ≤ 2) about 43% in queries and 23% in product data. At the same time, it is evident that this further amplifies the vocabulary imbalance between the two sides. Honorable mentions of types in this area are single product company products, product-model names, niche-brands and attribute or use-case specific vocab and tokens containing no useful information.
We specifically wanted to quantify the impact of very infrequent vocab since, to our knowledge, it accounts for most of the problematic or irrelevant search results when applying techniques to close the gap.
Summary:
So far, we have demonstrated scientifically that misspellings and morphological differences down to their major nuances are the most influential factors in closing the language gap. We were able to reduce the token imbalance ratio from 22:1 down to 1.9:1. From there filtering low frequent vocabulary gets us down to 1.1:1.
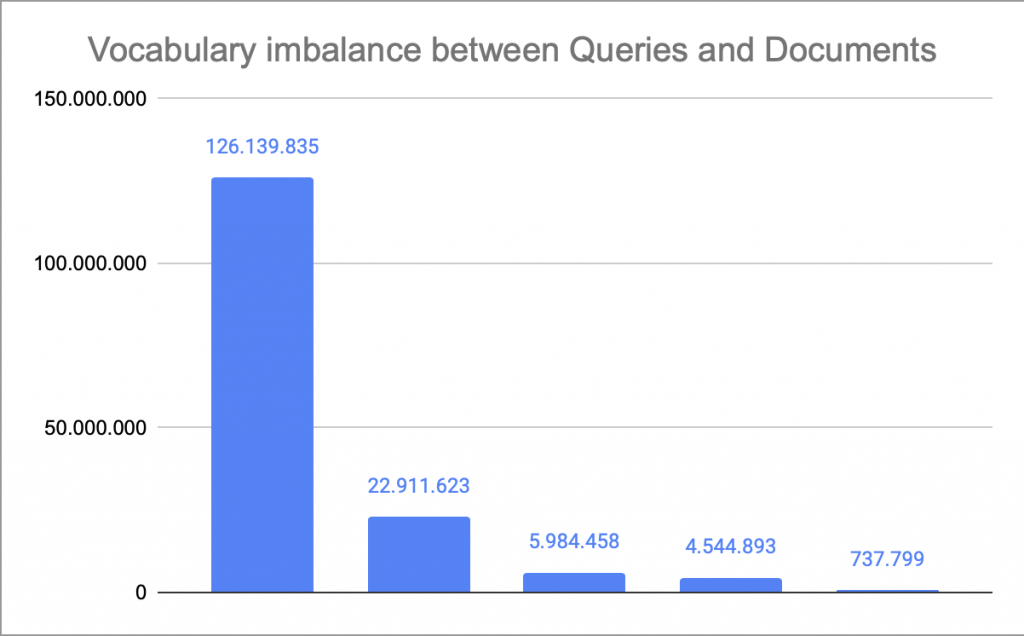
When search traffic (i.e., the number of searches per query) is taken into account, this influence also seems to stay almost equally strong. Our mapping data shows that, depending on the product vertical, effectively handling morphological nuances and being able to detect new vocab alone resolves between 81-86% of the language gap.
Conclusion
The goal is simple: make sure that when customers ask for what they want in their own words they actually find it. And when they do, conversions and customer satisfaction follow.
As shown, vocabulary mismatch remains one of the most stubborn problems, but one that the right e-commerce search best practices can solve. Customers rarely describe products the same way sellers list them. The solution is multi-pronged: query rewriting, document expansion, embeddings, and feedback loops all play a role.
Now that we understand the key drivers and their quantitative impact, we can focus on efficient, effective fixes. Notably, well-tuned, deterministic NLP steps reduced the language gap from 126,139,835 to 4,601,864 tokens (≈97%).
Next, we’ll assess how the impact of syntactic differences and of synonyms/variants distribute over the last 3%, and try to find the best solutions for them. For example, we’ll test whether the remaining gap can be closed by learning from sparse signals (few occurrences) and by leveraging LLMs’ generalization capabilities.
Leave a Reply